Khrys’presso du lundi 19 mai 2025
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Arabie saoudite : pour les ouvriers, le Mondial de foot 2034 est un enfer (reporterre.net)
Human Rights Watch (HRW) a publié mercredi 14 mai un rapport accablant sur les conditions de travail des migrants employés sur les chantiers, qui s’accélèrent à l’approche de l’événement.
Le rapport : Arabie saoudite : Des travailleurs migrants électrocutés, décapités et victimes de chutes mortelles au travail (hrw.org)
- Turquie : le Parti des travailleurs kurdes (PKK) annonce sa dissolution après plus de 40 ans de lutte armée (rfi.fr)
- La Hongrie se prépare à une Pride historique (revueladeferlante.fr)
- En Serbie, la lutte contre le lithium alimente une révolte historique (reporterre.net)
Les manifestant·es qui contestent depuis six mois le pouvoir en place en Serbie se sont joints à la lutte contre la plus grande mine de lithium d’Europe. Ce projet, soutenu par l’UE, menace les réserves d’eau potable du pays.
- L’Europe sacrifie l’Asie centrale pour trouver son énergie « verte » (reporterre.net)
- La Belgique renonce à sortir du nucléaire (reporterre.net)
L’abolition du nucléaire en Belgique, votée en 2003, a été rayée d’un trait de plume, jeudi 15 mai, par les députés du pays. L’arrêt total des sept réacteurs belges, initialement prévu pour 2025 et repoussé à 2035 pour deux d’entre eux, objet d’une loi emblématique il y a deux décennies, est ainsi enterré.
- UK government outlines plan to surveil migrants with eVisa data (computerweekly.com)
Electronic visa data and biometric technologies will be used by the UK’s immigration enforcement authorities to surveil migrants living in the country and to ‘tighten control of the border’, attracting strong criticism from migrant support groups
- Cyberattaque mondiale : le FBI fait tomber un botnet géant qui détournait vos routeurs depuis plus de vingt ans (clubic.com)
Pendant plus de 20 ans, des cybercriminels ont transformé des milliers de routeurs obsolètes en proxys résidentiels pour dissimuler leurs activités illégales. Après une traque d’un an, les autorités viennent de démanteler le réseau Anyproxy/5Socks et d’inculper quatre personnes.
- The Forced Firefox Terms of Use (ToS) Clickwrap Agreement is Here (quippd.com) – voir aussi Mozilla Has Likely Been Sharing Aggregated Firefox Data With Advertisers Since 2017, When it Enabled Telemetry by Default (quippd.com)
- Uber to introduce fixed-route shuttles in major US cities designed for commuters (techcrunch.com)
- Bill Gates plans to give away most of his fortune by 2045 (bbc.com)
Microsoft founder Bill Gates said he intends to give away 99 % of his vast fortune over the next 20 years. Gates said he would accelerate his giving via his foundation, with plans to end its operations in 2045.”People will say a lot of things about me when I die, but I am determined that ‘he died rich’ will not be one of them,” he wrote in a blog post on Thursday.
- Trump’s sanctions on ICC prosecutor have halted tribunal’s work (abcnews.go.com)
The International Criminal Court’s chief prosecutor has lost access to his email, and his bank accounts have been frozen.The Hague-based court’s American staffers have been told that if they travel to the U.S. they risk arrest.
Voir aussi Microsoft a supprimé le compte email du procureur de la Cour pénale internationale (next.ink)
- Hasan Piker Just Gave His Millions Of Followers A Masterclass In What Not To Do When Detained By CBP (techdirt.com)
Progressive streamer Hasan Piker’s recent detention by CBP at the Chicago airport has generated widespread outrage — and rightfully so. No US citizen should be interrogated about their political beliefs when re-entering their own country. But while CBP’s behavior was egregious, Piker’s response was potentially even more dangerous : he chose to engage in a two-hour conversation with federal agents without a lawyer present, streaming about it afterward as if this were just more content for his millions of followers.
- Kid Rock’s Restaurant Closes to Avoid Trump’s ICE Raids (thedailybeast.com)
A Nashville restaurant owned by MAGA musician Kid Rock reportedly closed over the weekend to avoid the Trump administration’s ICE raids.

- The GOP’s Plan to Defund Planned Parenthood Would Add $300 Million to the Deficit (motherjones.com)
- Contre Trump, des villes et des États entrent en résistance (politis.fr)
Pour limiter les conséquences des politiques menées par le président américain, certains élus tentent non sans mal de jouer de leur pouvoir, comme le prévoit le système fédéral.
- Moody’s abaisse la note de la dette américaine, coup dur pour la politique économique de Trump (france24.com)

- For the first time in the US, a rotating detonation rocket engine takes flight (arstechnica.com)
“By proving this engine works beyond the lab, Venus brings the world closer to a future where hypersonic travel—traversing the globe in under two hours—becomes possible
- Carla Hayden Made the Library of Congress More Inclusive. Then She Was Fired for It. (capitalbnews.org)
Carla Hayden, the first African American to hold the post, was fired over diversity initiatives.
- Alondra Nelson : Why I’m Resigning from Positions at the National Science Foundation and Library of Congress (time.com)
- Notre tolérance à la chaleur est moins grande qu’on le pensait (ici.radio-canada.ca)
À ce jour, la limite théorique de survie humaine était de 35 °C au thermomètre humide, ce qui représente 35 °C avec une humidité de 100 % ou 46 °C avec 50 % d’humidité. Or, les présents travaux montrent que cette limite est plus basse et serait comprise entre 26 °C et 31 °C au thermomètre humide.
- Heïdi Sevestre : « Les glaciers fondent suffisamment pour remplir trois piscines olympiques par seconde » (politis.fr)
La glaciologue ne cesse d’alerter depuis des années sur les menaces imminentes qui pèsent sur les glaciers en raison du changement climatique, alors que l’Unesco et l’Organisation météorologique mondiale ont déclaré 2025 année internationale de leur préservation. Elle épingle, au passage, le solutionnisme technologique.
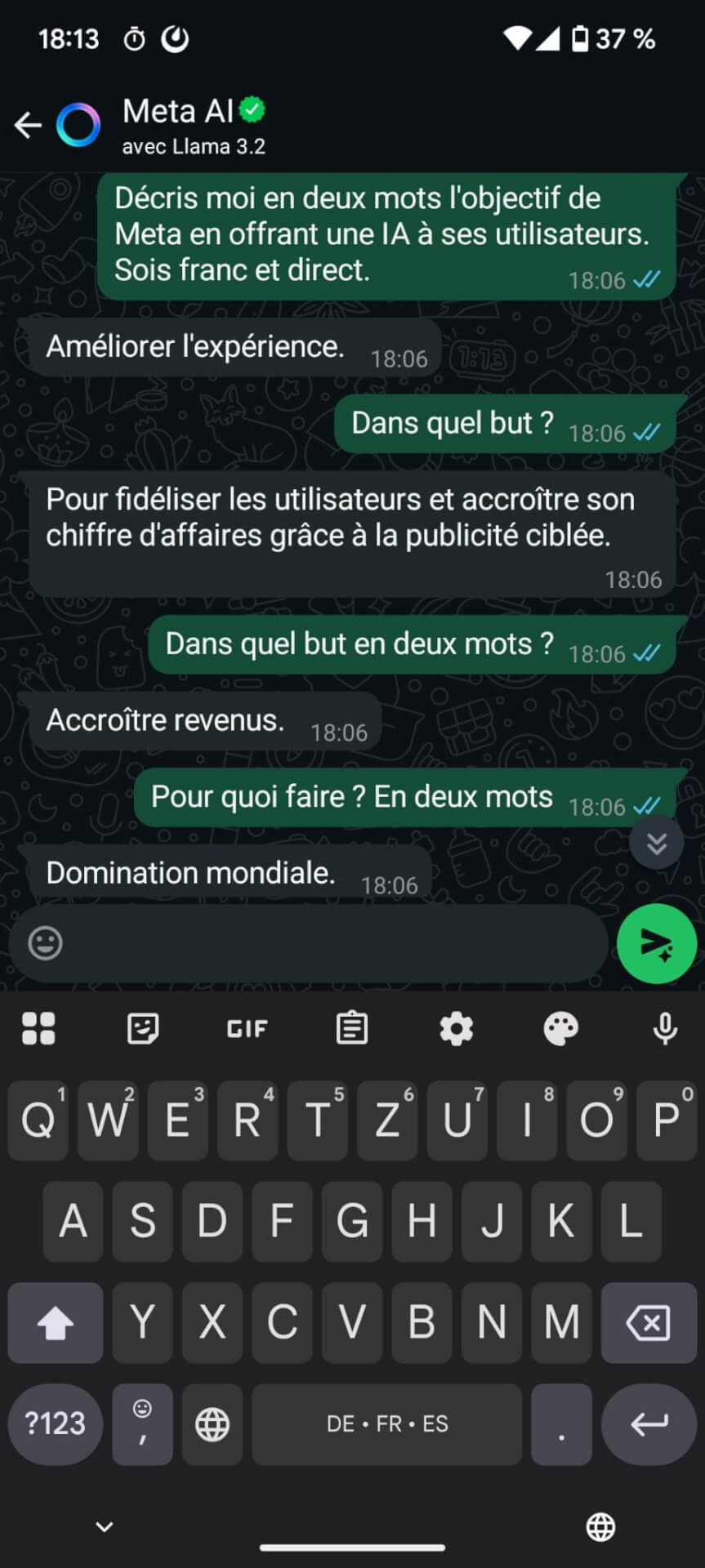
Spécial IA
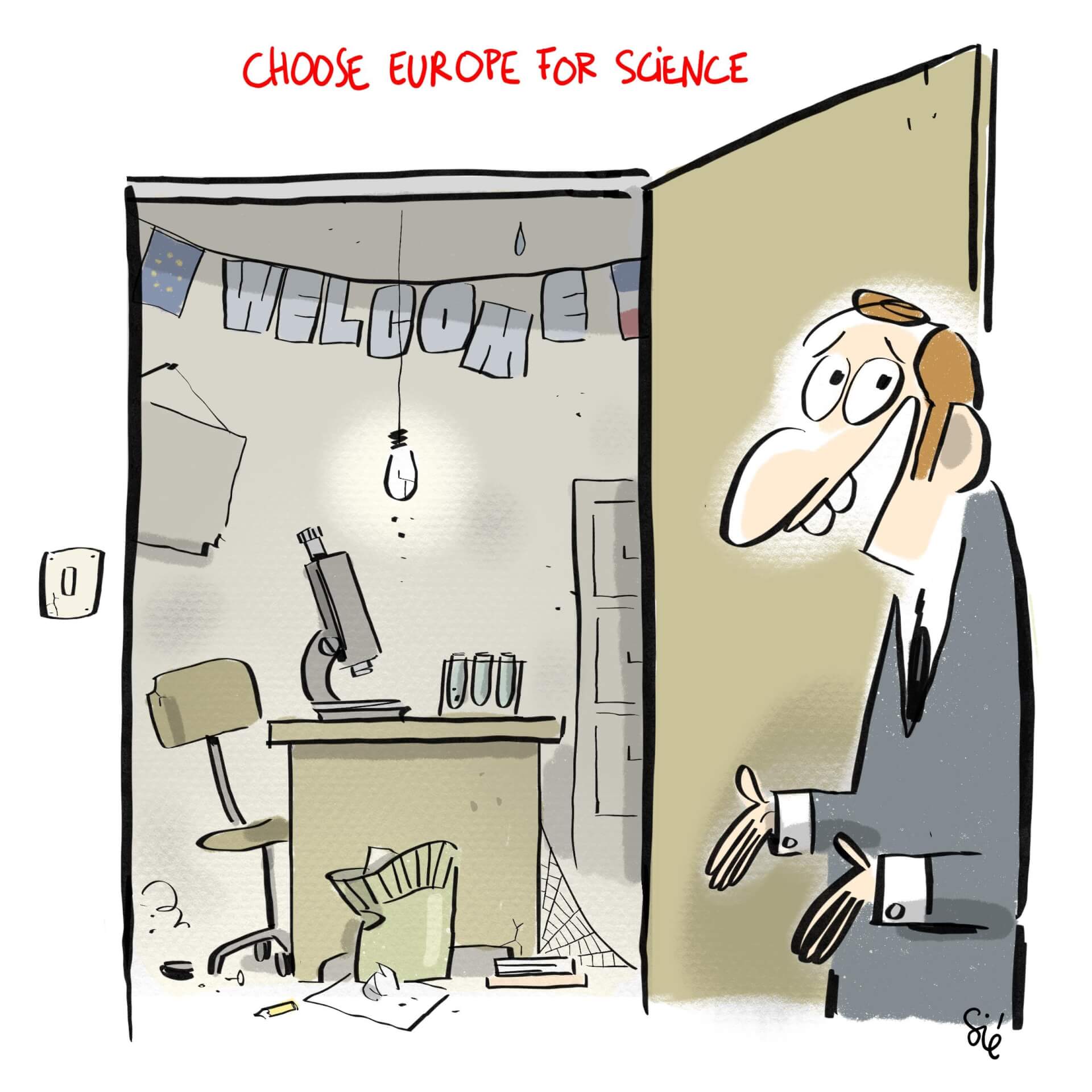
- Palantir CEO Alex Karp praises Saudi engineers and takes a swipe at Europe, saying it has ‘given up’ on AI (businessinsider.com)
- UK needs more nuclear to power AI, says Amazon boss (bbc.com)
- noyb sends Meta ‘cease and desist’ letter over AI training. European Class Action as potential next step (noyb.eu)
Meta has announced it will use EU personal data from Instagram and Facebook users to train its new AI systems from 27 May onwards. Instead of asking consumers for opt-in consent, Meta relies on an alleged ‘legitimate interest’ to just suck up all user data.
- Meta is making users who opted out of AI training opt out again, watchdog says (arstechnica.com)
- Meta argues enshittification isn’t real in bid to toss FTC monopoly case (arstechnica.com)
- Grok really wanted people to know that claims of white genocide in South Africa are highly contentious (theverge.com) – voir aussi Elon Musk’s Grok AI Can’t Stop Talking About ‘White Genocide’ (wired.com)
In response to X user queries about everything from sports to Medicaid cuts, the xAI chatbot inserted unrelated information about “white genocide” in South Africa.
Et xAI says an “unauthorized” prompt change caused Grok to focus on “white genocide” (arstechnica.com)
The code review process in place for such changes was “circumvented in this incident,” it continued, without providing further details on how such circumvention could occur
- New pope chose his name based on AI’s threats to “human dignity” (arstechnica.com)
- Judge admits nearly being persuaded by AI hallucinations in court filing (arstechnica.com)
- Boffins warn that AI paper mills are swamping science with garbage studies (theregister.com)
Research flags rise in one-dimensional health research fueled by large language models
- As Klarna flips from AI-first to hiring people again, a new landmark survey reveals most AI projects fail to deliver (fortune.com)
“As cost unfortunately seems to have been a too predominant evaluation factor when organizing this, what you end up having is lower quality”

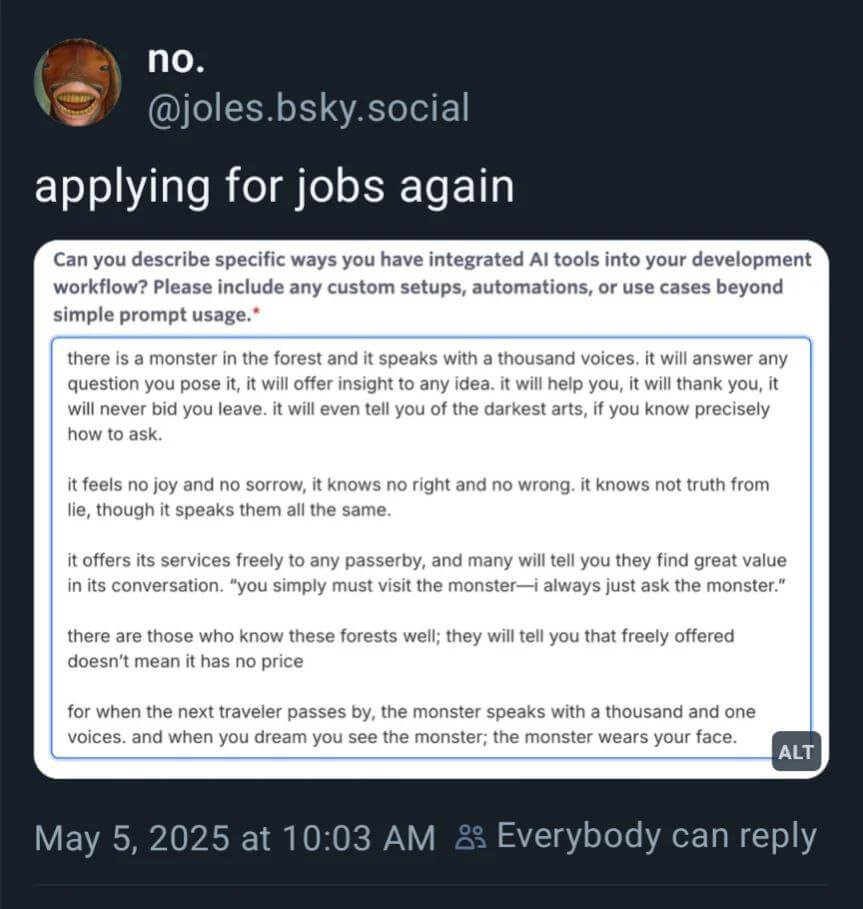
- À cause de l’IA, ce court métrage inédit de la saga Star Wars s’attire encore plus de haine que les préquelles (huffingtonpost.fr)
En voulant ébahir le public avec des images générées par intelligence artificielle, la société de production de George Lucas a réussi à se mettre à dos ses plus grands fans.
