A new application for Framaspace : OwnershipTransfer
Still more features on Framaspace ? Yes ! At the moment, we’re spoiling the users of this service, with the integration of quite a few features like the Forms and Tables applications, but also the ‘Intros’ app developed by Val, our summer intern. And because it’s Val, it’s festival (shameful rhyme !) : just before leaving us for a well-deserved holiday and a final year of studies, he delivered a new ‘Ownership Transfer’ application that will make life easier for administrators of Framaspace spaces.
Hi Val, we’re not going to ask you to introduce yourself, as you already did in the previous interview. We’ll just remind you that you’re doing an internship at Framasoft from the beginning of May to the end of August 2024, with the aim of developing tools to support Framaspace, and therefore Nextcloud free software.
Hi ! Check out my previous interview to find out more about me ! I introduce Intros, a Nextcloud app to help users get to grips with Framaspace.
At the end of the interview, I mentioned I was working on another Nextcloud app, OwnershipTransfer. Back then things were only getting started, but I cooked, and now it’s ready.
OK, so let’s talk about the OwnershipTransfer App. What’s it for ? Who is the target audience ?
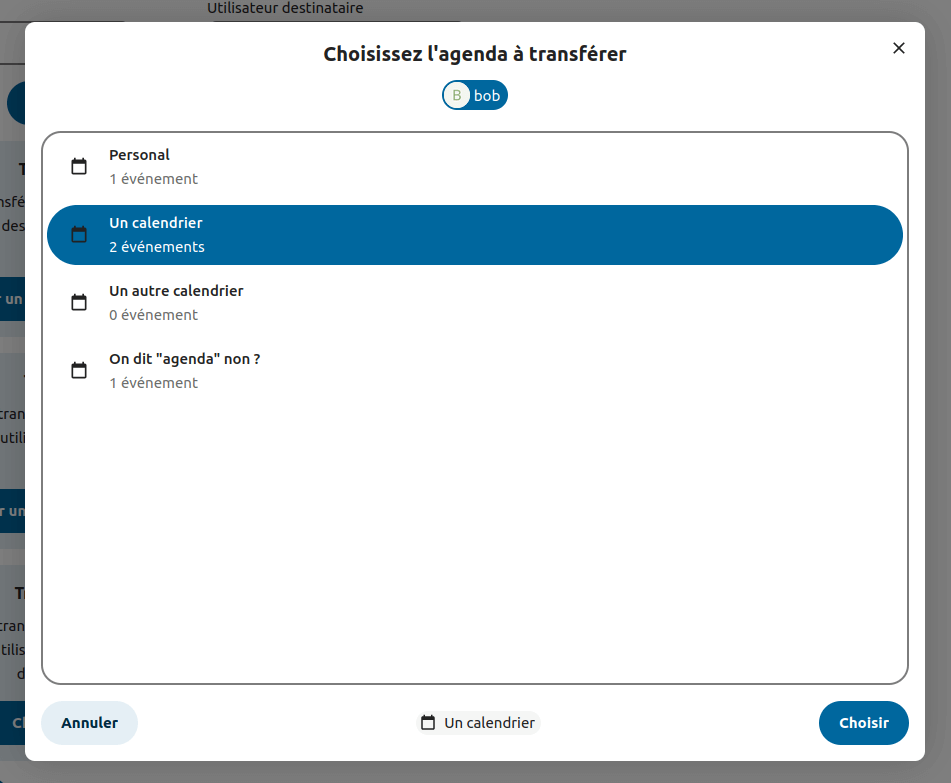
As mentioned in the previous article, OwnershipTransfer makes it possible to transfer data from one user to another in Nextcloud. For example, when someone leaves an association that uses Nextcloud (say, on Framaspace 😏), it can be useful to move their files to another user before deleting their account. You could avoid losing important archives, invoices… The same goes for calendars or address books.
