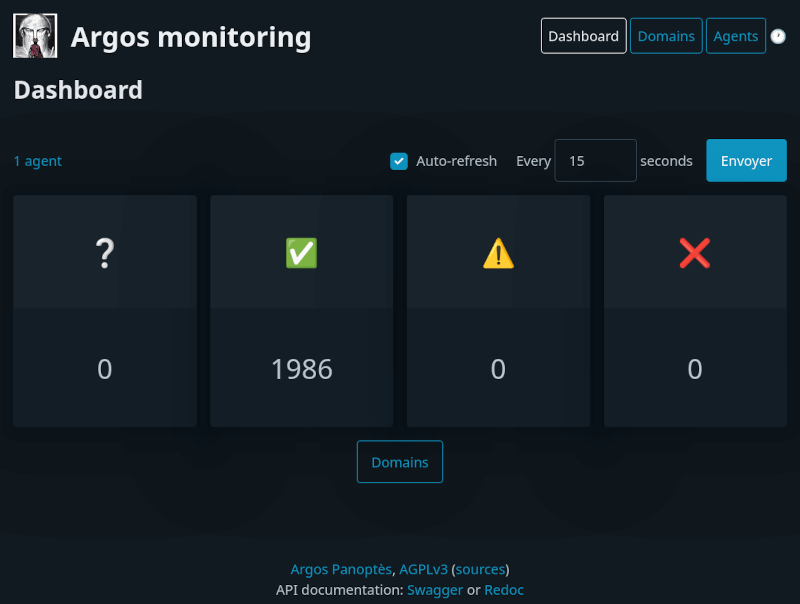
Pour Framaspace, Framasoft a fait développer un outil de supervision de sites web nommé Argos Panoptès (ou juste Argos pour aller plus vite).
Développé par Alexis Métaireau, développeur entre autres du générateur de site statique Pelican, et de l’outil de gestion de dépenses à plusieurs « I Hate money » (repris dans l’app cospend sur Nextcloud), le besoin a été défini par Luc Didry, l’administrateur système de Framasoft.
Luc et Alexis répondent à nos questions dans cet interview, pour plus d’information concernant Argos vous pouvez consulter l’article dédié.
Bonjour à tous les deux :) Ici on connaît déjà Luc puisque c’est notre admin sys préféré, mais Alexis, peux-tu nous dire qui tu es pour le framablog ?
Alexis : Bonjour, Framasoft, et merci pour la discussion ! Et bien, c’est parti pour l’exercice de la présentation alors.
Je suis un développeur de bientôt 40 ans, intéressé par les dynamiques collectives, le logiciel libre et la protection des données personnelles, depuis quelques années maintenant. Par le passé j’ai pu publier et maintenir quelques outils comme Pelican, un générateur de sites statiques et I hate money, pour gérer les dépenses partagées. J’ai travaillé quelques années pour Mozilla sur la partie synchronisation et chiffrement des données (Firefox Sync, Kinto) et sur quelques autres outils.
J’ai quitté le développement « pro » entre 2018 et 2023. Durant ces années j’ai eu la chance / le privilège de pouvoir monter une brasserie sur Rennes avec un ami. Nous avons essayé de faire vivre les valeurs de la collaboration (plutôt que celles de la compétition). Cela est resté très proche des valeurs du logiciel libre, nos recettes et les plans de nos machines étant par exemple publiés sur notre site web.
À l’été 2023 j’ai décidé de quitter la brasserie pour à la fois refaire du développement et travailler sur les outils de la prise de décision collective, et la gestion des conflits dans les collectifs. C’est à ce moment que nous sommes rentrés en contact avec Luc pour travailler sur Argos.
Pouvez-vous nous présenter l’outil Argos sur lequel vous avez travaillé ? À quel besoin répond-il pour Framaspace ?
Alexis : Argos est un outil de supervision de sites web. L’idée est assez simple : surveiller que les sites vont bien, et générer des alertes quand c’est utile, en envoyant des notifications par email ou autre.
La spécificité d’Argos est de pouvoir gérer un nombre de sites important. Framaspace, en grossissant, expose pas loin de 900 domaines au public, qui parfois tombent en panne. Je crois que le réel besoin derrière Argos était de simplifier la vie de Luc (vous saviez qu’il n’y avait qu’un seul adminsys chez Framasoft ? ! !) et de lui permettre d’avoir une meilleure vision globale de l’état du service.
Les vérifications concernent les statuts du site web, mais aussi l’état des certificats SSL, par exemple, et quelques vérifications spécifiques.
Luc : On surveillait déjà plus de 200 sites via notre outil de supervision (Shinken), mais celui-ci, avec toutes les autres sondes de supervision de notre infrastructure, avait bien de la peine à repasser toutes les 5 minutes sur les sites. Ce qui faisait qu’on pouvait se rendre compte qu’un site était tombé au bout de trop de temps.
