Pétitions, Tableau blanc, Tricount-like, etc… De nouveaux services Framasoft sont en préparation, et des services existants sont en rénovation. On vous dit tout, et notamment pourquoi nous avons besoin de vous.
Cet article étant particulièrement long, on vous en propose ici un court résumé.

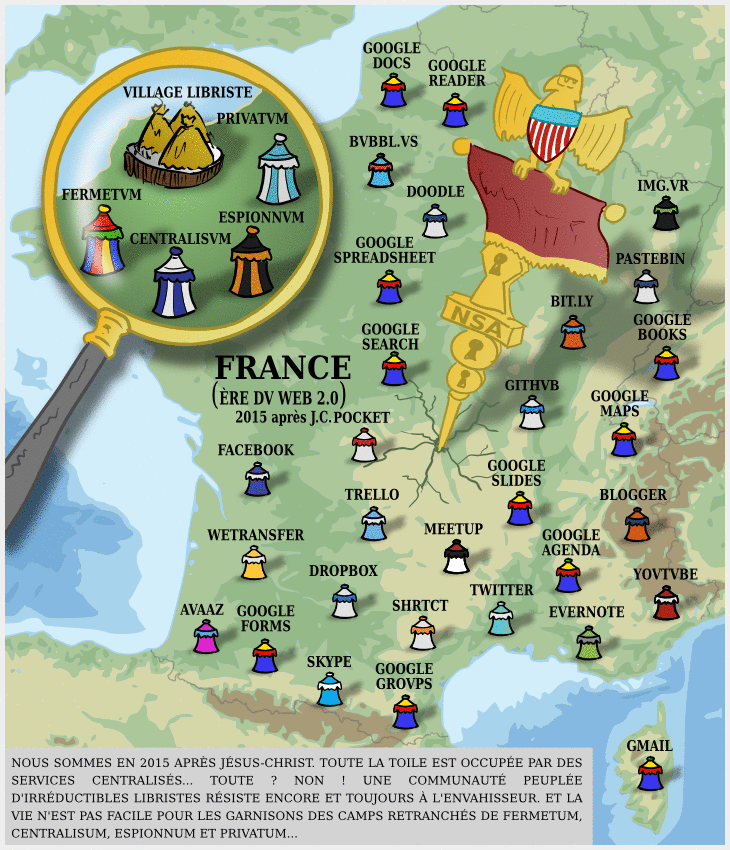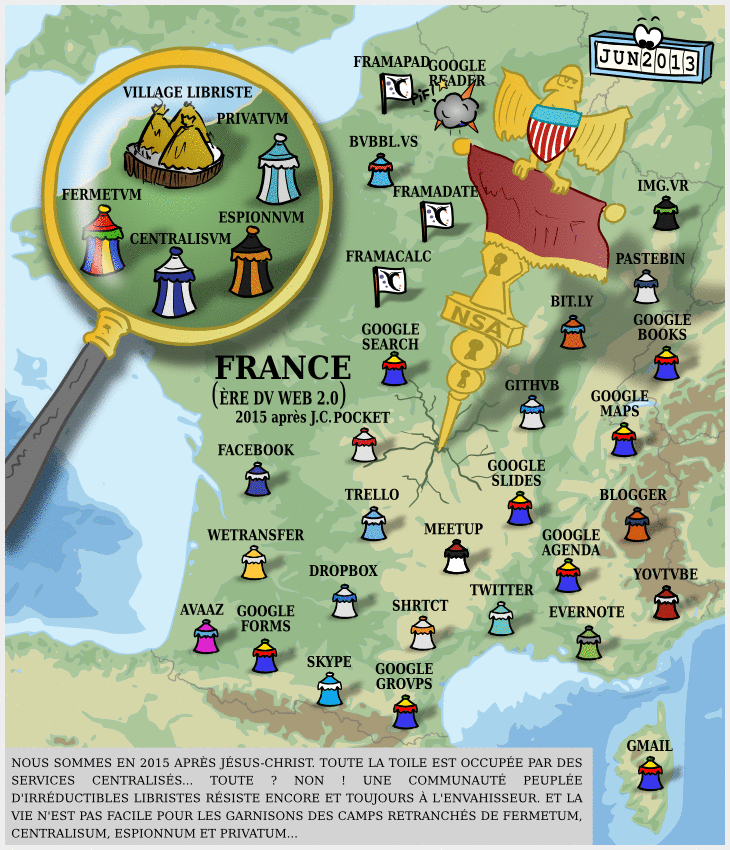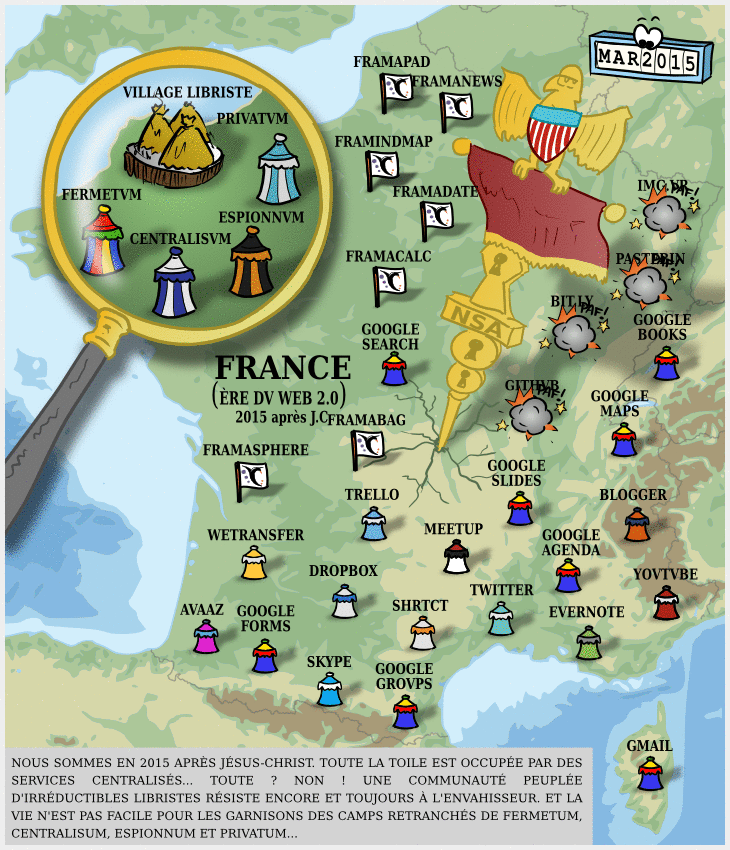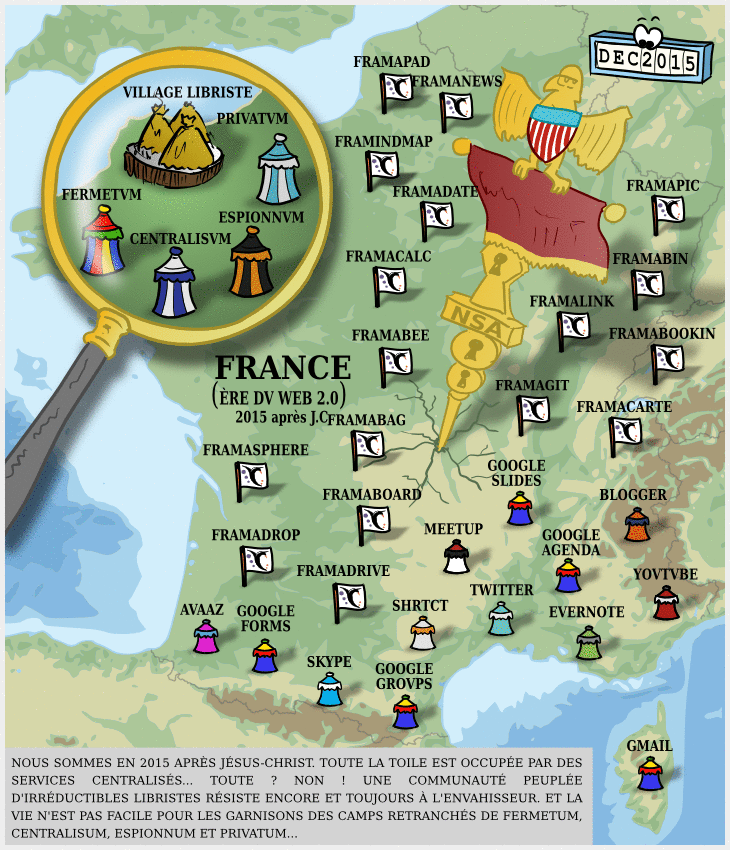
Carte Dégooglisons Internet 2016
Il y a dix ans, nous annoncions notre campagne Dégooglisons Internet, qui fut un succès relativement retentissant : en couplant le plaidoyer (c’est à dire le fait de dénoncer la « triple domination » des GAFAM et leur toxicité) avec la mise en place de solutions concrètes, cette campagne de Framasoft a marqué les esprits, et nous pensons même en toute humilité qu’elle a été parfois un socle pour apporter une réponse structurée à l’envahissement des Big Tech dans nos vies.