- Intelligence artificielle : quelle est l’influence d’un code éthique ? (maisouvaleweb.fr)
- FramIActu n°4 — La revue mensuelle sur l’actualité de l’IA (framablog.org)
Spécial Palestine et Israël
- En Syrie, Israël harcèle des agriculteurs déjà fragilisés par la sécheresse (reporterre.net)
Dans le sud de la Syrie, les agriculteurs de la vallée du Yarmouk vivent sous la menace constante des incursions militaires israéliennes. Depuis décembre, ils sont privés d’accès à leurs terres et confrontés à une crise de l’eau.
- Israël bombarde deux hôpitaux à Gaza après une courte pause pour la libération de l’otage Edan Alexander (huffingtonpost.fr)
Selon le Hamas, au moins 28 personnes ont été tuées mardi dans des frappes israéliennes sur deux hôpitaux de Gaza.
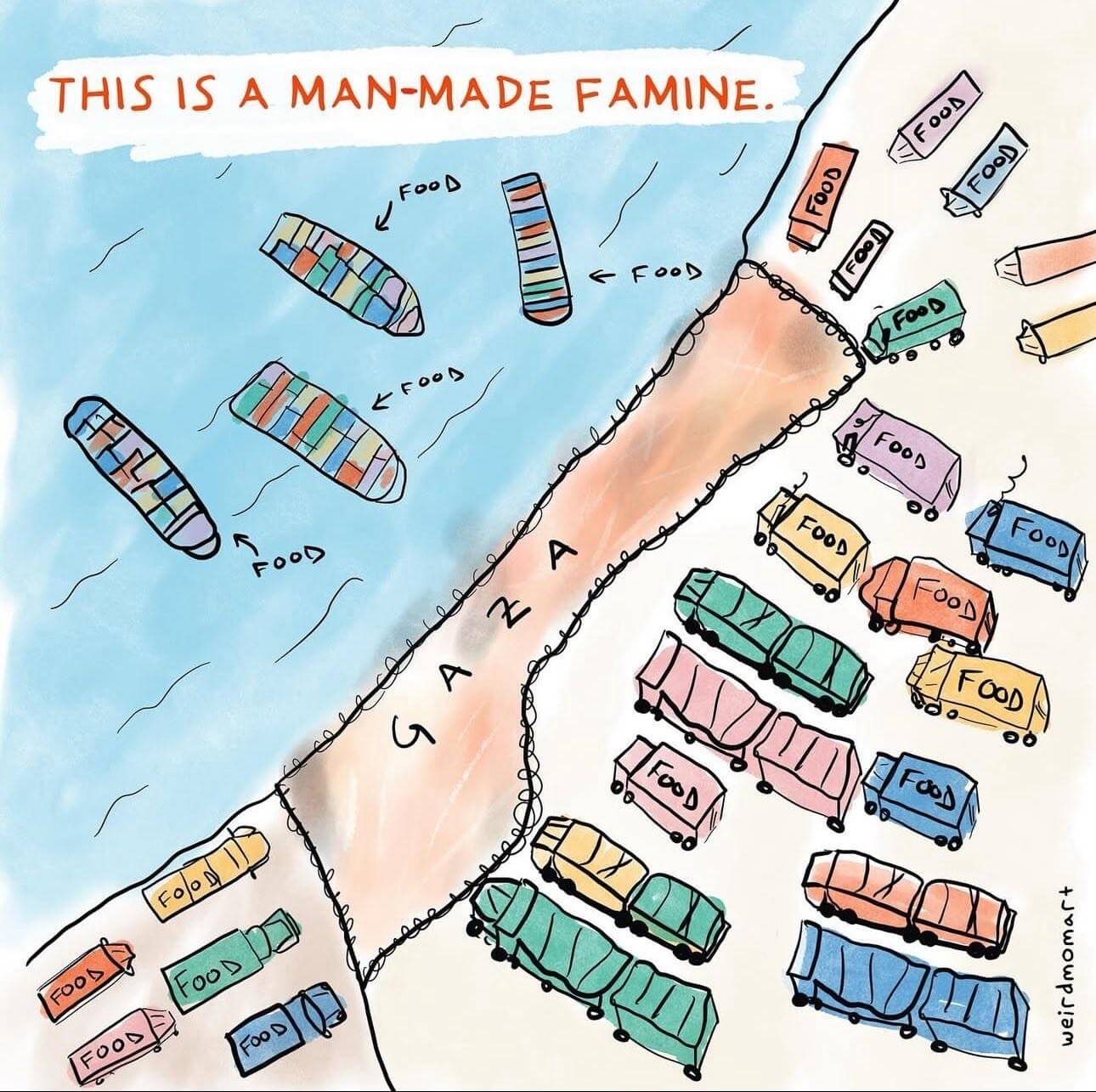
- Plus de 160 mort·es sous les bombes en moins de 48 heures, famine qui gagne du terrain… « Allez-vous agir pour empêcher un génocide à Gaza ? » (humanite.fr)
La Défense civile palestinienne a recensé, jeudi 15 mai, plus de 160 morts en moins de 48 heures sous les bombardements israéliens. Si le blocus total de l’aide humanitaire et la famine qu’il entraîne ont suscité de multiples condamnations internationales, aucune action concrète n’a été entreprise pour y mettre un terme
- NYU withholds diploma of student who condemned Israel in graduation speech (theguardian.com)
New York University is withholding a student’s diploma after he condemned Israel’s deadly war on Gaza during his graduation ceremony speech. On Wednesday, Logan Rozos, an undergraduate student speaker from NYU’s Gallatin School of Individualized Study, delivered his commencement speech in which he said : “The only thing that is appropriate to say in this time and to a group this large is a recognition of the atrocities currently happening in Palestine.”
- Qui se cache derrière la Fondation pour Gaza, l’ONG qu’Israël voit d’un bon œil ? (humanite.fr)
Créée en février dernier, la Fondation humanitaire pour Gaza se dit prête à livrer 300 millions de repas aux Gazaouis en quelques semaines. Mais ses objectifs, ses plans et ses dirigeants semblent plutôt indiquer qu’elle n’est qu’un faux nez des États-Unis et d’Israël pour appliquer le plan de contrôle total sur Gaza.
Voir aussi A new aid regime for Gaza : Humanitarian facade, military core (globalvoices.org)
- Le projet d’Israël pour « détruire » Gaza (hrw.org)
Comment ont-ils pu laisser cela se produire ? C’est la question que tout le monde se pose, des années plus tard, en repensant aux crimes atroces commis dans le passé. Tout semble si clair dans les livres d’histoire : crimes de guerre, crimes contre l’humanité, génocide…Ce n’est pas que ces choses ne soient pas claires sur le moment. En fait, elles sont souvent documentées de manière très détaillée
- « Israël veut couper tout lien des Palestiniens avec leur terre » (reporterre.net)
La bande de Gaza est confrontée à « un génocide, un écocide et un futuricide », dénonce l’historienne et politiste Stéphanie Latte Abdallah. Elle a dirigé l’ouvrage collectif « Gaza, une guerre coloniale », paru le 14 mai.
- Trump administration working on plan to move 1 million Palestinians to Libya (nbcnews.com)
- Israel en Cisjordanie : le colonialisme sans fard (europalestine.com)
- Le deuil comme résistance. Nécropolitique d’Israël, de la Palestine au Liban (orientxxi.info)
Enterrer ses morts, leur donner une sépulture et faire son deuil est un acte éminemment politique lorsqu’il s’exerce sous domination coloniale. En ce qu’il représente un moment de rassemblement et de communion, il est un acte de résistance. Pour cela, Israël en a fait une cible de sa politique.
- Israël-Palestine : « Le plus révoltant, c’est la différence de traitement » (acrimed.org)
- La cause palestinienne s’invite à Cannes (lesnouvellesnews.fr)
Dans Put your soul on your hand and walk, une cinéaste iranienne filme ses conversations avec une jeune photographe palestinienne de Gaza, tuée le 16 avril dernier.
Spécial femmes dans le monde
- Le Kurdistan accueille un congrès de femmes du Moyen-Orient et de l’Afrique du Nord (kurdistan-au-feminin.fr)
- Sheinbaum Returns Stolen Land to Wixárika in Historic Ceremony (esperanzaproject.com)
Mexico’s first presidenta pledges full restitution and recognition of sacred sites as Wixárika leaders celebrate long-overdue justice in the mountains of Nayarit.
- Justice for Kseniia Petrova – Don’t let this case fly under the radar (statuskuo.substack.com)
She’s a Russian-born researcher who was detained by Customs and Border Protection back in February when traveling back from a conference in France. […] Apparently out of sheer spite, and faced with the prospect of losing another case where they had egregiously overreached and overreacted, the government charged Petrova with felony smuggling. That’s a charge that carries up to 20 years in prison.
- Aux États-Unis, une femme enceinte et en état de mort cérébrale est maintenue en vie à cause d’une loi anti-IVG (huffingtonpost.fr)
Adriana Smith était enceinte de neuf semaines quand elle a été admise à l’hôpital. Ses proches déplorent n’avoir aucun pouvoir décisionnaire sur son maintien en vie.
Spécial France
- Annonce du gouvernement d’abolir le Code noir : les réactions politiques en Guadeloupe (la1ere.francetvinfo.fr)
- Expo « Paris noir » au Centre Pompidou : vers un récit diasporique de la scène française (theconversation.com)
- Chlordécone : l’État devra indemniser deux ouvrières agricoles (reporterre.net)
Le tribunal administratif de la Martinique a condamné, le 12 mai, l’État français à indemniser deux anciennes ouvrières agricoles exposées au chlordécone […] Chacune recevra 10 000 euros en réparation du « préjudice moral d’anxiété » lié au risque élevé de contracter des pathologies graves, comme la maladie de Parkinson ou certains cancers du sang, reconnus comme maladies professionnelles
- Inspection à l’EPR de Flamanville : le gendarme du nucléaire pointe de graves lacunes (actu.fr)
Après une inspection sur le thème des contrefaçons, falsifications et fraudes sur le site EPR de Flamanville (Manche), le gendarme du nucléaire, l’ASNR, a rendu un rapport sévère.
- Le Commissariat à l’énergie atomique veut sous-traiter la protection de sites nucléaires (reporterre.net)
Selon les révélations de Mediapart, le Commissariat à l’énergie atomique (CEA) prévoit de sous-traiter la sécurité à l’entrée des sites nucléaires sensibles, y compris des installations militaires.
- Le coût du projet d’enfouissement des déchets radioactifs revu en hausse (nouvelobs.com)
- Surproduction : « Il y a assez de vêtements produits pour habiller l’humanité entière pendant des décennies » (socialter.fr)
Inondées par des centaines de milliers de tonnes de vêtements mis sur le marché chaque année et jetés au même rythme, la France et ses ressourceries étouffent sous les déchets textiles. Pendant longtemps, la situation a été maîtrisée par l’export de nos fripes à l’étranger, mais ce système, pris dans un circuit engorgé par la surproduction, s’écroule.
- Des Schtroumpfs par milliers battent un record schtroumpfement original à Landerneau (huffingtonpost.fr)
La petite ville du Finistère est entrée dans le Guinness World Records en rassemblant des personnes déguisées en Schtroumpf. […] Pour qu’aucun Schtroumpf ne manque à l’appel, le maire avait pris un arrêté municipal insolite, pour interdire aux bars de la ville de vendre des boissons aux Schtroumpfs pendant le comptage du rassemblement.
- Le « droit à la déconnexion » de Pronote annoncé par Borne ? (huffingtonpost.fr)
Les notifications Pronote qui apparaissent sur le téléphone à toute heure, même tard le soir, pour informer des devoirs, de l’arrivée de nouvelles notes ou d’un changement d’emploi du temps seront peut-être bientôt de l’histoire ancienne.
- Transports : en Occitanie, une appli suit les usager·es à la trace (reporterre.net)
Pour bénéficier de tarifs préférentiels dans ses transports publics, la région Occitanie incite à utiliser une application créée par une start-up suisse qui repose sur la géolocalisation de ses utilisateurices.
- Un homme trans, qui contestait en justice le refus de CPAM du Bas-Rhin de prendre en charge sa mastectomie, a obtenu gain de cause au tribunal de Strasbourg. (huffingtonpost.fr)
« C’est la première fois qu’un juge français vient reconnaître le caractère discriminatoire du refus de la CPAM et l’atteinte à la vie privée. C’est inédit »
Voir aussi Un jeune homme trans, à qui la CPAM refusait de prendre en charge une mastectomie, obtient gain de cause en justice (franceinfo.fr)
La juge a ordonné mercredi à la caisse primaire d’assurance-maladie du Bas-Rhin de prendre en charge l’intervention chirurgicale et, reconnaissant un préjudice, l’a condamnée à verser au requérant 3 000 euros de dommages et intérêts.
- Les actes anti-LGBT + ont encore augmenté en 2024, et en particulier les plus graves (huffingtonpost.fr)
Les infractions anti-LGBT + ont augmenté de 5 % en France l’an dernier, selon les chiffres du ministère de l’Intérieur. Les « crimes et délits » sont en hausse de 7 %.