Avec Framaspace, je savais que j’aurai des centaines (et à terme des milliers) de sites à surveiller en plus, sachant qu’un site est la cible de plusieurs vérifications, comme dit par Alexis. Il fallait donc un outil dédié.
Les outils existants comme statping-ng ou Uptime Kuma présentent un défaut rédhibitoire : vouloir afficher l’état de chaque site en même temps sur l’interface web. Ça va bien quand on a quelques sites, pas quand on en a des centaines (l’outil peine à envoyer les données de centaines de sites).
C’est de là qu’est née l’idée d’Argos, qui a le bon goût de n’afficher qu’un résumé de l’état des sites par défaut.
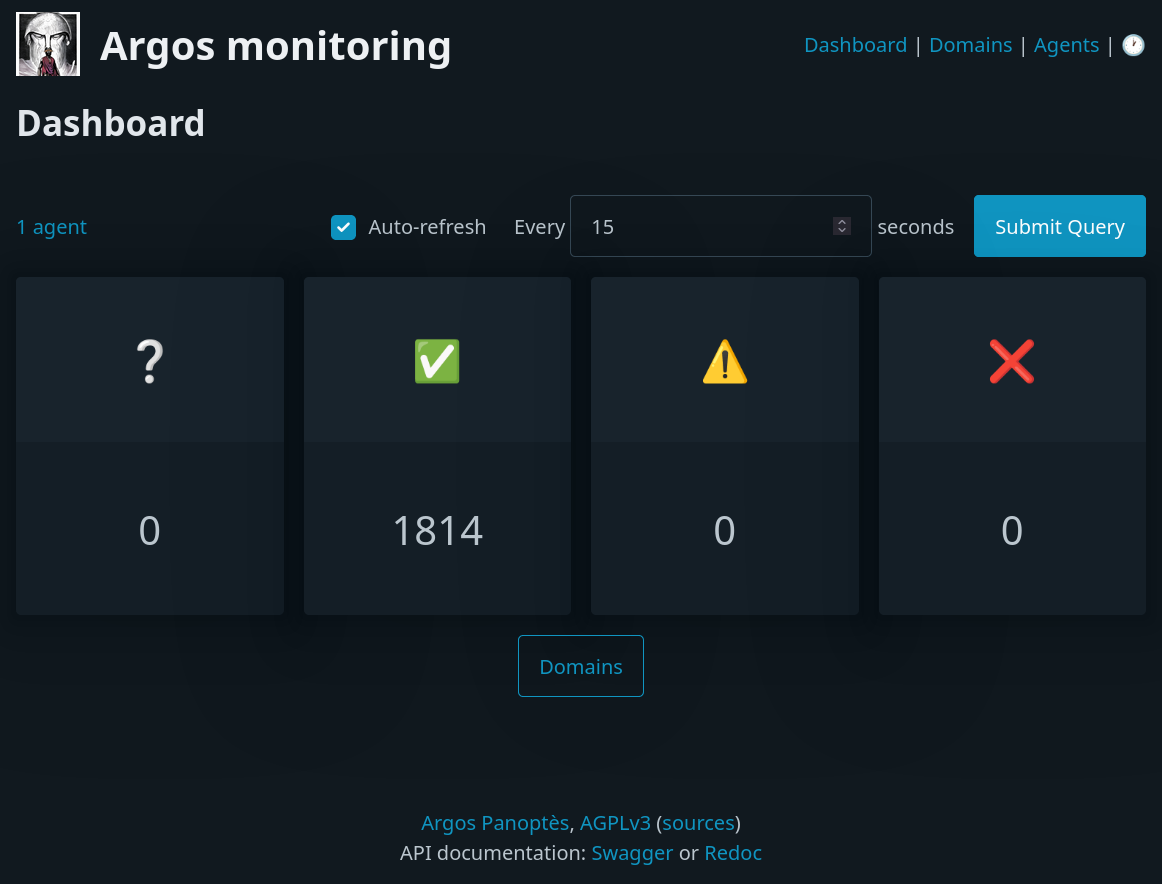
Capture d’écran de la page de statut d’Argos
Si on regarde de plus près les coutures, on voit que c’est développé en langage Python avec une base de données en PostgreSQL. Laissez-moi deviner : Alexis a choisi Python et Luc a choisi PostgreSQL ?
Alexis : Ah, je vois que tu nous connais un peu, mais figure toi que même pas ! J’aurais aimé plaider coupable pour le coup, mais Luc cherchait spécifiquement quelqu’un qui savait faire du Python, et c’est comme ça qu’on s’est rencontré. J’ai proposé d’utiliser le framework FastAPI à la place de Flask parce que ça nous permettait de faire de l’asynchrone de manière plus simple, et d’utiliser les fonctionnalités de typage de Python.
Luc : Pour Framaspace, j’ai été plus ou moins obligé de faire du Python car Salt, l’orchestrateur utilisé pour déployer les espaces est en Python : je pouvais, en utilisant ce langage, l’utiliser comme une bibliothèque, sans utiliser de bidouilles sales.