Well worry no more, OwnershipTransfer (or « OT » from now on in this article) does all that. It allows Nextcloud admins to transfer data from whoever to whoever. Initially mostly designed for files, I extended it to calendars and contacts transfer.
OT allows a transfer of all the data, but also a more fine-grained choice. One can choose the calendar, address book or folder they want to transfer, so they don’t end up with someone’s holidays pictures in their files.
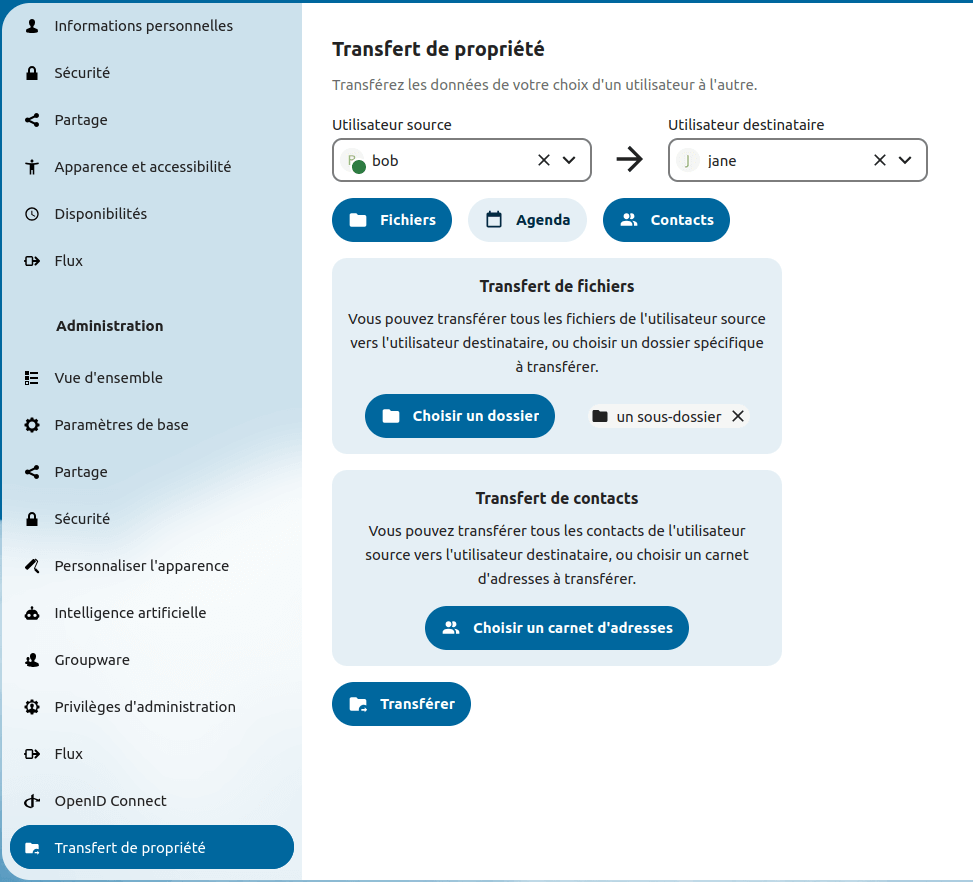
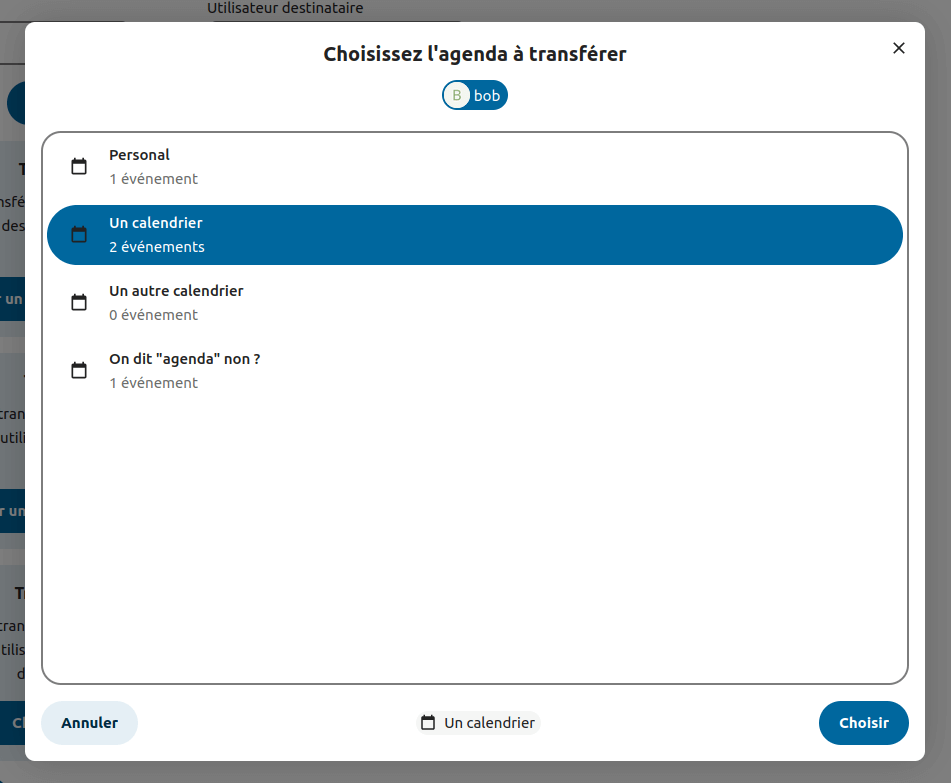
But… didn’t this feature already exist in Nextcloud ?
It did, but not the way we wanted it to.
Nextcloud already allows transferring your own files to another user, with a small graphical interface in the user settings section. You can only transfer your own files to another user, but not choose a source user : this isn’t suitable for an instance admin who would want to move files from one user to another.
An instance admin can also transfer files or calendars from one user to another, with an OCC command. OCC is Nexctloud’s CLI, via which admins can handle some server settings. You can only use it from the command line in a terminal, which to most human beings is… cryptical.
In short there are existing working solutions, but not with a simple graphical interface for admins. This is especially an issue in « Nextcloud farms » (an organization hosting Nextcloud instances for a lot of clients at once) like Framaspace, because admins don’t have access to the CLI in this case.
Technically, how does it work ?
Since it’s integrated with other Nextcloud apps, OT is heavily relying on existing Nextcloud APIs. The app also uses adapted parts of Nextcloud’s code. For example, I use the code from the existing files transfer feature, which I modified to fit with our requirements. The same goes for the calendar transfer.