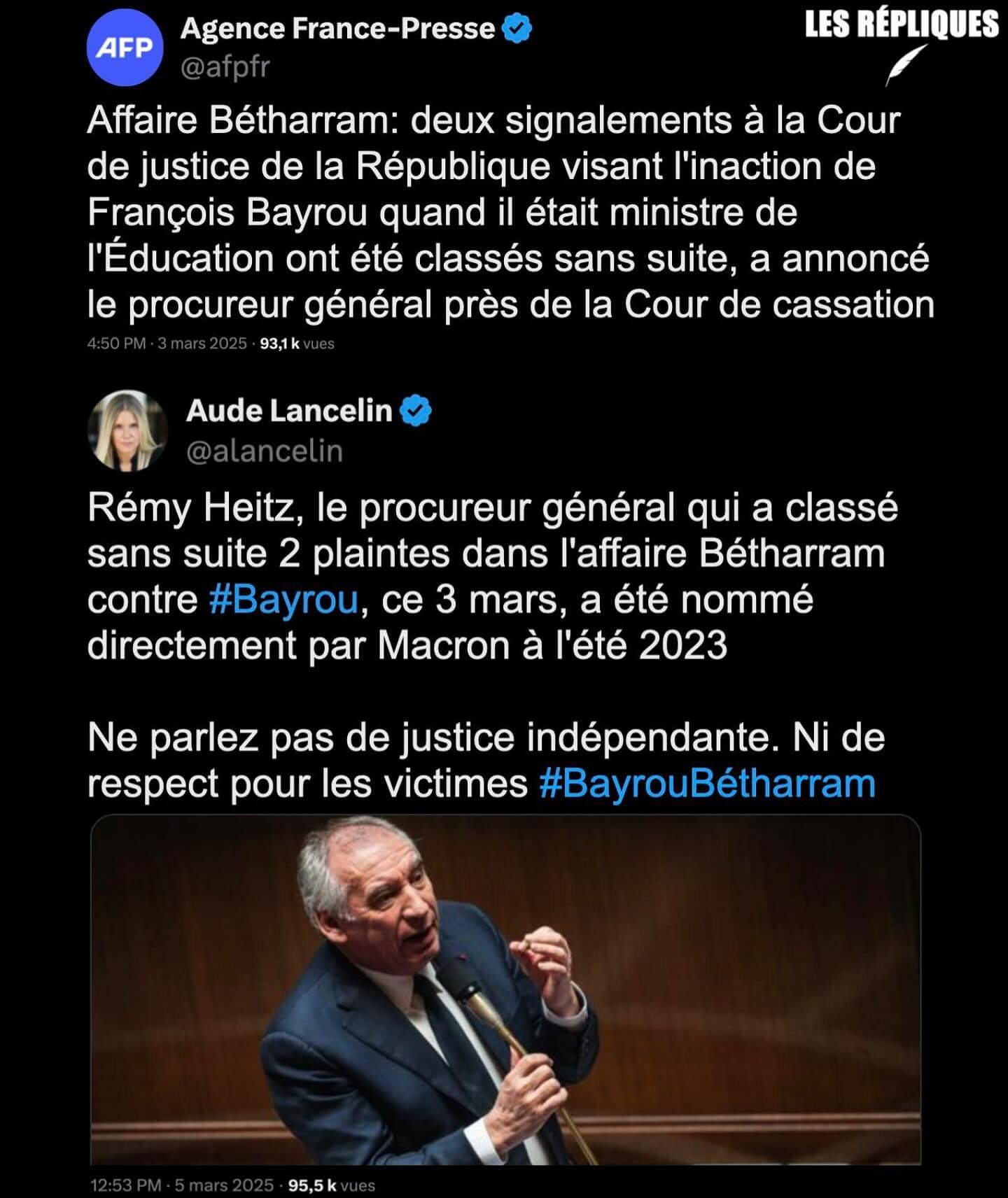
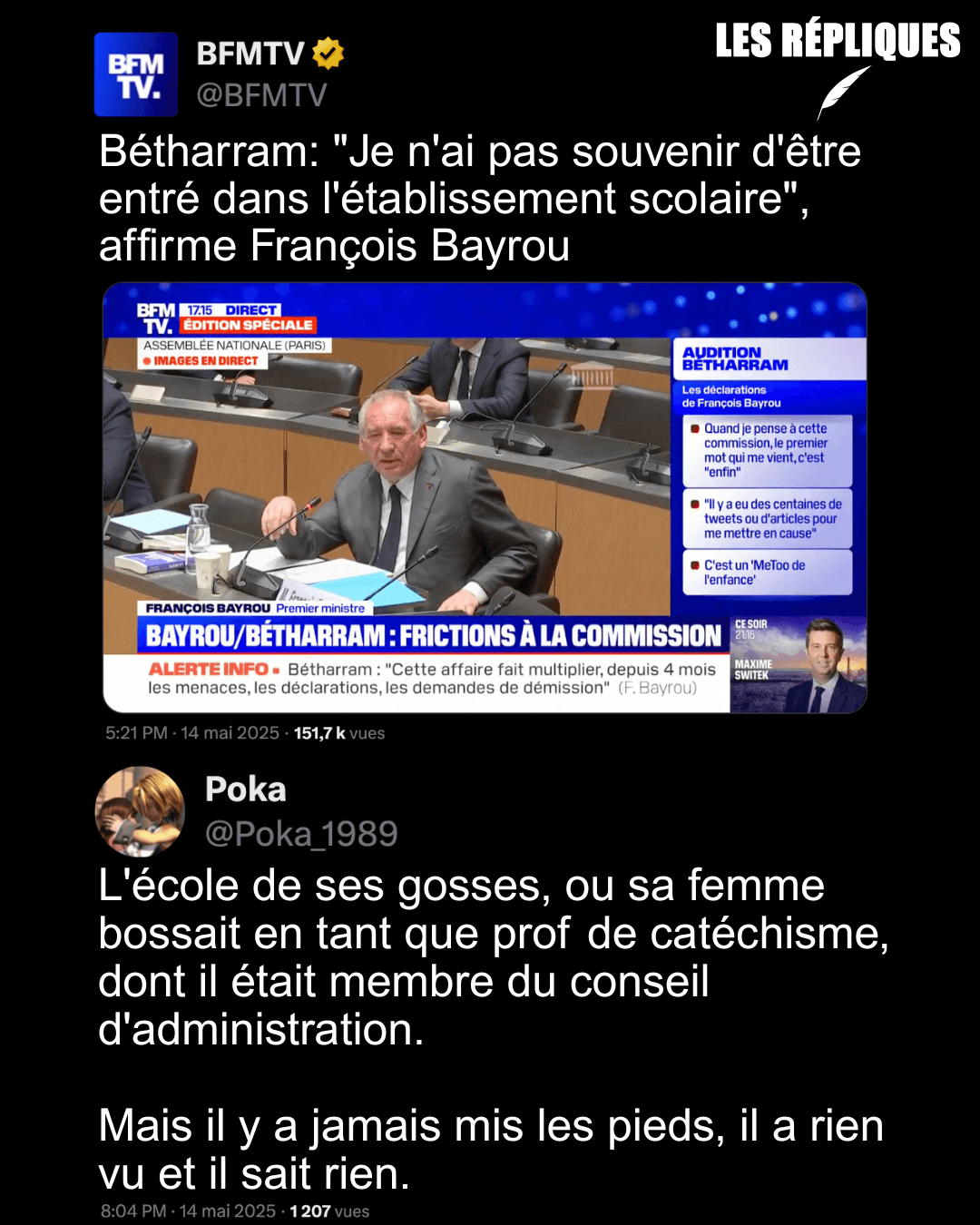
- Violences physiques et sexuelles : l’affaire Bétharram libère la parole chez d’anciens élèves de l’ensemble scolaire du Kreisker, à Saint-Pol-de-Léon (splann.org)
Une douzaine d’anciens élèves de l’établissement d’enseignement privé catholique Le Kreisker à Saint-Pol-de-Léon (29) dénoncent des violences physiques et sexuelles qui auraient été commises dans les années 1950 à 1980 par des membres du corps enseignant de cette institution réputée.
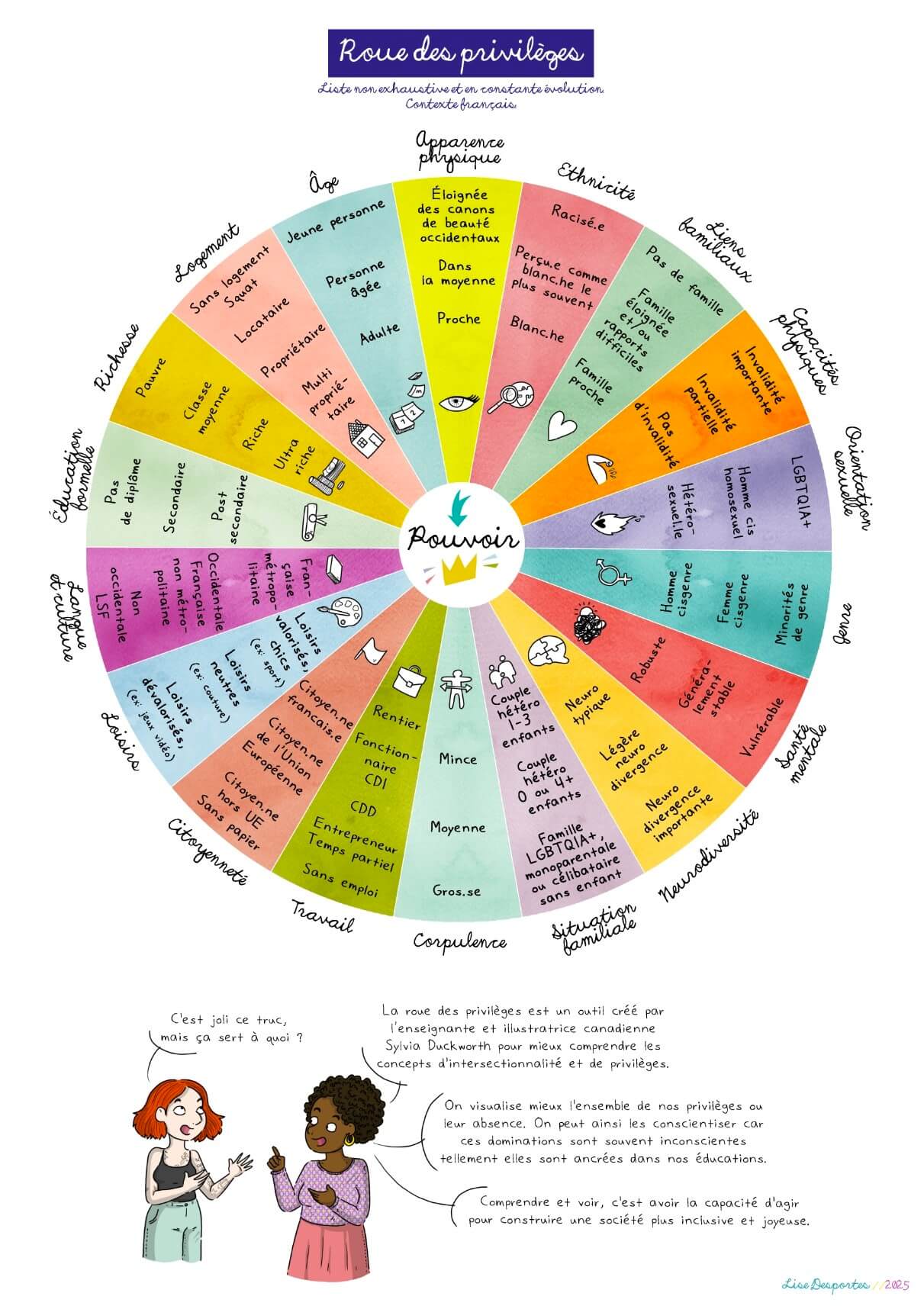
Spécial femmes en France
- Face à la croisade anti-diversité de Trump, les groupes français entre silence et déni (multinationales.org)
L’administration Trump a fait une priorité de la lutte contre les politiques de diversité et d’inclusion au sein des universités, de l’administration et des grandes entreprises, qu’elles aient ou non leur siège aux États-Unis. Du côté des grands groupes français, on préfère éviter le sujet.

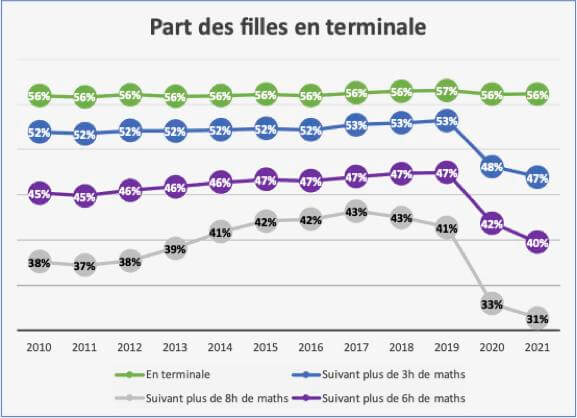
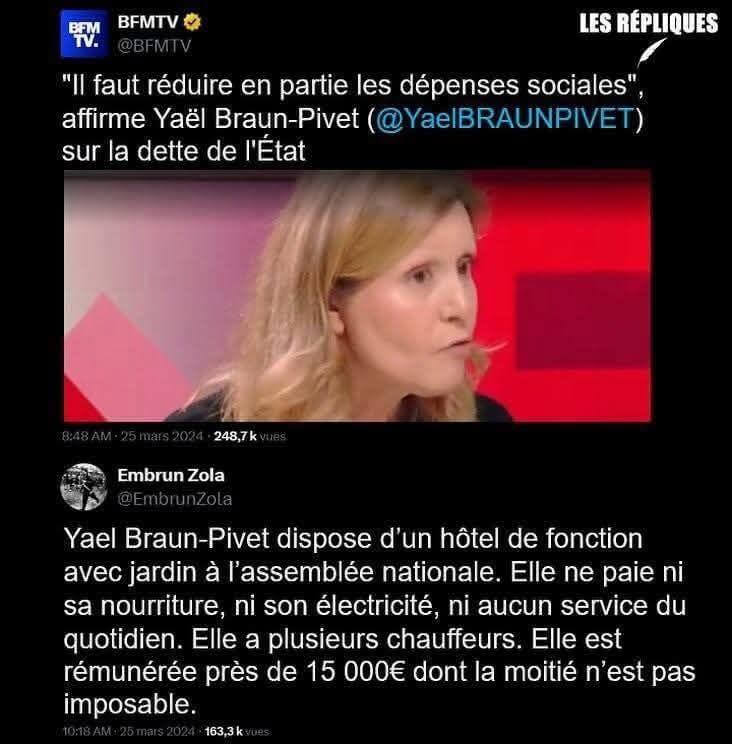
- Plan « Filles et maths » : Borne corrige Blanquer, mais oublie le sexisme (politis.fr)
Le 7 mai, la ministre de l’Éducation, Élisabeth Borne, présentait le plan « Filles et maths », pour inciter les filles à étudier les sciences. Ces inégalités sont loin d’être nouvelles, et ont même été aggravées par la réforme de 2019 du lycée de Jean-Michel Blanquer.
- L’escalade, un sport sexiste ? (frustrationmagazine.fr)
- Viande, voiture… Les hommes polluent beaucoup plus que les femmes (reporterre.net)
les femmes ont une empreinte carbone 26 % moins élevée dans les domaines de l’alimentation et des transports.
Voir aussi The gender gap in carbon footprints : determinants and implications (lse.ac.uk)
- Naturaliste agressée : « Les personnes comme toi méritent d’être égorgées » (reporterre.net)
Une jeune technicienne naturaliste a été agressée par un agriculteur, ancien patron de la FNSEA de Loire-Atlantique. Un nouvel incident dans la guerre de l’agro-industrie contre les acteurs de l’environnement.
- Mortalité infantile : l’Assemblée nationale adopte un moratoire sur les fermetures de maternité (humanite.fr)
Victoire surprise pour le groupe Liot, jeudi 15 mai, à l’Assemblée. Après le rejet en commission du moratoire sur la fermeture des maternités mis sur la table par le groupe parlementaire, les députés l’ont voté en séance et ont adopté l’ensemble de la proposition de loi visant à lutter contre la mortalité infantile, portée par Paul-André Colombani.
- À Saint-Denis, les expulsions répétées de femmes enceintes et d’enfants sans-abri (basta.media)
Des femmes et leurs enfants dorment depuis des semaines dans la rue au nord de Paris, faute de logement et d’hébergement d’urgence. Regroupées dans un collectif, elles ont récemment occupé l’université Paris-8, avant d’en être expulsées.
- Gérard Depardieu coupable d’agressions sexuelles, l’acteur condamné à 18 mois de prison avec sursis (huffingtonpost.fr)
Le tribunal correctionnel a aussi prononcé une peine d’inéligibilité de deux ans ainsi que son inscription au fichier des auteurs d’infractions sexuelles. Son avocat, Jérémie Assous, a aussitôt annoncé que son client fera appel de ces condamnations.