Dans la foulée (en 2016), nous impulsions le collectif CHATONS, qui compte aujourd’hui plus de 80 structures.
Puis, quelques années plus tard, nous fermions une partie des services Dégooglisons. Les raisons étaient nombreuses (au moins 10 !) mais il y avait l’envie d’arrêter la course à l’échalote de la sortie de services, puisque nous en avions publié quasiment un par mois pendant trois ans. Notre épuisement (surtout post COVID) était alors à la hauteur de la pression du public.
Des CHATONS autonomisés pour des GAFAM atomisés ?
En parallèle le collectif CHATONS continuait sa montée en puissance. Coordonné par Framasoft, qui finançait son animation, nous estimons que fin 2023, l’association Framasoft a investi environ 100 000€ (essentiellement en temps de travail salarié) dans la mise en place de ce collectif.
Alors, certes, comme tout projet collectif, celui-ci comporte des faiblesses et des failles. Mais cette association de fait est réellement un succès à de nombreux points de vue :
- la marque « CHATONS » est connue et reconnue par de très nombreux utilisateur⋅ices, qui peinaient à retenir les identités de nombreuses structures locales ;
- le fait d’avoir un projet structurant a encouragé de nombreuses personnes à créer leur propre organisation. Ces personnes se sont senties légitimes à créer ou rejoindre des associations locales. Avoir réussi à faciliter ce « faire ensemble » est une véritable fierté pour nous ;
- l’entraide entre CHATONS est une réalité, comme l’atteste le forum du collectif.
Le collectif est maintenant autonome et auto-géré depuis plusieurs mois, Framasoft étant depuis redevenu un « simple membre ».
Ne pas regarder le train du numérique passer
Cependant, en 10 ans, le numérique a bien évolué, et les GAFAM, les NATU, et autres BATX ne sont pas gentiment restées à attendre de se faire démanteler par des CHATONS ou la commission européenne.
Le cloud s’est généralisé, l’usage du mobile s’est imposé que ce soit pour payer son parcmètre ou ses impôts, l’intelligence artificielle participe certes d’une certaine hype, mais elle bouscule et percute aujourd’hui déjà de nombreux usages (et ce n’est qu’un début).
Bref, le numérique est toujours plus présent, et pour le dire clairement, nous, militant⋅es du libre, des communs culturels et d’un numérique émancipateur n’avons gagné quasiment aucune bataille dans la lutte contre un adversaire gigantesque et tentaculaire. Cependant, le simple fait de critiquer, de se réunir, de manifester, de s’opposer, de proposer… est déjà une victoire en soi !
Il convient donc, aujourd’hui de « mettre à jour notre logiciel ». L’expression peut évidemment être entendue dans les deux sens. Mettre à jour notre façon d’agir, mettre à jour l’objet de nos luttes, relever la tête du guidon numérique libriste pour regarder comment le TGV du numérique capitaliste a évolué cette dernière décennie.