However, I add to implement the contacts transfer, since it is not available in Nextcloud (not even through a cryptic CLI). It looks a lot like the calendar transfer, since both of them are based on the WebDAV protocol, so I had an example to work with.
The interface is built with Nextcloud’s Vue components, of course. They are pretty pleasant to use, and new ones are often released. It allowed me to build a complete graphical interface in no time, while staying consistent with the rest of Nextcloud’s UI.
Have you encountered any technical or organisational problems ?
Since Nextcloud’s documentation hasn’t miraculously grown since last time, I had to wander around in Nextcloud’s source code to find the functions needed. I could almost make a hobby out of that. Almost.

At least the features exist in Nextcloud already, so adapting them wasn’t the most difficult thing ever. I could also rely on tcit’s advice, co-director of Framasoft and Nextcloud contributor. In short : I write code, he looks at it, says « cool thing, but not scalable », and I correct it.
Scalability was the most common problem. It always works on my small test environment with 5 accounts and 7 folders, but it should also (and most importantly) work on big Nextcloud instances with lots of files. For example, the files transfer can take a lot of time and resources : it has to move all the files from the source to the destination folder, which takes more or less time depending on the amount of files to move and the underlying storage type. Because of that, it is handled in the background : instead of launching it upon receiving the request, it is placed in a jobs queue that the server periodically handles.