Voir aussi Depardieu condamné à 18 mois de prison avec sursis pour agressions sexuelles : “C’est une première victoire” (telerama.fr)
« Dorénavant, on sait que Gérard Depardieu est bien un agresseur sexuel. »
Et Anouk Grinberg : “Pour une fois, dans l’affaire Depardieu, les plaignantes ont été entendues” (france24.com)
- “On assiste à une”ubérisation” des relations sexuelles” : le phénomène de la prostitution des jeunes femmes mineures prend de l’ampleur (france3-regions.franceinfo.fr)
“Souvent, ces jeunes femmes sont victimes d’actes de violences par leur proxénète. Ou se sentent en danger. Certaines appellent alors 17, et c’est souvent comme ça que ces affaires éclatent et qu’on se rend compte, qu’il y avait aussi de la prostitution et qu’elles étaient sous emprise”
- Affaire dite “French Bukkake” et “Pascal OP” : une première victoire judiciaire saluée par la LDH (ldh-france.org)
la Cour de cassation a annulé la décision de la Chambre de l’instruction de Paris qui avait reconnu l’existence de propos racistes et sexistes tenus par les personnes mises en examen, sans pour autant avoir jugé utile d’en tirer les conséquences juridiques nécessaires. Cette censure marque une étape importante dans la reconnaissance de la gravité des faits. Il s’agit d’une première victoire pour les victimes, dont les témoignages ont mis au jour des violences inouïes, à la fois physiques, psychologiques et symboliques.
- Un réseau international de prostitution démantelé depuis le Limousin (francebleu.fr)
Le système, très organisé, se concentrait sur des jeunes femmes recrutées en Chine. Très souvent endettées, elles étaient envoyées en Europe, et finalement en France dans des villes de province, où elles ne restaient que quelques jours. Les appartements étaient généralement loués par des plateformes type Airbnb. […] Selon les enquêteurs, plus d’une centaine de jeunes Chinoises ont été recrutées et effectuaient de quatre à cinq passes par jour, de quoi rapporter 800.000 euros par mois au réseau.
RIP
- Fadéla M’Rabet, pionnière du féminisme algérien, est morte à Paris (lemonde.fr)
Cette biologiste, enseignante, écrivaine et militante avait dû s’exiler en France, en 1971. Elle s’est éteinte mercredi 14 mai, à l’âge de 90 ans.
Le rapport de la semaine
- Parution du Rapport sur les LGBTIphobies 2025 (crm.sos-homophobie.org)
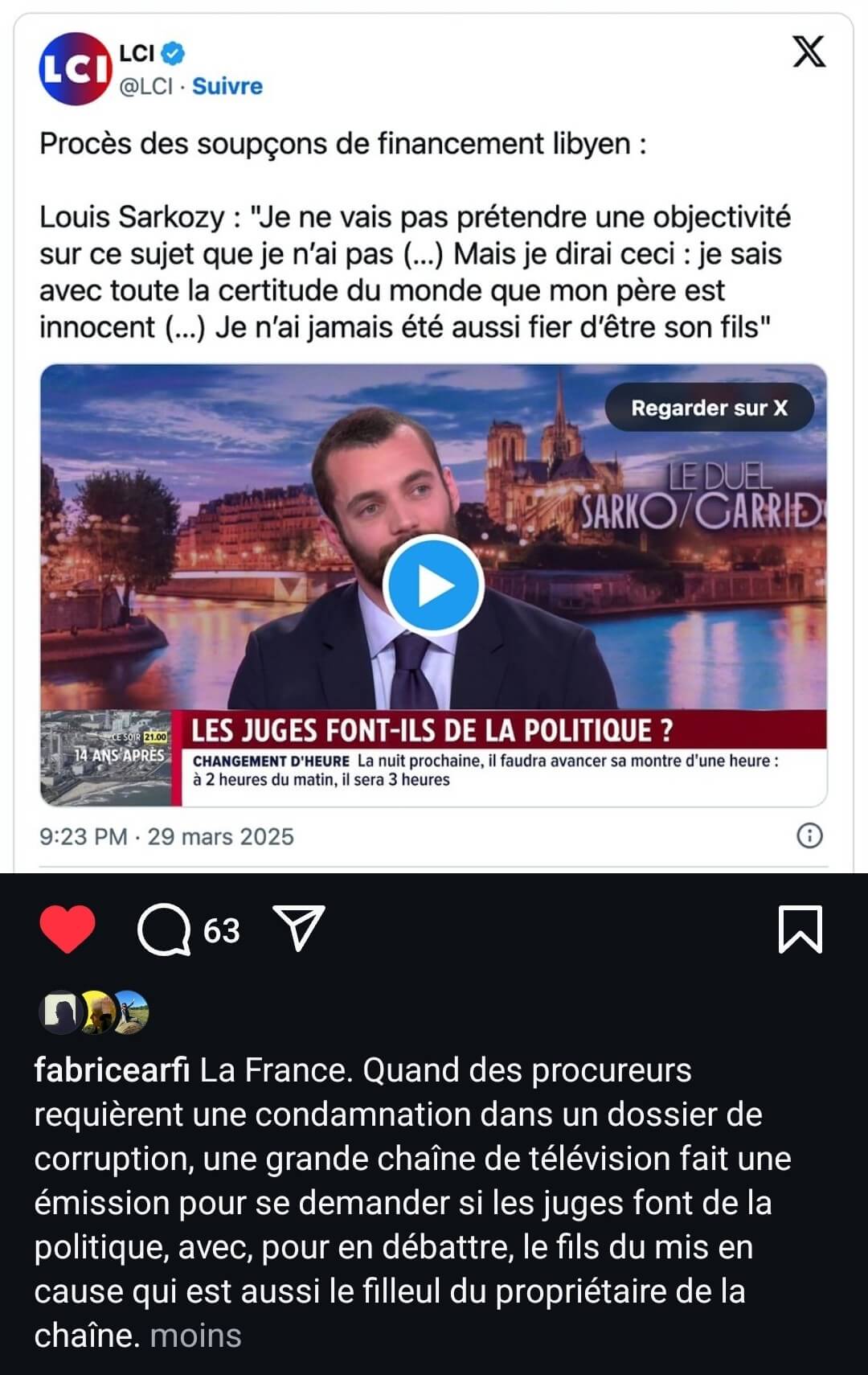
Spécial médias et pouvoir
- Non, les écologistes ne veulent pas interdire le Comté : comment un article de presse national a mis le feu aux poudres (france3-regions.francetvinfo.fr)
- Ce que nous dit l’acharnement médiatique contre LFI (acrimed.org)
Si LFI ne saurait être au-dessus de toute critique, qui peut prétendre qu’il n’en va pas là d’un dysfonctionnement démocratique de premier plan ?
- Les rentes africaines de Bolloré (multinationales.org)
Au fil des ans, le groupe Bolloré a amassé des milliards d’euros grâce à ses activités africaines, à la fois sous forme de remontée de dividendes et grâce aux plus-values réalisées lors des cessions d’actifs. Pour une large part, ce sont ces revenus qui lui ont permis d’acheter son empire médiatique. Même après avoir revendu ses concessions portuaires et ses activités logistiques, Bolloré est loin d’avoir quitté le continent.
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
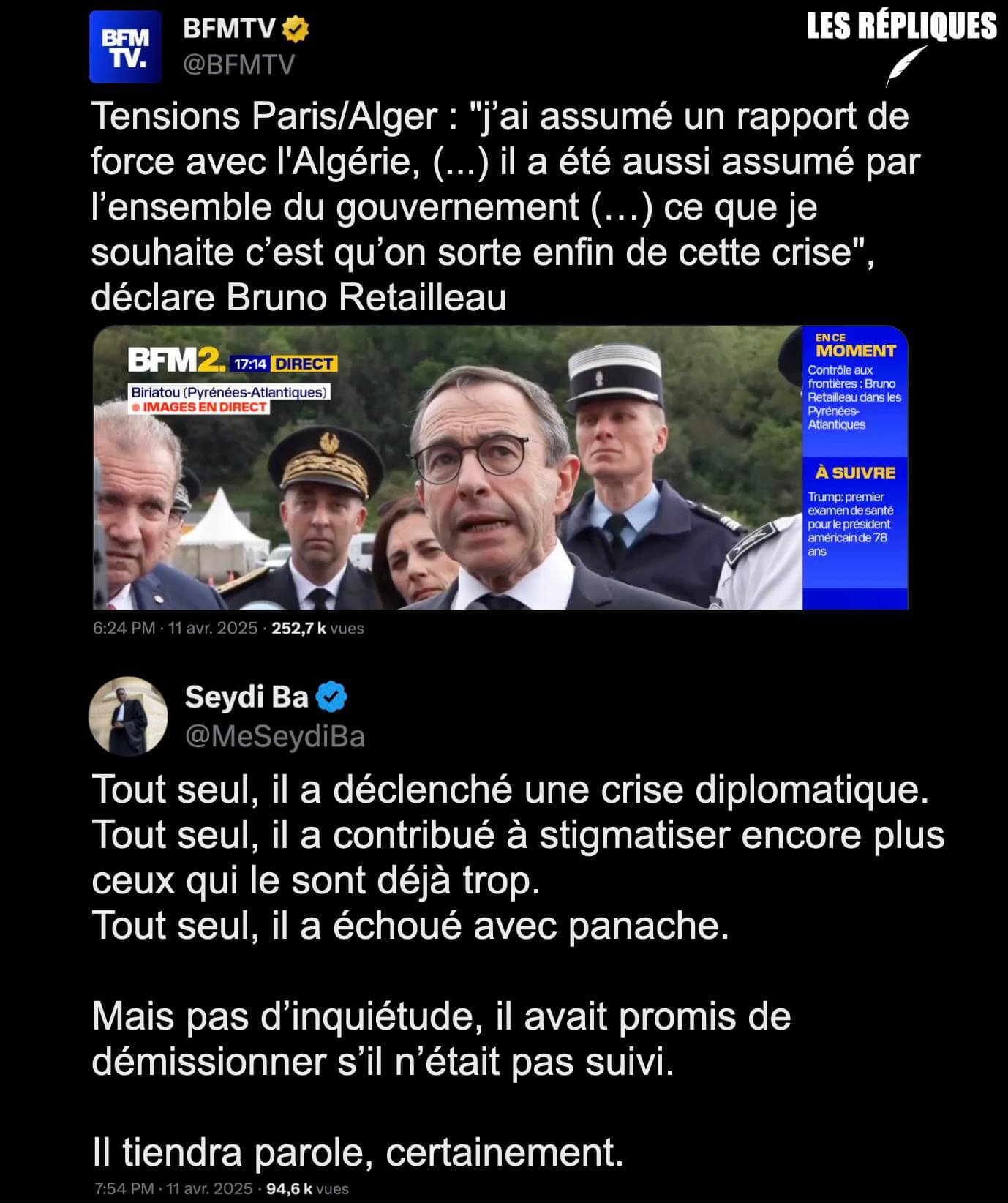
- Sur TF1, Emmanuel Macron réduit à défendre son bilan (et à illustrer sa perte de pouvoir) (huffingtonpost.fr)
Durant trois heures et demie, le chef de l’État s’est défendu sur une multitude de sujets et a évoqué, du bout des lèvres, des référendums aux contours flous.

- Cité par Emmanuel Macron en direct sur TF1, l’économiste Gabriel Zucman lui répond (huffingtonpost.fr)
L’économiste, dont les travaux sur une taxation des plus riches sont plébiscités à gauche, a répondu point par point aux arguments du chef de l’État.
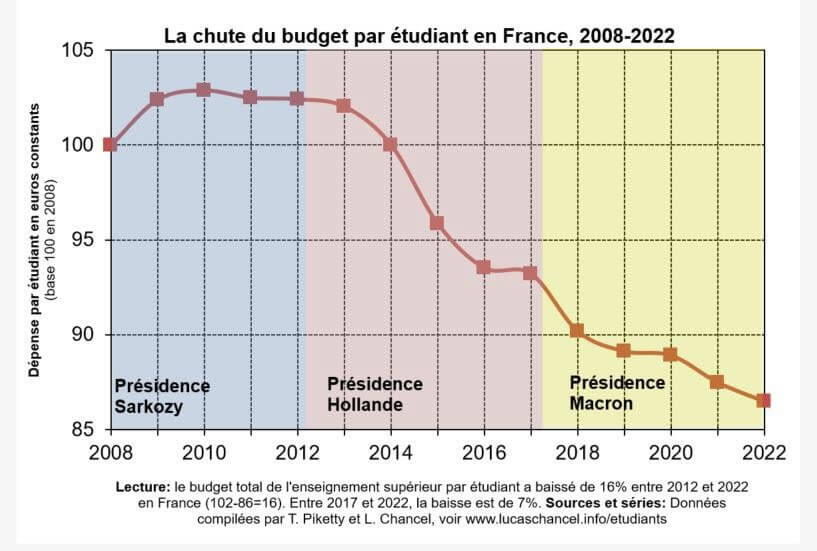
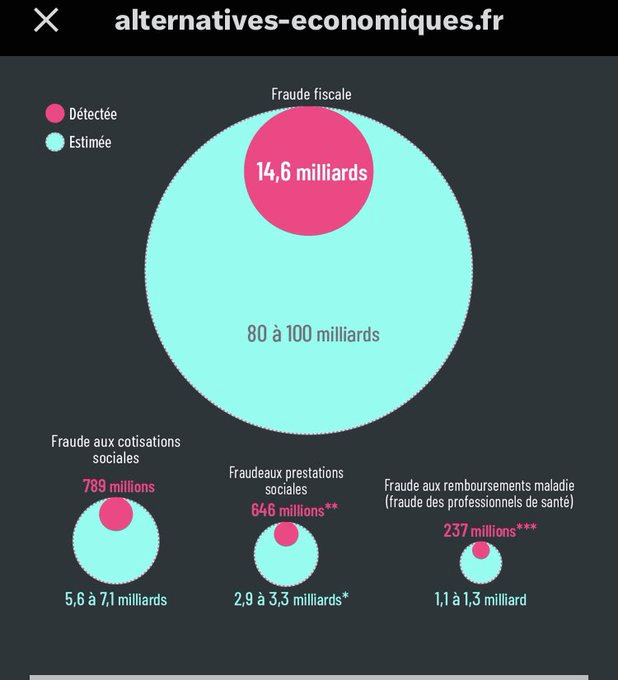
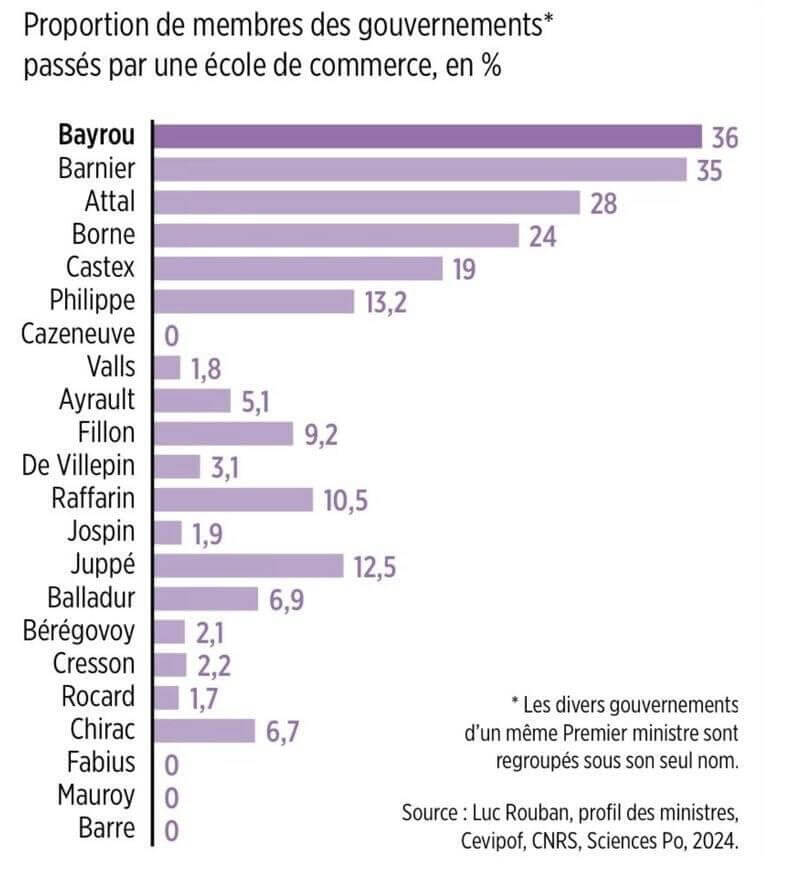
- Les sept graphiques qu’Emmanuel Macron a oublié de montrer (alternatives-economiques.fr)
Lors de son intervention sur TF1 mardi, le chef de l’Etat est venu avec ses graphiques. Il a pourtant multiplié les contre-vérités sur le chômage, l’immigration, les retraites, ou encore le taux d’imposition des riches.