Cela s’est traduit par des prises de conscience pour Framasoft ces dernières années :
- le libre est un moyen nécessaire (mais non suffisant) pour aller vers une société libre, mais il n’est pas une fin en soi. Savoir que du logiciel libre équipe des drones larguant des bombes en Palestine ou en Ukraine ne nous réjouit pas (litote) ;
- la centralisation est une source de puissance pour les BigTech, la décentralisation est donc l’équivalent d’un caillou dans leur chaussure. Et dans ce cadre, la fédération (par exemple via ActivityPub) est une réponse pertinente, a minima pour explorer les interstices dans lesquels ces entreprises n’arrivent pas encore à se glisser ;
- il y a une forme de « paradoxe de la tolérance » dans le libre : d’un côté une espèce de « pureté militante » à vouloir du 100 % libre sans reconnaître que le libre est un chemin sur lequel chaque individu ou communauté se situe à une étape qui lui est propre ; et à l’inverse, une réelle difficulté du monde libre à reconnaître que l’autorisation explicite de réutiliser le travail produit par les communautés profite aussi largement aux géants du numériques qui, eux, n’ont ensuite aucun scrupule à mettre des bâtons dans les roues des projets de ces mêmes communautés ;
- nous comprenons et adhérons à l’adage « Tout seul on va plus vite, ensemble on va plus loin. ». Nous croyons fortement dans l’intérêt des processus collectifs. Mais… en vingt ans d’existence, force nous a été de constater que « Ensemble, on va moins vite. » (sauf à être très bien organisé, ce qui n’est que rarement le cas des communautés libristes). Il y a souvent une énergie folle dépensée dans la structuration de nos luttes, souvent due à un impensé : l’animation/coordination est un métier, qui réclame des compétences souvent ignorées ou peu valorisées. Or comme on l’a vu, le numérique « avance » vite. ChatGPT 4 est sorti depuis ~18 mois, et quelle a été, à quelques exceptions près, la réaction du monde libriste ? Un silence plutôt assourdissant au mieux, des moqueries en mode « ça ne marchera jamais » au pire.
Ce sont ces raisons qui nous ont poussé⋅es ces dernières années à développer avec nos petits bras associatifs un logiciel comme PeerTube, ou à proposer des projets comme Emancip’Asso ou Framaspace, qui nous permettent de mettre nos compétences aux services de communautés la plupart du temps non-libristes, mais qui partagent nos valeurs.
Ainsi, dans le contexte social et politique actuel, il nous paraît essentiel de renforcer notre offre de services en ligne à dispositions des collectifs et militant⋅es.
Mais « mettre à jour notre logiciel » peut aussi être entendu d’un point de vue beaucoup plus littéral : il s’agit en effet de mettre à jour les logiciels qui motorisent notre campagne « Dégooglisons Internet », voire d’en proposer de nouveaux au public.