Calendar and contacts transfers do not have this issue : they only consist of a simple SQL query to change the right property on the right element. This operation is fast, so it can be handled in the foreground.
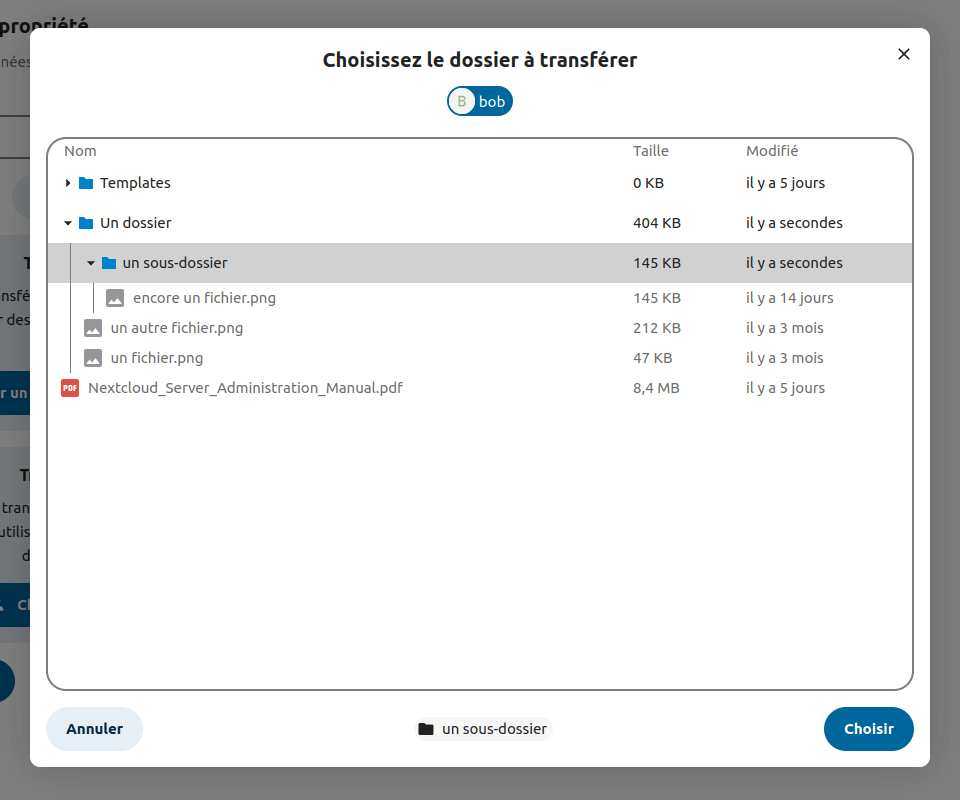
Besides the actual transfer, building the interface was also challenging. The app allows the admin to choose which element will be transferred, so they need an interface to choose it. For calendars and contacts, it’s fairly simple : with Nextcloud’s components, I could easily build a list of calendars or address books. But for files, things are getting complicated : we need a whole tree-style view to show the subfolders’ content.
Luckily, I’ve got back up. Romain, former fellow INSA Lyon student (in Telecom, just like me !) and former Framasoft intern, worked on Sorts a few years ago. The goal was to make an app to enhance Nextcloud’s file search, mostly with filters. And Sorts has something I was really interested in : a tree-style files view. Exactly what I needed.