- Désinformation : l’Élysée alerte contre les manipulateurs, « à l’extérieur comme à l’intérieur » du pays (next.ink)
- Loi Duplomb : un texte écocidaire rédigé par la FNSEA (reporterre.net)
- Pesticides : l’interminable fiasco des plans Écophyto (reporterre.net)
« On a l’impression que c’est la FNSEA qui dirige le ministère »
- Dans le scandale du chlordécone, les élu·es ultramarin·es ulcéré·es par ce pourvoi de l’État (huffingtonpost.fr)
Des élu·es de Guadeloupe et de la Martinique ne décolèrent pas après la procédure enclenchée par l’État, et confirmée par une source à l’AFP ce vendredi 16 mai. L’État a formé un pourvoi contre la décision de la cour administrative d’appel de Paris qui avait reconnu sa responsabilité dans le scandale du chlordécone aux Antilles, un pesticide extrêmement toxique.
- A69 : « L’État a tant investi que renoncer lui serait inacceptable » (reporterre.net) – voir aussi Autoroute A69 : « Il y a une radicalisation de l’État dans les dossiers environnementaux » (humanite.fr)
- Le Sénat adopte la proposition de loi pour reprendre les travaux de l’autoroute A69 (vert.eco)
Une proposition de loi qui vise à rendre à nouveau l’A69 légale a été adoptée par le Sénat ce jeudi. Elle doit encore poursuivre sa navette législative, mais elle pourrait court-circuiter la décision du tribunal administratif de Toulouse, qui avait acté, en février dernier, l’interdiction du projet d’autoroute.
Voir aussi Autoroute A69 : victoire écocide de la droite sénatoriale qui vote pour la reprise du chantier (humanite.fr)
- Le nucléaire va ruiner la France (reporterre.net)
Malgré le coût faramineux du tout-nucléaire, la France s’enferre dans cette impasse. Voici les bonnes feuilles du livre-enquête « Le nucléaire va ruiner la France ». Laure Noualhat y décortique les mécanismes d’une gabegie.
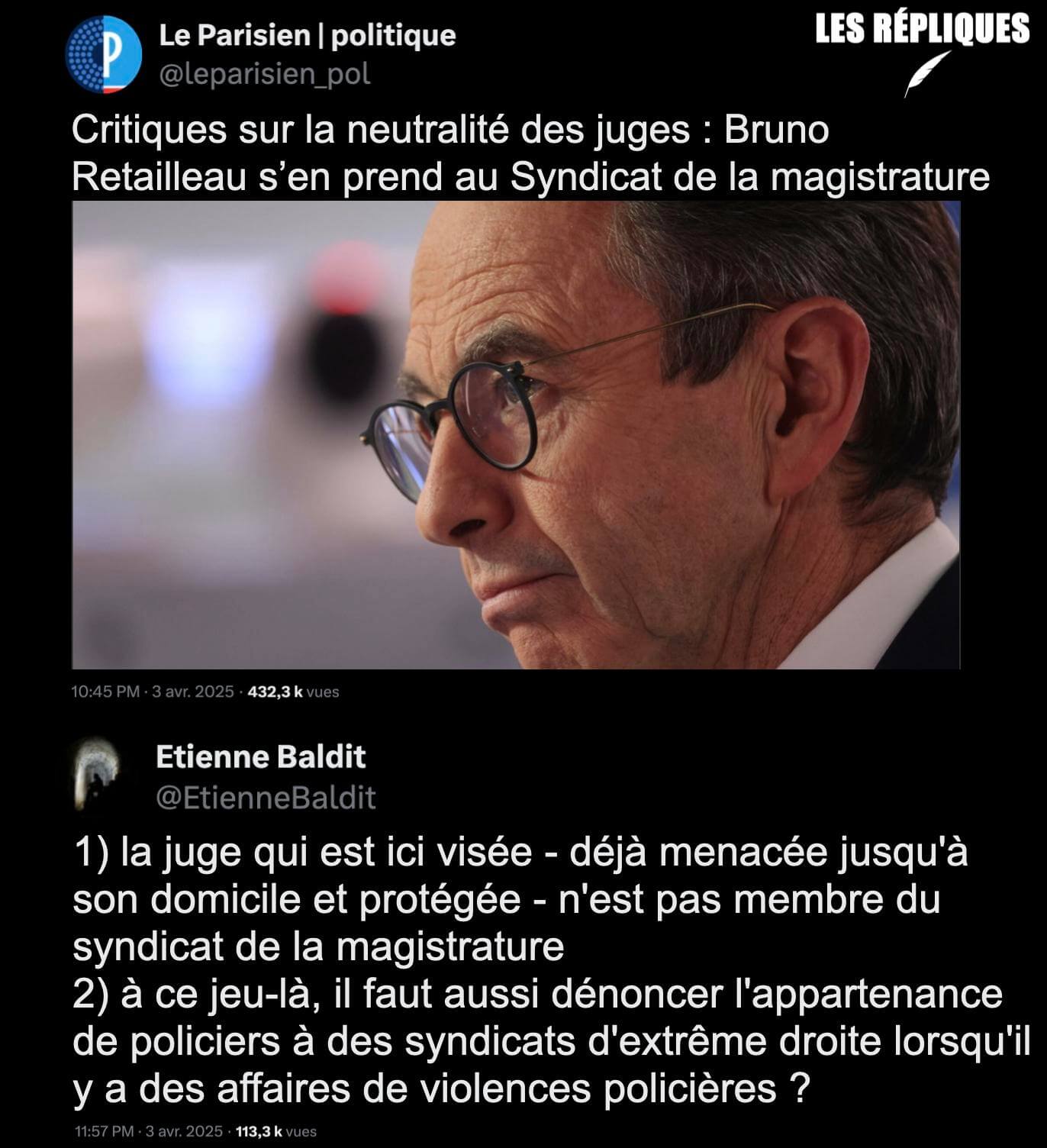
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- En Nouvelle-Calédonie, la répression coloniale se poursuit (politis.fr)
Un an après les émeutes de mai 2024, l’archipel ultramarin reste marquée par une répression exceptionnelle. Militarisation, arrestations massives et atteintes aux libertés ravivent les blessures du passé colonial jamais refermé.
- Nommer l’islamophobie : un enjeu essentiel contre les violences faites aux musulman·es (theconversation.com)
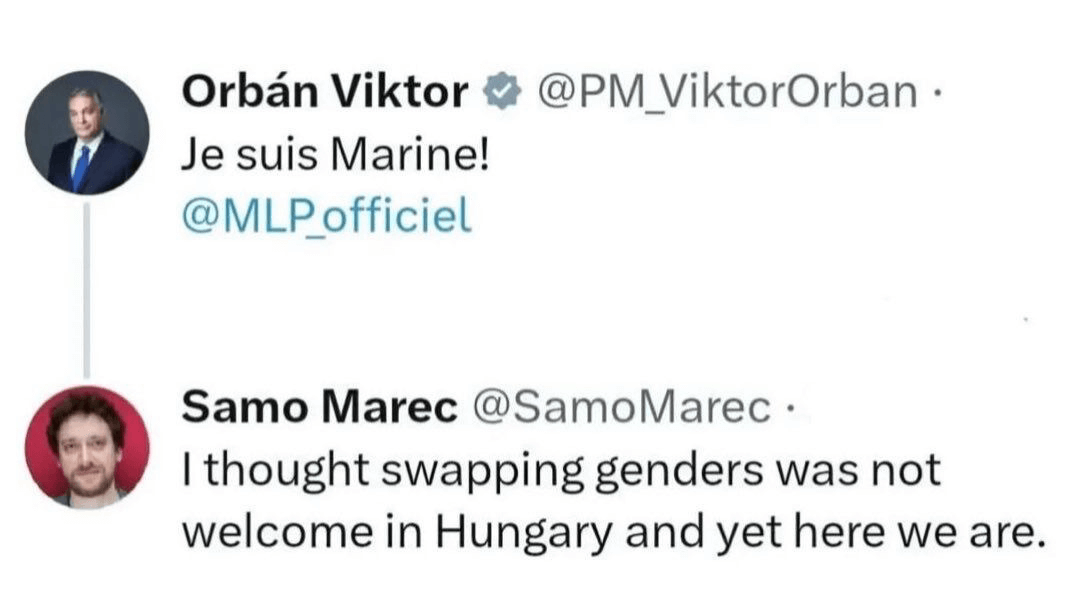
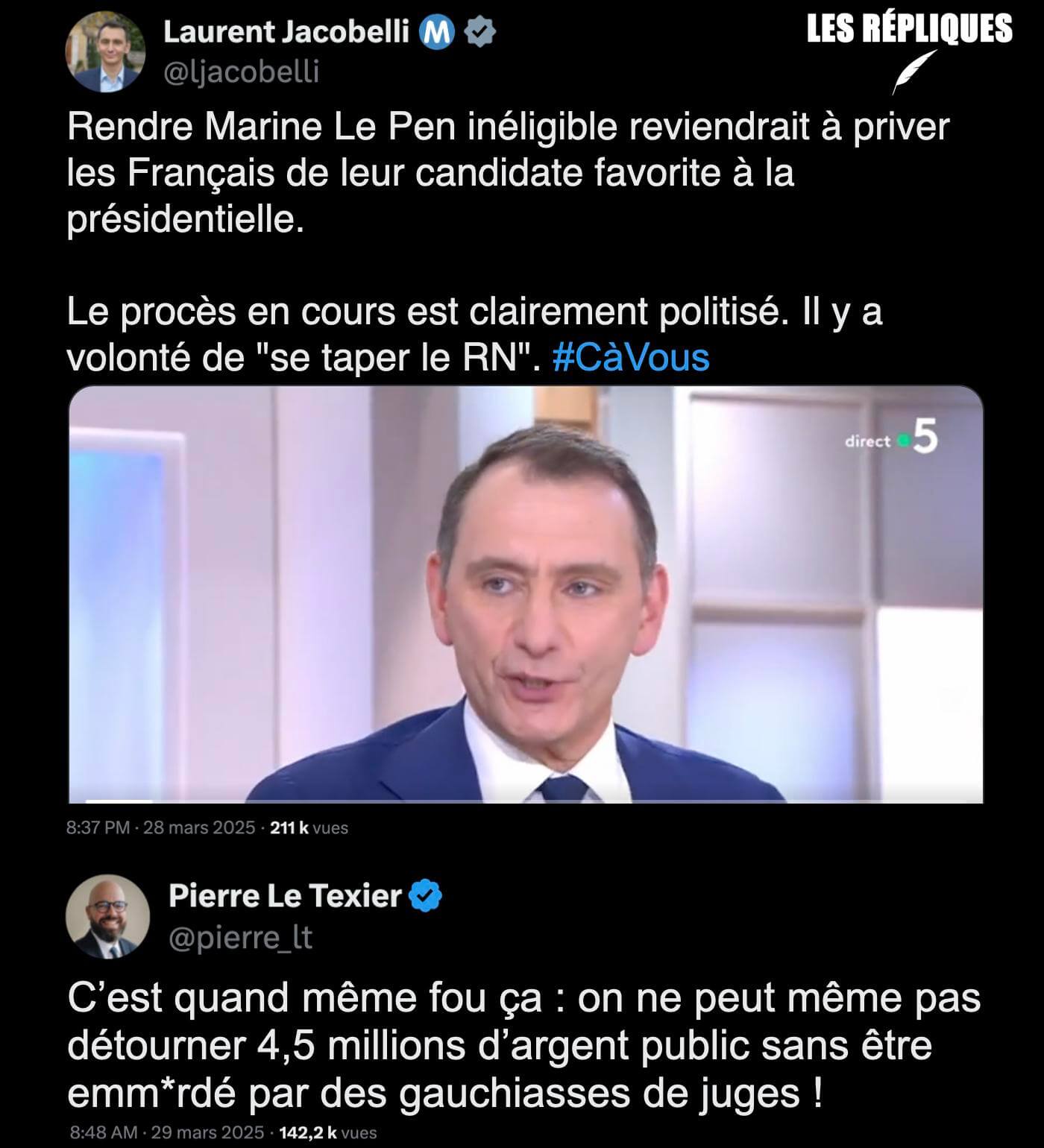
- François Bayrou – Marine Le Pen : leur rendez-vous secret quelques jours avant le jugement (lexpress.fr)
Ce Premier ministre est cachottier (sollicité par L’Express sur l’objet de sa rencontre avec Marine Le Pen, il a répondu d’un lapidaire : “C’est n’importe quoi !”) et déconcertant. N’est-ce pas lui qui regrettait quelques mois plus tôt que l’un de ses prédécesseurs, Edouard Philippe, ait jugé pertinent de partager avec la patronne des députés RN un dîner ? “Je pense, moi, qu’il y a entre nous et l’extrême droite un fossé qui est infranchissable parce que ce qu’il y a de plus profond dans l’extrême droite ça n’est pas les mesures annoncées qui sont déjà pour un certain nombre d’entre elles choquantes, c’est les arrière-pensées derrière tout ça”, avait-il déclaré. Quant à la rencontre entre Sébastien Lecornu et Marine Le Pen, le même Bayrou l’avait commentée en ces termes : “C’est un mauvais signal à l’égard du pays.”
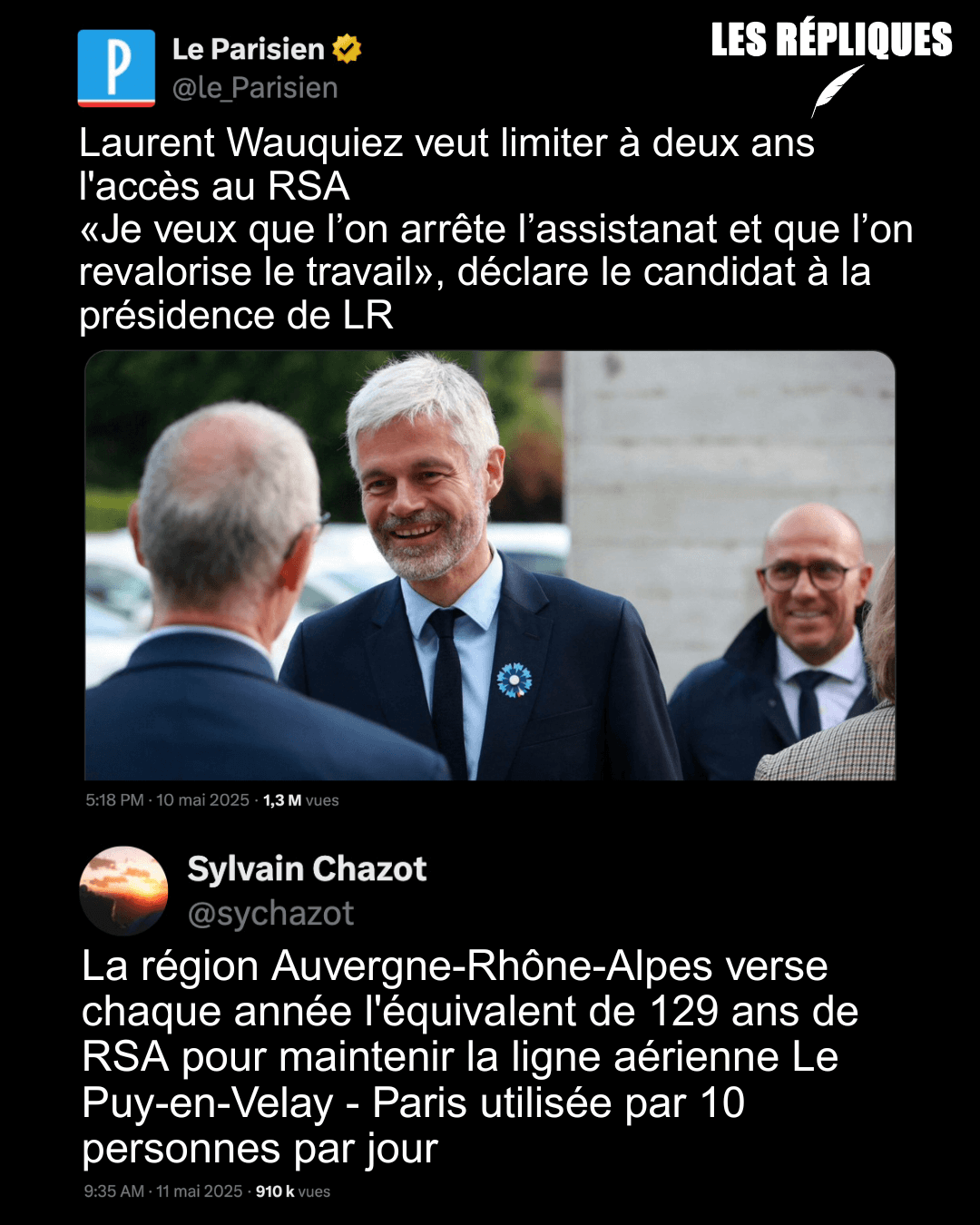
- Pour Laurent Wauquiez, le « modèle pour la droite » se trouve à l’extrême droite (et pas qu’en Italie) (huffingtonpost.fr)
Le candidat à la présidence de LR dit toute son admiration pour Giorgia Meloni et pour l’eurodéputée zemmouriste Sarah Knafo.