Mettre à jour son logiciel (intellectuel) ou mettre à jour son logiciel (sur son serveur) ?
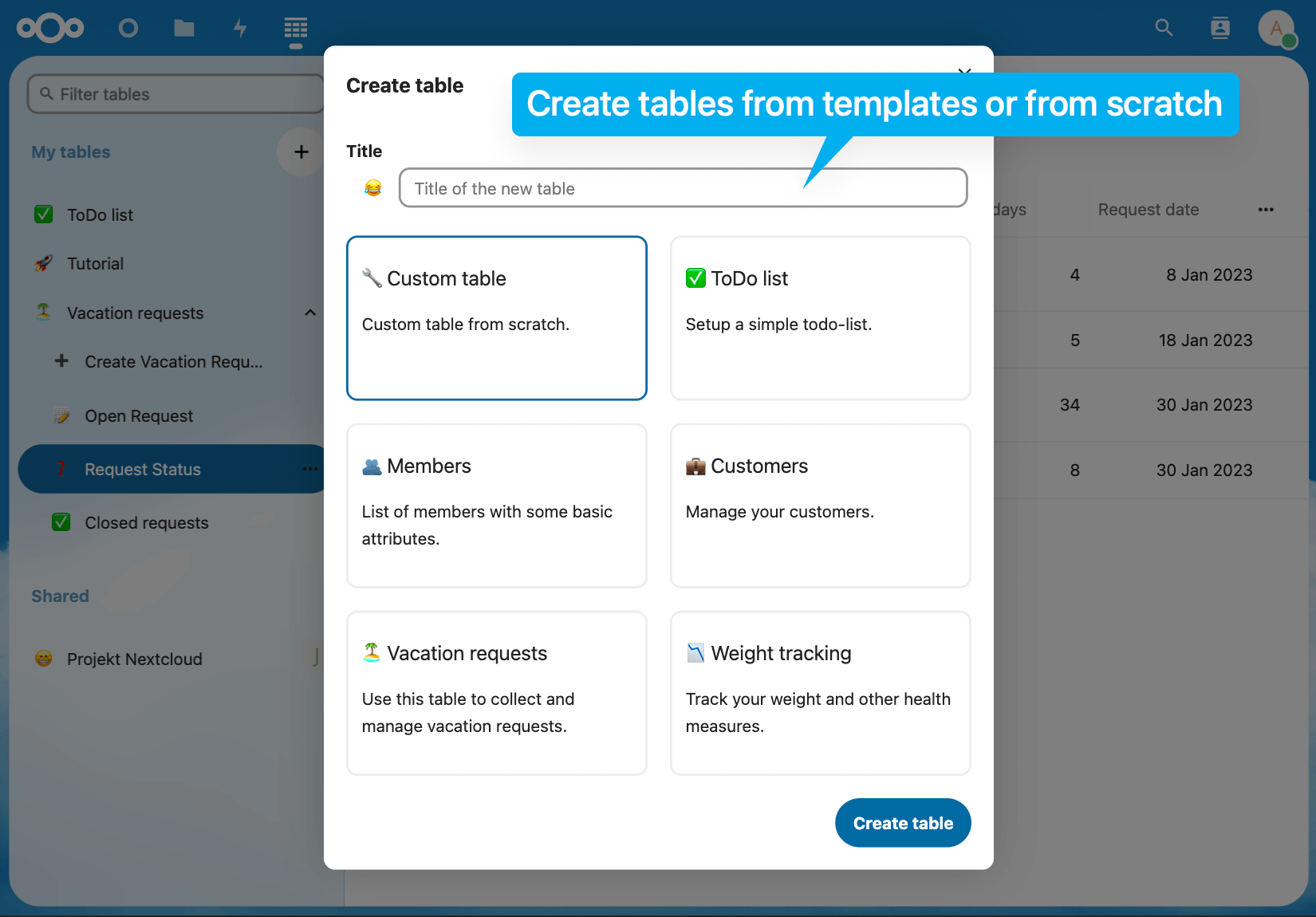
Framasoft ouvre et va rouvrir de nouveaux services
« Hein ? Quoi ? Mais vous n’aviez pas dit que vous vouliez « déframasoftiser internet » ? »
Si si, on l’a dit. Et on l’a fait.
Mais 4 à 5 ans ont passé depuis. Et il faut bien se rendre à l’évidence, la situation est moins propice au libre aujourd’hui qu’à l’époque. Pour les raisons évoquées ci-dessus, et bien d’autres encore.
L’an passé, dans notre campagne « Dorlotons Dégooglisons », nous avions notamment proposé la mise en place du service Framagroupes. Un immense merci aux personnes qui ont permis le financement de ce service 🙏
L’année précédente, c’était l’ouverture de Framaspace, espace cloud destiné aux petites associations et collectifs militants. Nous hébergeons à ce jour plus de 1 130 Framaspaces, soit autant d’instances du logiciel Nextcloud, le tout gratuitement.
Cette année encore, Framasoft souhaite proposer de nouveaux services. Toujours gratuitement (enfin, pas tout à fait, puisque ce sont vos dons qui financent), toujours respectueux de votre vie privée, toujours sur la base de logiciels libres, toujours sans aucune exploitation commerciale de vos données. Car les usages numériques évoluent, et nous devons évoluer avec eux. Ou plutôt nous devons évoluer avec vous, car ce sont avant tout le cheminement de vos pratiques qui guide nos actions.
Nous sommes bien conscient⋅es que ça peut donner cette impression.
En conséquence, cette seconde campagne « Dorlotons Dégooglisons » nous permet de faire le point sur ce que nous avons fait depuis un an, mais aussi ce sur quoi nous travaillons en ce moment, ainsi que ce que nous envisageons pour les mois à venir.
Passez à l’action ! Framasoft souhaite ouvrir de nouveaux services libres, éthiques, décentralisés et solidaires. Pour cela, nous nous sommes fixés un objectif de collecte de 60 000€ pour nous permettre de financer les machines, mais surtout le temps de travail pour leur mise en place. Si vous le pouvez : soutenez-nous !
Soutenir Framasoft
Ce que nous avons fait ces 12 derniers mois
Nous avons publié le service Framagroupes. Pour information, aujourd’hui, ce service expédie plus de 50 000 mails par jour ( !) et accueille déjà 7 900 listes de discussions, ce qui, avec les 59 000 listes de Framalistes, fait probablement de Framasoft l’organisation à but non lucratif hébergeant le plus gros serveurs de listes au… monde (si on compare par exemple à RiseUp (15,225 listes 389,871 utilisateur⋅ices) ou Renater/Universalistes (1 600 listes).