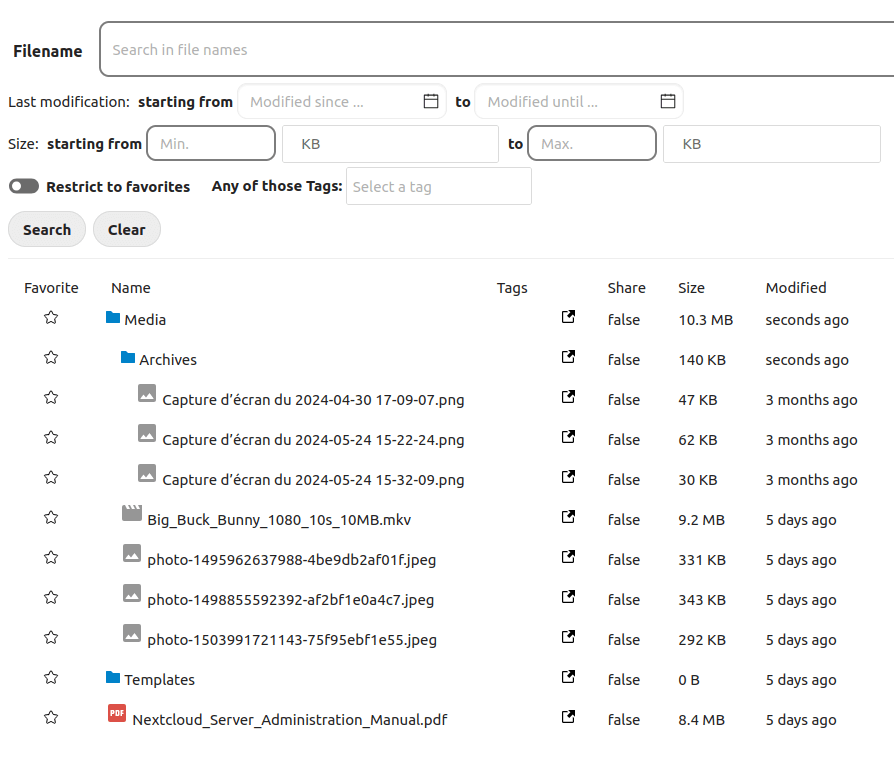

After a few tweaks here and there in Sorts’ code, which wasn’t necessarily easy, its tree-style view perfectly integrated with OwnershipTransfer. It helped a lot and saved a lot of dev time, and I could even improve it a bit with some lines to better view the current folder and some sharing icons.
Now that your internship is coming to an end, and you’ve been « eating » some Nextcloud for the past 6 months, what are your potential takes on this software ?
It’s rant time !
Anyways, besides the rant and all the things I could blame on Nextcloud (like its lightweight documentation, its occasional slowness or its imperfect UI), its a very functional software, and it’s all that matters for pretty much everyone. It could be better (and it’s already happening !), but I find it to be working just fine for most typical usages. I’ve been using it for 2 years on a Raspberry PI to backup my files and photos, and I’ve never had any major issues with it.
However, its collaborative features can definitely get better (things like multiple people writing on the same text or calc document at the same time), especially since they are very popular among the people who use Nextcloud. These features exist, but they are typically hard to use, especially the first time, and poorly optimized. So when I see Nextcloud bragging about how they now have AI integrated (which I think most people don’t find that useful anyway), while opening a shared file sometimes still causes a mess… I think they could focus on more important things. But I guess you do need something to make it look shiny.
We’ve been very very pleased and satisfied to work with you over the last few months ! Any final words ?
I was delighted to work at Framasoft ! I’ve learned a lot through this internship, and I want to thank the association again for its welcoming and comfortable working conditions.
Right now it’s time to relax, for me at least (before going to « class » again, but don’t mention it), and then to go back to work on my final internship at the beginning of next year ! I’m just saying, of course ;)
Main links for Ownership Transfer :
- Link to Ownership Transfer in the Nextcloud application shop : https://apps.nextcloud.com/apps/ownershiptransfer
- Link to the Ownership Transfer code on the Framagit forge : https://framagit.org/framasoft/nextcloud/ownershiptransfer







{kind=link}
{kind=link}
{kind=link}