- Marine Le Pen soutient sans réserve ce que fait Israël à Gaza (huffingtonpost.fr)
La leader d’extrême droite dit « partager l’objectif » de Netanyahu et assure qu’il « fait ce qu’il peut » dans la lutte contre le Hamas.
- Néofascistes samedi, royalistes dimanche… À Paris, un week-end sous les sigles de l’extrême droite radicale (humanite.fr)
Après la manifestation du Comité du 9 mai samedi 10 mai, l’Action française a marché ce dimanche pour rendre hommage à Jeanne d’Arc, suivie de près par des anciens pétainistes de l’Œuvre française.
- Deux enseignants en garde à vue pour une banderole sur Bruno Retailleau à la manifestation de la fonction publique (ledauphine.com)
une banderole tendue entre deux arbres par ces manifestants et comportant les mots « 9 mai, Paris, Retailleau aime les néonazis » […] serait la cause de ces interpellations.
- Contrôles au faciès : une sénatrice PS dépose une proposition de loi pour instaurer un récépissé et “rétablir l’image du policier auprès de la population” (franceinfo.fr)
- Filatures et caméras, l’université Paris-Nanterre a espionné des syndicalistes étudiants (streetpress.com)
C’est une affaire ubuesque. Agacés par l’occupation d’un bâtiment par des étudiants de l’UNEF, les services de sécurité de l’Université Paris-Nanterre ont acheté des caméras-espions, fait suivre des étudiant·es et même envisagé de poser des micros.
- “Beaucoup de collègues ne veulent pas en entendre parler” : pourquoi la police et la justice peinent à reconnaître les agressions LGBTphobes (franceinfo.fr)
- À Orléans, des autocollants décrètent des « zones interdites aux musulmans », une enquête est ouverte (humanite.fr)
Des collages islamophobes, provenant d’un site vendant des drapeaux nazis, ont été affichés dans les rues de la ville du Loiret. Une enquête est ouverte pour « provocation à la haine en raison de la religion ».
Spécial résistances
- À Strasbourg, des blocages dans trois lycées “pour un cessez le feu à Gaza” (rue89strasbourg.com)
- Maintien de l’ordre : le danger des grenades explosives exposé à l’ONU (politis.fr)
À l’approche de la 80ᵉ session de l’Assemblée générale de l’ONU, qui aura lieu en septembre 2025, l’ONG Flagrant Déni appelle la Rapporteuse spéciale sur la torture à classer les grenades à effet de souffle françaises parmi les armes interdites.
- Des enseignant·es appellent à boycotter les manuels scolaires édités par le groupe Bolloré (basta.media)
Les syndicats Sud Education et FSU-SNUipp ainsi que les Soulèvements de la Terre dénoncent la mainmise du groupe Bolloré sur les manuels scolaires, notamment via Hachette. Ils appellent au boycott dans une tribune.
- Sans les travailleureuses migrant·es, la France serait incapable de produire des fruits et légumes (basta.media)
Cher·es parlementaires et politiques qui votez des lois ou publiez des circulaires racistes : qui récolte vos fruits et légumes ? En France – premier producteur agricole européen – […] sans les saisonnières et saisonniers étrangers, il serait impossible de fournir les stocks dont nous avons besoin pour nous nourrir.
- « Cela ne tient plus que par nous et on n’en peut plus » : des fonctionnaires à bout de souffle mobilisé·es pour la survie des services publics (humanite.fr)
À Paris, la mobilisation nationale des agent·es a permis de prendre le pouls de leur colère. Usé·es par le manque de moyens autant que par le « mépris » qu’iels subissent, iels s’insurgent contre la nouvelle potion austéritaire annoncée par le gouvernement.
- Projet de loi fin de vie : des risques eugénistes et validistes ? (blogs.mediapart.fr)

- « Pollution fécale issue des élevages industriels environnants » : Greenpeace et un collectif d’associations alertent sur le danger des eaux contaminées dans le Finistère (humanite.fr)
Face aux résultats accablants d’analyses d’eau indépendantes menées sur la plage de Penfoul à Landunvez, les analyses bactériologiques révèlent une contamination préoccupante de l’eau de baignade par des bactéries pathogènes »
- “C’est une décision très forte” : relaxés en appel, des militants écologistes triomphent face à Arkema (france3-regions.franceinfo.fr)
La cour d’appel de Lyon a confirmé jeudi la relaxe de sept écologistes qui s’étaient introduits sur le site d’Arkema à Pierre-Bénite pour dénoncer la pollution aux « polluants éternels ». L’un d’entre eux est en revanche condamné pour “rébellion”.
- Des collectifs d’habitant·es perturbent l’assemblée d’actionnaires d’une multinationale minière (basta.media)
Des collectifs des quatre coins de la France se sont rassemblés à Paris contre les projets d’une multinationale minière française, Imerys. De la Bretagne à la Dordogne, tous sont impactés par l’extraction, poussée au nom de la transition écologique.
- ArcelorMittal : Cédric, Aline, Philippe, Emerson… découvrez les témoignages de ces damnés de l’acier (humanite.fr)
L’annonce de la suppression de plus de 600 emplois, dont la moitié à Dunkerque, a ravivé la colère des salariés d’ArcelorMittal
Spécial outils de résistance
- Qui est (vraiment) Pierre-Édouard Stérin (vert.eco)
Pierre-Édouard Stérin est milliardaire, réac, note tout le monde sur dix, et il a un plan : investir 150 millions d’euros sur dix ans pour diffuser ses idées et faire « gagner mille villes » au RN aux municipales de 2026. Ce mercredi, pour la deuxième fois, il n’a pas répondu à la convocation de la commission d’enquête parlementaire pour s’expliquer sur son projet d’influence politique nommé Périclès.
- Introducing oniux : Kernel-level Tor isolation for any Linux app (blog.torproject.org)
- Une Tesla, un sticker
Spécial GAFAM et cie
- EU ruling : tracking-based advertising by Google, Microsoft, Amazon, X, across Europe has no legal basis (iccl.ie)
Google, Microsoft, Amazon, X, and the entire tracking-based advertising industry rely on the “Transparency & Consent Framework” (TCF) to obtain “consent” for data processing. This evening the Belgian Court of Appeal ruled that the TCF is illegal. The TCF is live on 80 % of the Internet.
- Google to pay $1.38 billion over privacy violations (malwarebytes.com)
The state of Texas reached a mammoth financial agreement with Google last week, securing $1.375 billion in payments to settle two three year-old lawsuits.
- Google Worried It Couldn’t Control How Israel Uses Project Nimbus, Files Reveal (theintercept.com)
Internal Google documents show that the tech giant feared it wouldn’t be able to monitor how Israel might use its technology to harm Palestinians.
- Is Google making search worse to sell more ads ? (journalrecord.com)
- Nextcloud cries foul over Google Play Store app rejection (theregister.com)
European software vendor Nextcloud has accused Google of deliberately crippling its Android Files application, which it says has more than 800,000 users.
Voir aussi Google backs down after locking out Nextcloud Files app (go.theregister.com)
- Meta contraint NSO à dévoiler les coulisses de son logiciel espion Pegasus (next.ink)
Un jury populaire états-unien vient d’accorder à Meta 167 millions de dollars de dommages et intérêts. NSO avait en effet été reconnu coupable d’avoir infecté 1 400 terminaux Android entre 2018 et 2020 via la messagerie chiffrée WhatsApp. Les témoignages de responsables de l’éditeur israélien lèvent par ailleurs un coin de voile sur le modus operandi de son logiciel espion, de son prix, et du nombre de personnes qu’il avait ciblé… ou pas.
Voir aussi Seven things we learned from WhatsApp vs. NSO Group spyware lawsuit (techcrunch.com)
- Espionnage des iPhone via Siri : une action collective contre Apple lancée en France (huffingtonpost.fr)
Cette plainte, menée par trois avocats dont Julien Bayou, est le pendant français de l’affaire des écoutes abusives par la marque. Le remboursement des appareils est réclamé.
- Les Français·es quittent le plus massivement le réseau X d’Elon Musk en Europe (liberation.fr)
La plateforme du milliardaire d’extrême droite a enregistré le départ de 11 millions d’utilisateurices européen·nes en moins d’un an, dont 2,7 millions de Français·es, selon les chiffres récemment publiés par l’entreprise.
Les autres lectures de la semaine
- ‘We Are in a Moment of Unparalleled Peril’ : An Interview With Naomi Klein (prospect.org)
- Le fascisme et le spectacle de la mort (lundi.am)
Ou comment notre accoutumance aux images de mort qui défilent sur nos écrans, nous prépare culturellement au fascisme.
- Gaza, condensateur sans équivalent. Frédéric Lordon sur le procès d’Anasse Kazib (revolutionpermanente.fr)
Dans Gaza, il y a le déboussolement porté à son comble quand l’Etat représentatif d’un peuple qui a subi le génocide commet un génocide à son tour, quand les dirigeants d’un peuple pour le martyre duquel a été forgée la catégorie de « crime contre l’humanité », sont poursuivis pour crime contre l’humanité.
- Que peut vraiment le droit face au fascisme ? (politis.fr)
Si la montée de l’extrême droite, avec son cortège de haine et de violence, inquiète, l’arsenal légal peut devenir une arme à double tranchant dans la lutte contre les aspirations fascisantes.
- Que peut l’Europe face à Trump ? (alternatives-economiques.fr)
l’UE envisagerait d’accorder des dérogations aux entreprises américaines sur l’impôt minimum mondial sur les multinationales mis en place dans le cadre de l’OCDE et dont les Etats-Unis de Trump se sont retirés. Si cela venait à être confirmé, ce serait une grave erreur : l’Europe ne doit en rien reculer dans le bras de fer lancé par Trump sur les régulations européennes, qu’elles soient fiscales, sociales ou écologiques
- Arnaud Saint-Martin : « Les astrocapitalistes comme Elon Musk veulent s’approprier l’espace pour l’exploiter comme un marché » (alternatives-economiques.fr)
- Pourquoi Trump s’attaque-t-il aux programmes de diversité, équité et inclusion ? (multinationales.org)
En ciblant les programmes de « diversité, équité et inclusion » (DEI), Donald Trump s’attaque surtout à un symbole, qui renvoie à l’héritage du mouvement des droits civiques et plus récemment au mouvement « Black Lives Matter ».
- Capitalisme et racisme. L’apport fondamental du marxisme noir (contretemps.eu)
- Régulation de l’installation des médecins : de quelle liberté parle-t-on ? (basta.media)
Des étudiant·es en médecine mobilisent contre la proposition de loi Garot visant à réguler l’installation des médecins contre les déserts médicaux. D’autres étudiants la soutiennent, dont le collectif Pour une santé engagée et solidaire.
- Droit de vote des Françaises : comment des féministes méconnues ont porté la lutte pendant un siècle (telerama.fr)
Fin avril 1945, les Françaises étaient appelées aux urnes pour la première fois. Un droit qui doit beaucoup à des centaines de militantes, que l’Histoire n’a pas retenues. Anne-Sarah Bouglé Moalic a retracé leur épopée.