À cause d’utilisations (très) malveillantes de Framatalk, nous avons développé un logiciel (libre, bien entendu) qui permet d’imposer l’authentification des personnes qui souhaitent ouvrir un salon de visioconférence. Si on peut entendre que cela représente une contrainte pour vous, au vu des usages (on le répète, très) malveillants qui étaient faits de ce service, nous n’avions tout simplement pas le choix.
Nous avons migré plus de 1 000 instances Framaspace en version 28. Nous avons fait développer un logiciel de supervision spécifique, Argos Panoptès, pour gérer autant d’instances.
Notre infrastructure email, malgré plus de 8 millions de mails envoyés par mois (oui oui, 271 000 mails en moyenne par jour !) continue d’être régulièrement boudée par certains acteurs (oui, c’est vous qu’on regarde Orange, La Poste et SFR !). À tel point qu’après une lutte de plusieurs mois qui nous aura demandé autant d’énergie que de paracétamol, nous avons dû nous résoudre, à contrecœur, à utiliser les services d’un prestataire externe, pour les envois de nos newsletters (431 129 abonné⋅es en double opt-in).
Du côté de Framaforms, nous avons amélioré la gestion du spam, cette chienlit qui n’en finit pas de revenir dégrader un service pourtant parmi les plus utilisés de Framasoft.
C’est vrai, ça, hein : et personne ne le prendrait au sérieux !
Pour faciliter les recherches de vidéos sur l’ensemble du réseau PeerTube (notre alternative à YouTube), nous avons changé le logiciel qui motorise Sepiasearch, notre moteur de recherche du « vidiverse ». Ce dernier utilise maintenant la brique logicielle Meilisearch, et non plus Elasticsearch, dont la licence a pris un chemin bien moins libre.
Framacarte a aussi fait l’objet d’une mise à jour majeure, qui fait suite au travail de la communauté uMap, avec laquelle nous restons très en lien.
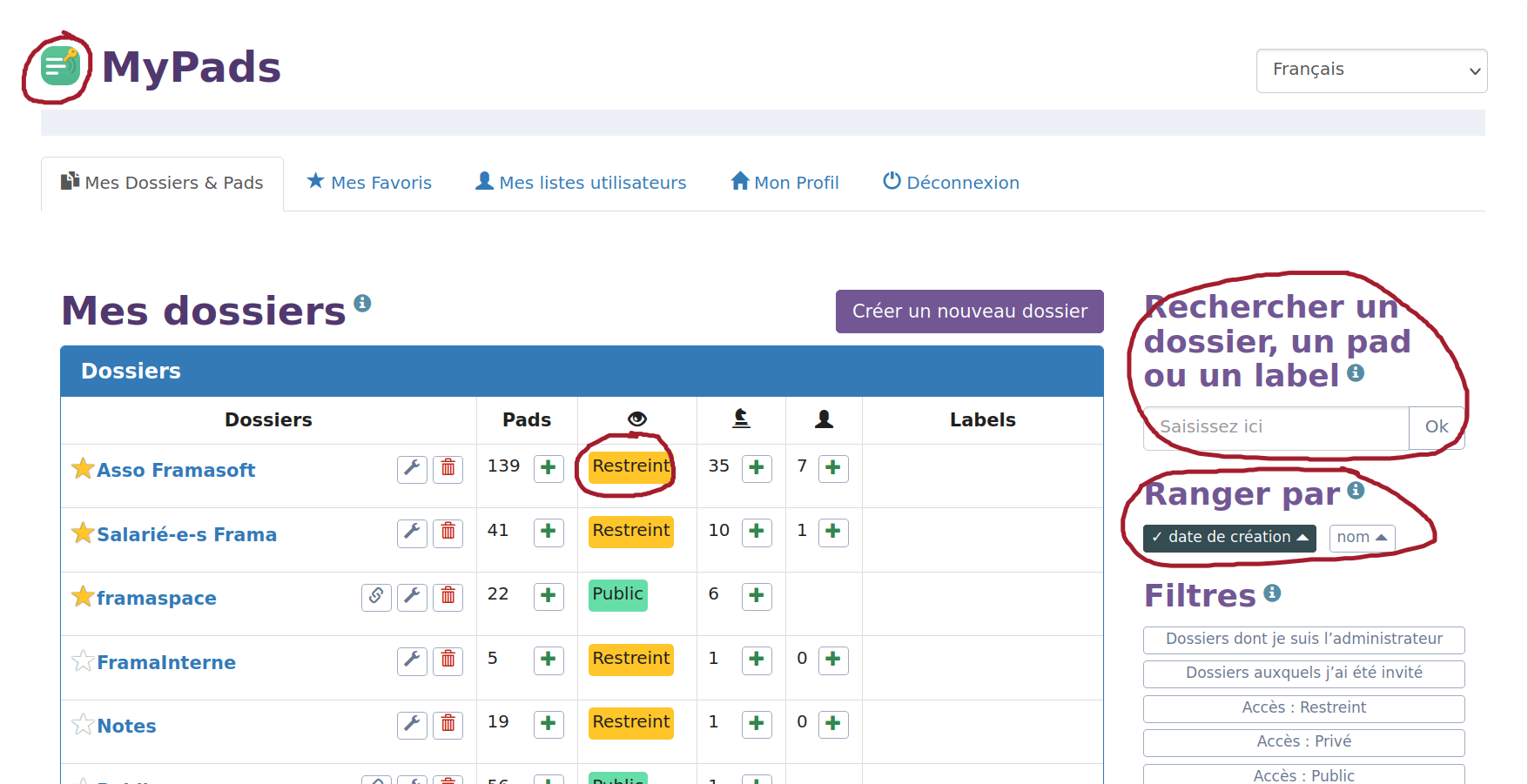
Concernant MyPads, le plugin qui permet de gérer et d’organiser vos Framapad, les changements ont été subtils, mais nombreux. Ainsi, grâce au travail de Pierre, stagiaire à Framasoft pour (seulement) 6 semaines, de nombreuses petites améliorations ont été faites.