Comme Argos a été créé dans le cadre de Framaspace, j’ai voulu garder le même langage de programmation, pour avoir un tout cohérent.
Python n’est pas un langage si pire que ça. Il n’est pas amusant, mais ça fait le job. Peut-être aussi que je vieillis : j’utilise de plus en plus Python pour des scripts. Peut-être qu’écrire des scripts ne m’amuse plus, et que je veux les écrire vite pour passer à autre chose.

La question habituelle de libriste : pourquoi avez-vous choisi de développer un outil dédié, il n’existait pas d’outils libres pour de la supervision ? Quelles sont ses spécificités ?
Alexis : Je te laisse répondre Luc, c’est toi qui a affiné le besoin :-)
Luc : Ah bah zut, j’ai déjà répondu au-dessus 😅
L’avantage d’avoir notre propre outil nous permet aussi de le tordre pour nos besoins spécifiques. Ainsi Argos envoie-t-il des notifications à notre serveur Gotify. Intégrer un tel canal de communication dans un outil existant aurait pu prendre du temps (comprendre le code, faire une PR, attendre une release…).
En lisant la doc, ça a l’air tout simple à utiliser par rapport à d’autres outils ! ! Comme administrateur⋅ice système du dimanche après-midi, si je veux surveiller l’état de mes sites, est-ce qu’il y a des pièges ou des choses à savoir ?
Alexis : Je pense que ça pourrait tout à fait permettre de surveiller l’état de quelques sites, bien que peut-être surdimensionné. Argos a besoin de lancer un serveur, une base de données et des agents. Est-ce bien utile pour un⋅e adminSys du dimanche ? Peut-être !
Luc : Franchement, je pense qu’il peut être utilisé aussi bien par une grosse organisation que par un·e adminSys du dimanche. La configuration est simple, l’installation pas très compliquée, et il n’a pas l’air de consommer beaucoup de ressources.
Alexis tu étais en mode prestation pour développer, comment s’est passée la relation avec Framasoft ?
Alexis : Franchement, c’était une surprise totale, et un plaisir du début à la fin. On a d’abord pu se faire quelques appels avec Luc pour clarifier les besoins, je me suis retrouvé avec une liste de fonctionnalités de base, et j’ai avancé comme ça.
Quand j’avais besoin j’ai pu échanger avec Luc qui était toujours assez réactif, et j’ai pu lever quelques blocages. J’ai beaucoup apprécié répondre à un besoin concret, en ayant l’utilisateur final au bout du fil pour clarifier les choses.
Par la suite, on a pu se faire quelques sessions ensemble, à la fois de présentation de l’outil, puis de pair-programming pour accompagner Luc sur certains aspects quand c’était utile, l’idée étant que ce soit lui qui prenne la main sur le projet.
C’était en fait ma première mission en tant que « prestataire », je crois que je suis très bien tombé !
Luc : Pareil de mon côté, c’était très agréable de bosser avec toi !
Est-ce que vous pensez que ça peut être utilisé dans d’autres contextes que Framaspace ?
Alexis : je pense que ça peut être utilisé dans d’autres contextes bien sûr. Je pense aux « fermes de sites », comme par exemple ce que peut faire NoBlogs en Allemagne, mais de manière générale c’est utile d’avoir un outil simple d’accès pour faire de la supervision. Bosser là-dessus m’a donné envie de permettre de faire de la supervision « en tant que service », pour des collectifs pour qui ce serait utile, mais… j’imagine que c’est une autre histoire.
Luc : Carrément ! Pas seulement pour des fermes de sites mais partout où on a besoin d’une supervision qui passe très régulièrement. On peut avoir des vérifications effectuées toutes les minutes, ce qui peut être utile sur des sites qui ne doivent pas tomber. Et un grand nombre de sites ne devrait pas faire peur à Argos : on peut multiplier le nombre d’agents (le logiciel qui s’occupe d’effectuer les vérifications et d’en remonter le résultat au serveur), et le choix de PostgreSQL comme base de données a (aussi) été fait parce que c’est un SGBD robuste qui peut encaisser de la charge de travail.
Et est-ce que vous imaginez une suite, avec une feuille de route ou des invitations à contribuer ?
Luc : Il y a déjà des idées de développements futurs pour améliorer Argos, mais ça n’est pas urgent : la première version est déjà tout à fait fonctionnelle.
Alexis : J’aime bien l’idée de ne pas avoir de feuille de route trop précise pour le futur, ce qui nous permet de se concentrer sur des besoins réels et de ne pas en faire une usine à gaz. Si vous l’utilisez et que vous avez des retours à faire, ou bien si vous souhaitez contribuer, n’hésitez pas. C’est pensé pour être simple à étendre, donc n’hésitez pas à jeter un œil et à proposer des changements.
Si vous avez encore des choses à dire :)
Alexis : Coucou Numahell, chouette de te recroiser par ici après ces quelques années :-)
Luc : Merci à toi, Alexis, pour le temps bénévole que tu as consacré à Argos après ta prestation !
Pour aller plus loin