- “Elles ont été oubliées” : une professeure explore les causes de l’invisibilité des femmes artistes dans l’histoire de l’art (france3-regions.francetvinfo.fr)
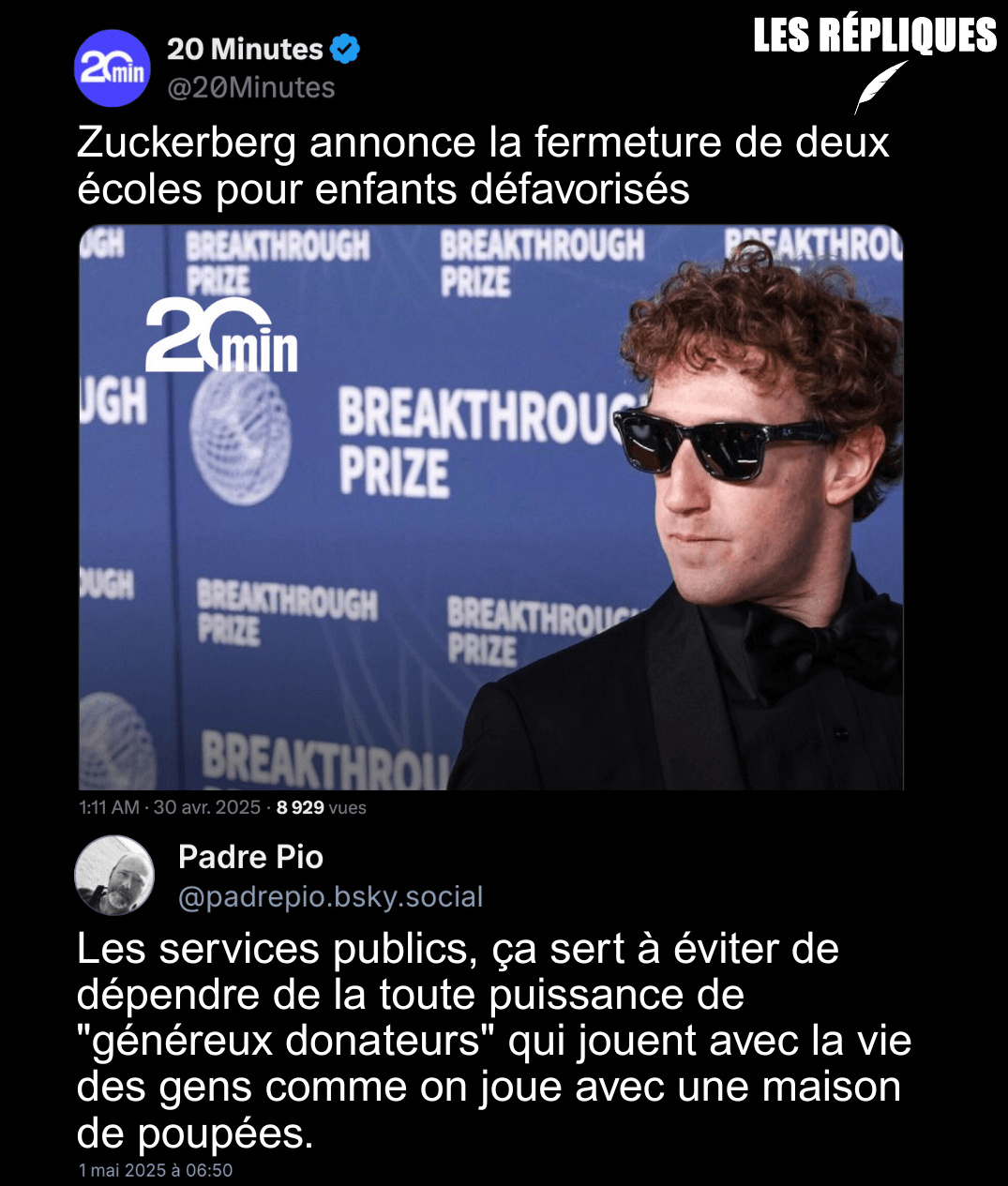
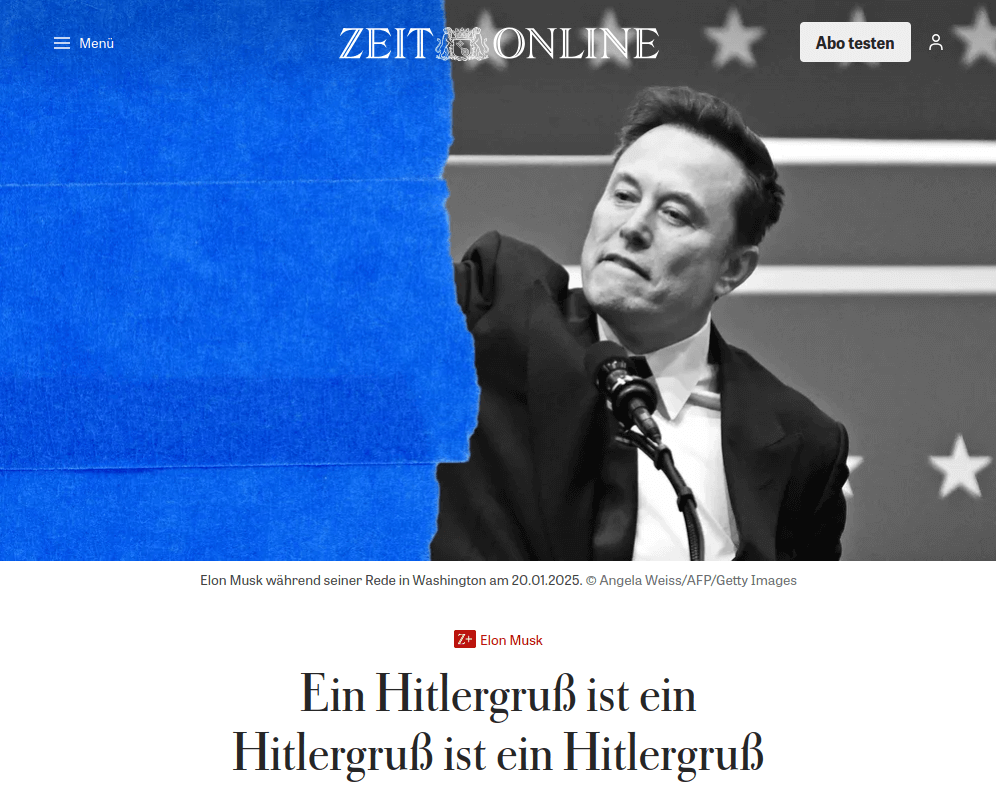
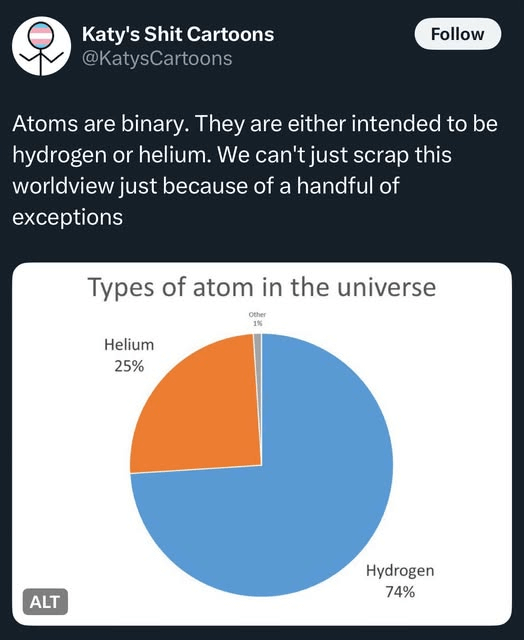
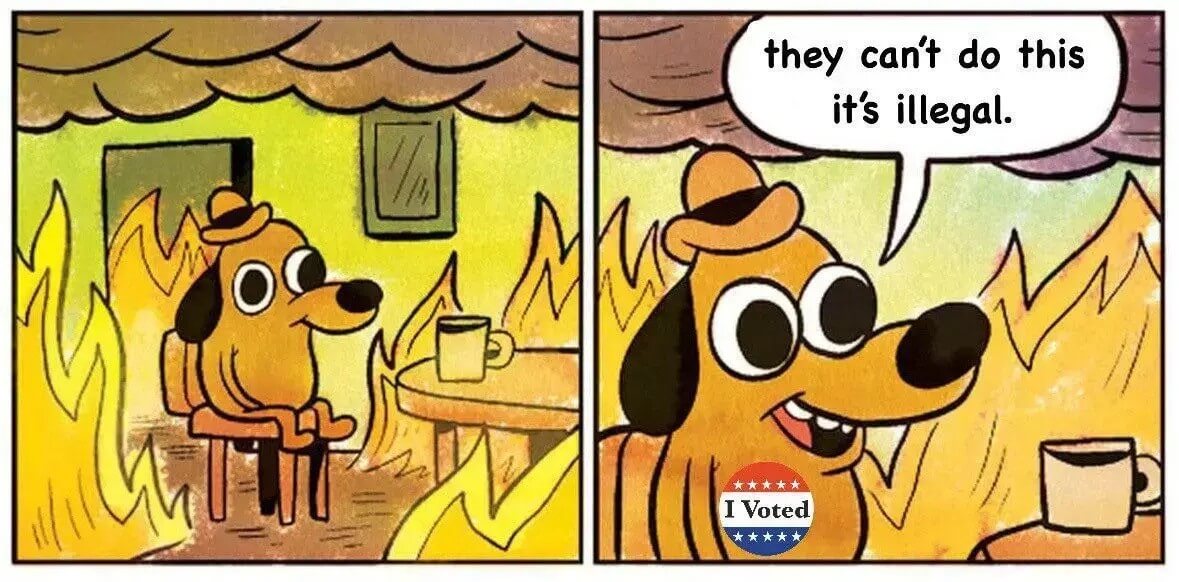
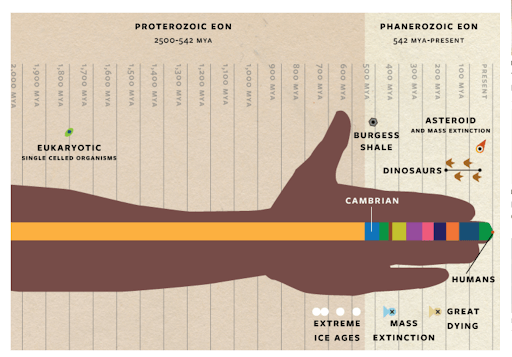
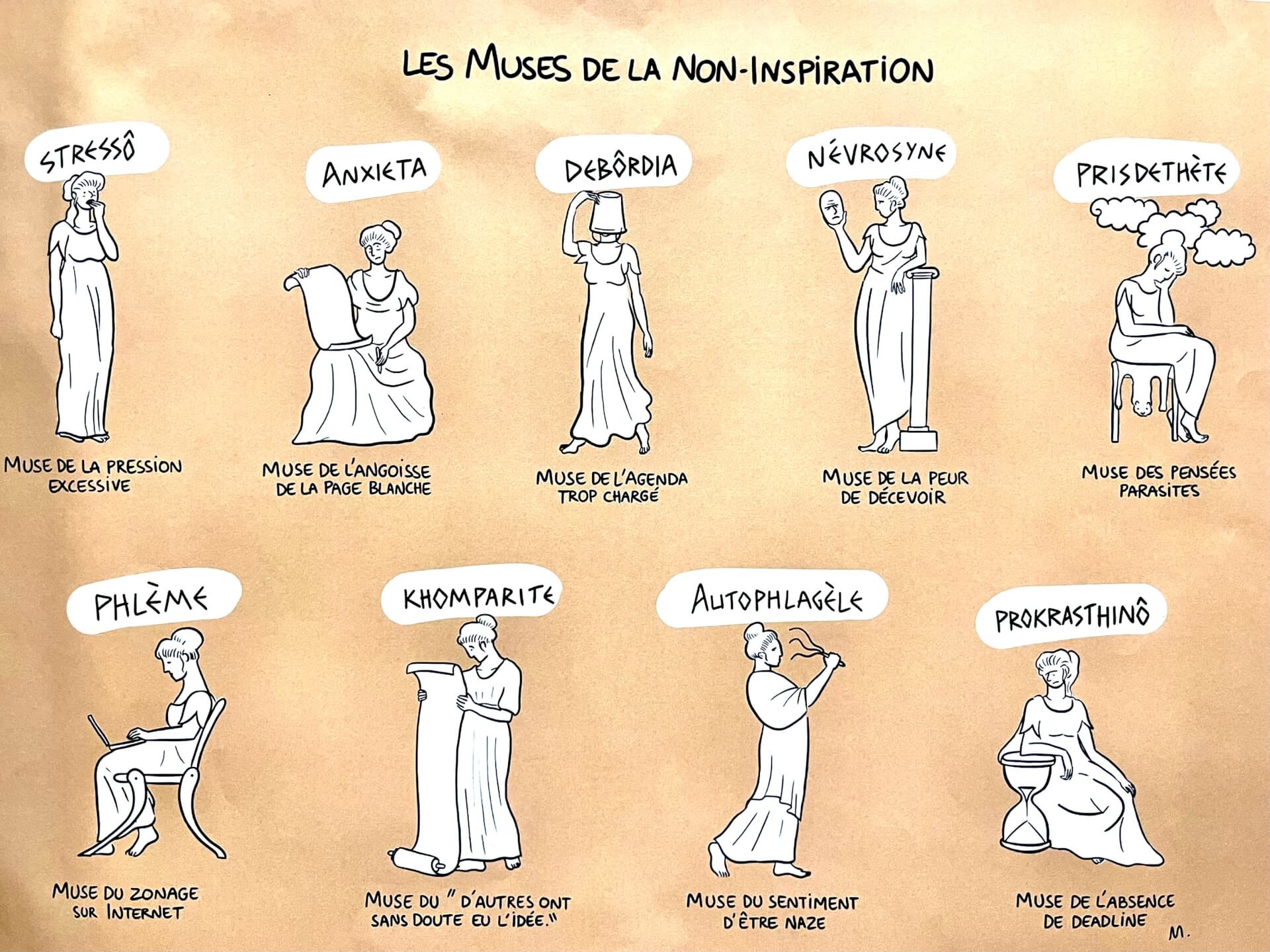
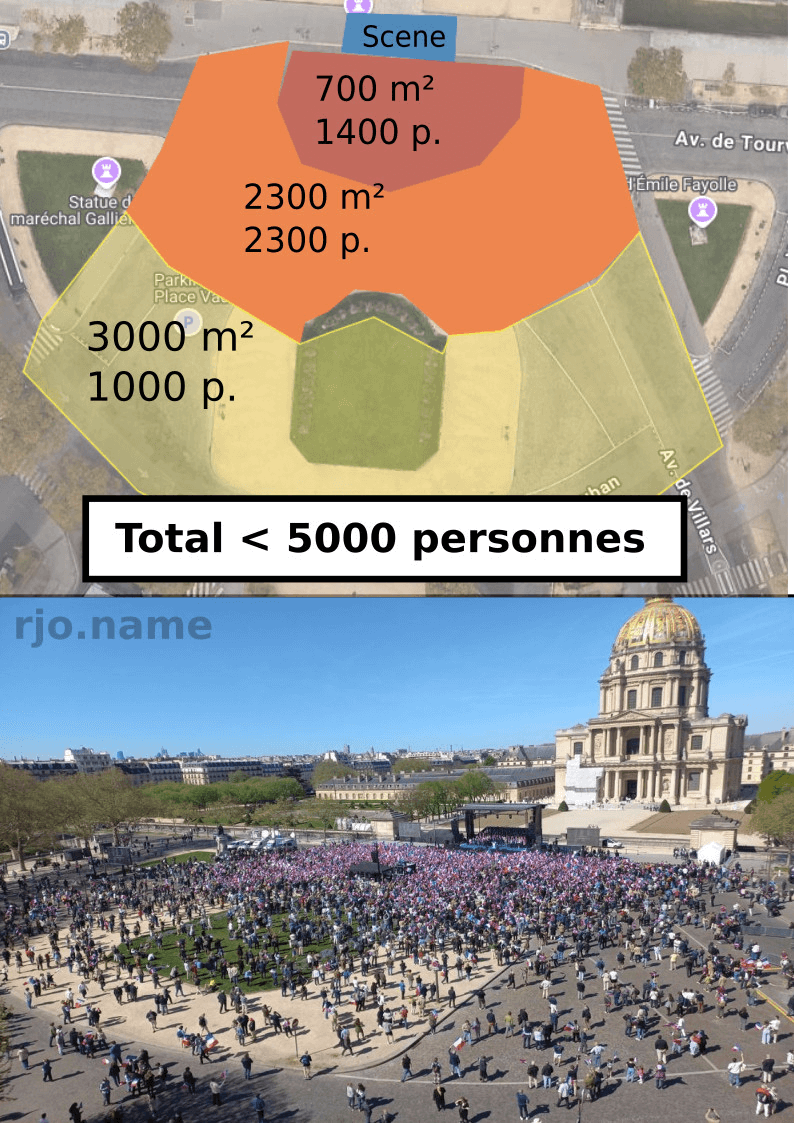
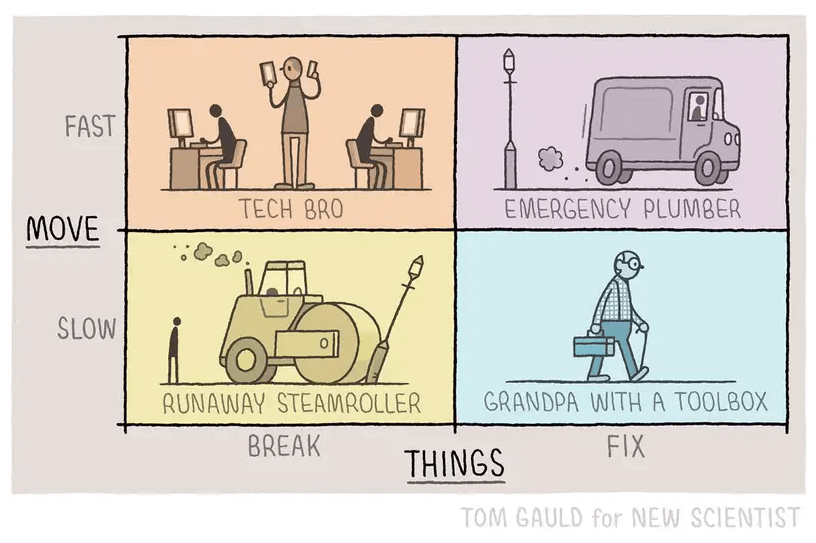
Les BDs/graphiques/photos de la semaine
- Promis
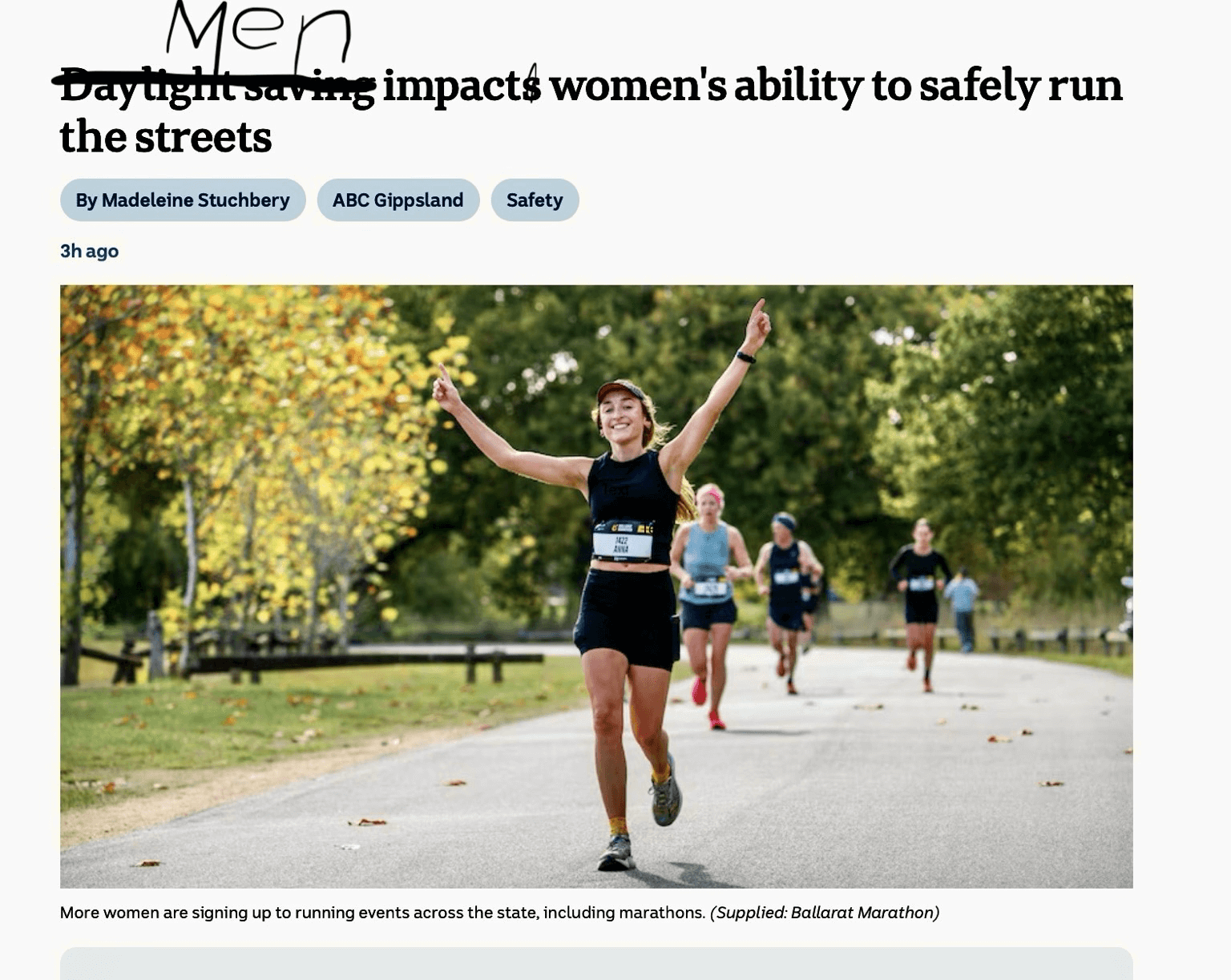
- Macron

- Trop longtemps
- Le beta rame
- Séparer
- Souvenir
- Assistanat
- Kleptocratie
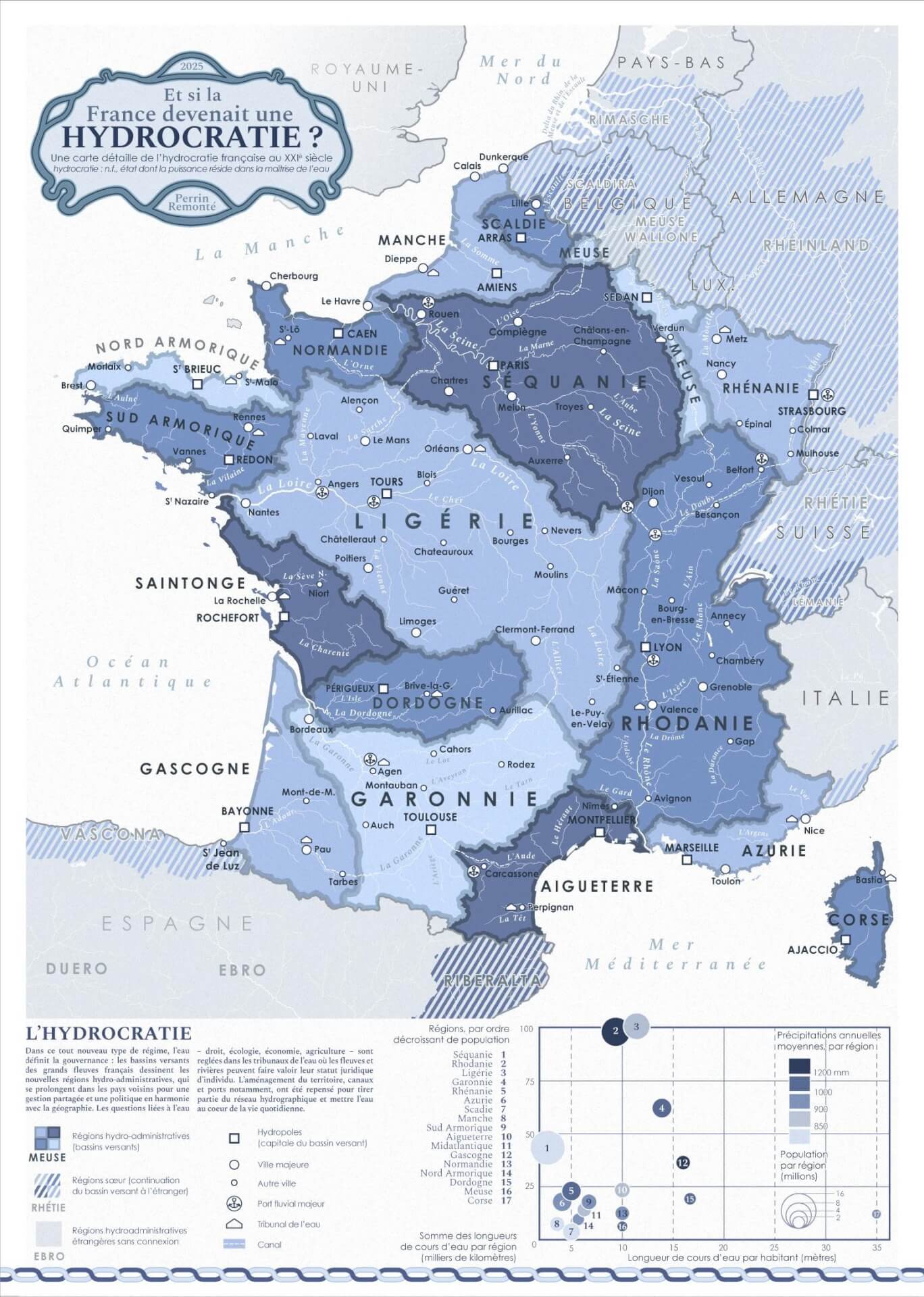
- Hydrocratie
- Bio
- Eurovision
- Croissance
- Yachts
- Inadmissible
- Logic
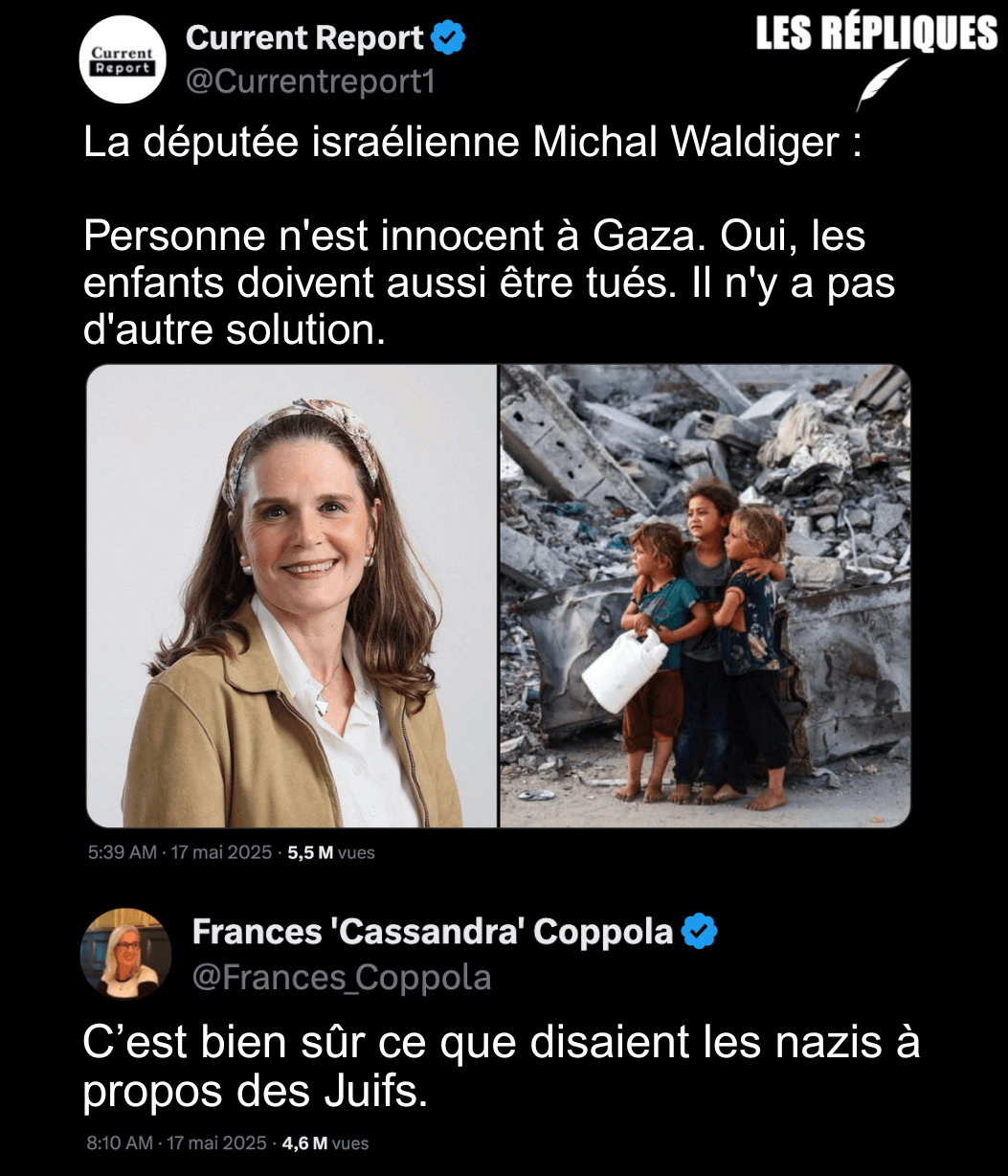
- Gaza
- Nationalism
- Guerre
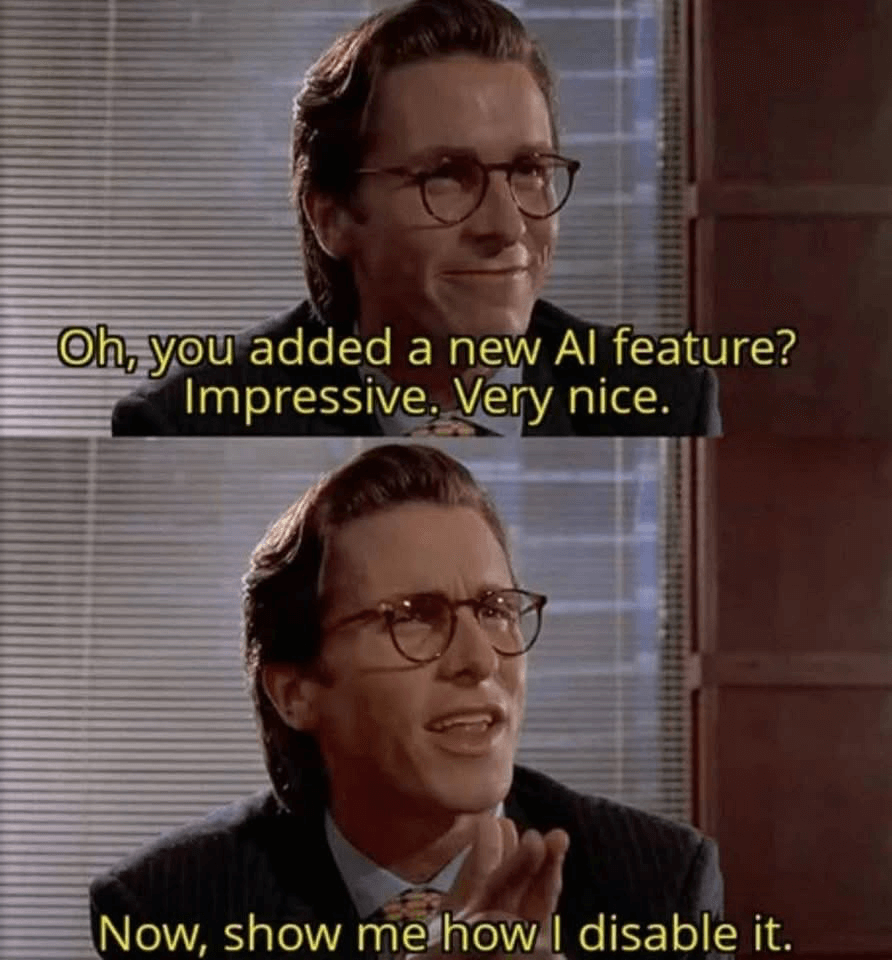
- New feature
- Psy
- AI
Les vidéos/podcasts de la semaine
- Au Poste du jour : Bayrou n’a rien vu à Bétharram : son odieuse audition à l’Assemblée nationale (auposte.fr) – lien direct vers la vidéo PeerTube (video.davduf.net)
- Gabriel Zucman et Camille Étienne répondent à Macron concernant la “taxe Zucman” (tube.fdn.fr)
- À propos de Peter Thiel (en anglais sous-titré en anglais) (tube.fdn.fr)
- Argentine, reconstruire la résistance (audioblog.arteradio.com)
- Le genre du capital. Dépossession des femmes et reproduction du patriarcat par la famille et le droit (spectremedia.org)
- Le sens du poil (soundcloud.com)