Parmi les améliorations d’ores et déjà disponibles :
- ajout d’un logo pour revenir à l’accueil (oui, c’est bête, mais il n’y en avait pas et beaucoup d’utilisateur⋅ices peinaient à retourner sur la page d’accueil)
- meilleure identification des dossiers restreints ou publics
- les dossiers archivés sont maintenant repliés par défaut pour une meilleure lisibilité
- les propriétés du dossiers sont maintenant repliées par défaut pour une meilleure lisibilité
- la recherche, en page d’accueil, permet maintenant de rechercher sur les noms de pads (en plus des dossiers)
- possibilité de trier les dossiers ou les pads par noms ou par dates de création
- améliorations CSS diverses
Enfin, Mobilizon, notre logiciel libre et fédéré alternatif aux groupes et pages Facebook, a été transmis à la communauté (aujourd’hui coordonnée par la communauté Kaihuri/Keskonfai). Nous annoncions en effet il y a quelques mois que nous estimions notre engagement initial concernant Mobilizon rempli. Nous souhaitions pouvoir rediriger une partie de notre capacité de développement logiciel vers les projets les plus prioritaires (contrairement à ce que beaucoup de personnes pensent, en dehors de PeerTube, nous ne disposons « que » d’un mi-temps de développeur salarié).
Passez à l’action ! Framasoft accueille plus de 2 millions de personnes par mois, et améliore et maintient de très nombreux services tout au long de l’année. Cela implique énormément de travail humain (développement, support, administration système, etc), ainsi qu’une infrastructure technique conséquente. Si vous le pouvez : soutenez-nous !
Soutenir Framasoft
Ce sur quoi nous travaillons en ce moment
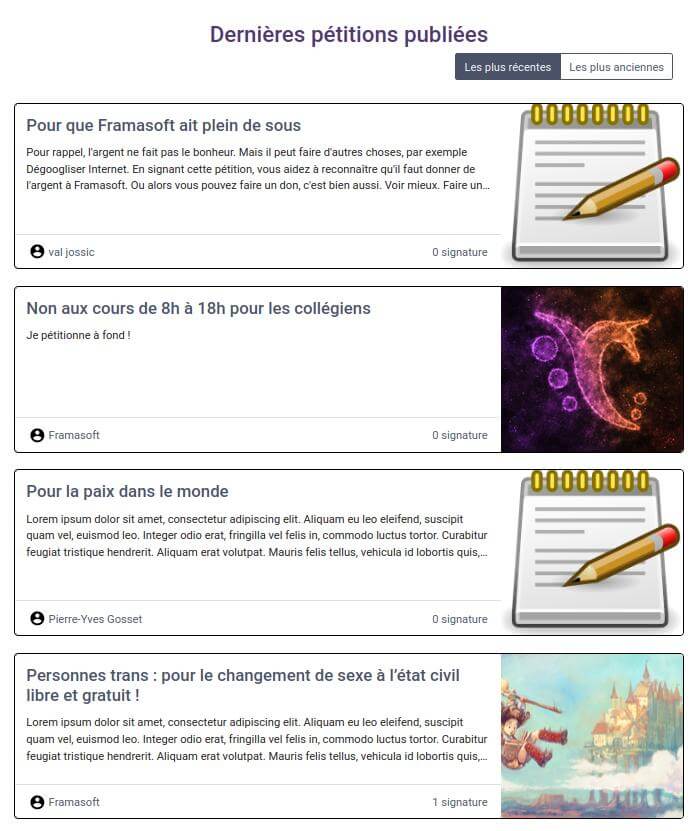
Framapétitions, un service de… pétitions
Il existe de nombreuses plateformes de pétitions, mais ces dernières ne sont que rarement basées sur du code libre. Par ailleurs, ces plateformes sont aussi largement soupçonnées d’utiliser vos données personnelles (nom, email, cause soutenue) à d’autres fins que d’ajouter votre signature à une pétition.