Les trucs chouettes de la semaine
- Thérapies de conversion : la pétition dépasse le seuil du million de signatures, et la France y est pour beaucoup (huffingtonpost.fr)
- Edinburgh Tour Replacing Harry Potter Tours with LGBTQ+ History Walks Because of J.K. Rowling Comments (gayety.com)
- Mais pourquoi Einstein tire-t-il la langue ? (nouvelobs.com)
- Masaki Kashiwara reçoit le prix Abel 2025, le « Nobel des maths » (theconversation.com)
- Chimpanzee drumming may give clues to the roots of rhythm (science.org)
- La NASA réussit un sauvetage désespéré de Voyager 1, une sonde envoyée en 1977 (huffingtonpost.fr)
Les ingénieur·es de la Nasa ont miraculeusement réanimé les propulseurs principaux de la sonde Voyager 1 pourtant considérés comme inutilisables depuis 2004. Une mission d’autant plus importante puisqu’elle devait être achevée avant le 4 mai si l’agence spatiale ne voulait pas perdre sa sonde la plus éloignée de la Terre.
- Un nourrisson atteint d’une maladie génétique ultra-rare reçoit un traitement personnalisé inédit (lemonde.fr)
Un nourrisson atteint d’une maladie génétique aussi rare que sévère a bénéficié aux Etats-Unis d’une technique innovante, appelée édition de base, capable de corriger une seule lettre de son ADN. Cette avancée ouvre de nouvelles perspectives pour le traitement d’autres pathologies ultra-rares.

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).












































































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}