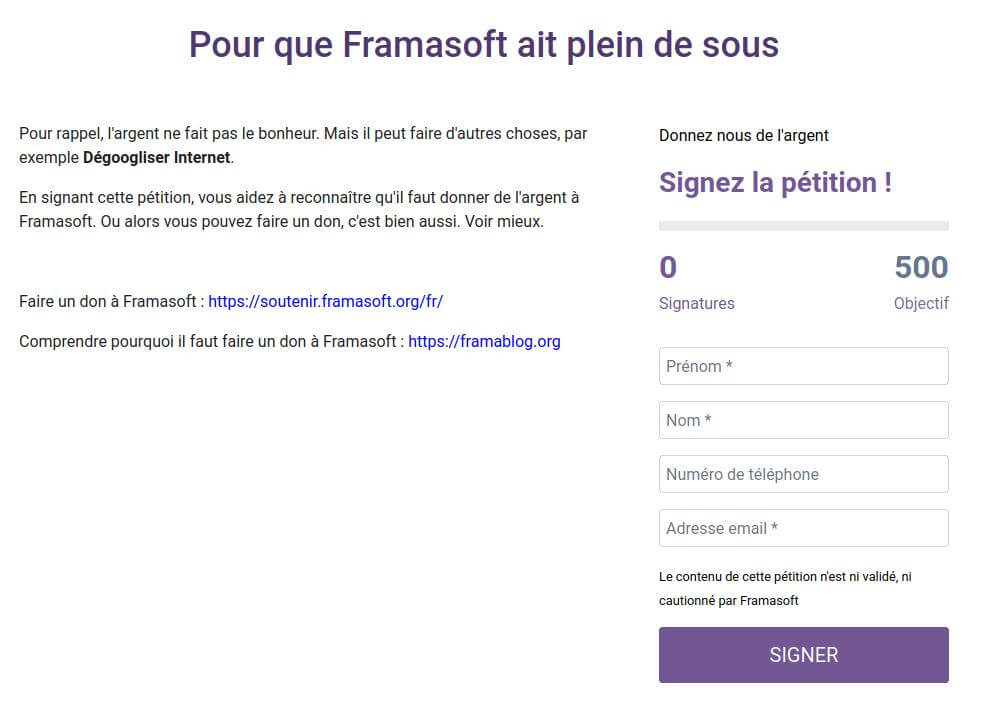
Framapétitions est donc un service en test (on répète : il n’est PAS finalisé) qui permet de créer ou signer des pétitions citoyennes. Le service peut d’ores et déjà être utilisé, mais reconnaissons-le, il mérite encore d’être amélioré. Ça tombe bien, nous allons travailler dessus dans les mois qui viennent.
Dans les coulisses
Un projet de plateforme de pétitions qui n’exploiterait pas vos données était donc dans nos cartons depuis plus de 10 ans. Mais… faute de temps et d’énergies, nous repoussions sans cesse le sujet. Une autre raison était plus politique : à quoi servent vraiment les pétitions ? Parfois uniquement à se donner bonne conscience en se disant « J’ai agi », nous dédouanant alors d’un passage à l’action plus directe. Cependant, vos demandes régulières à ce que nous avancions sur le sujet nous ont motivés à remettre ce projet au goût du jour.
Voilà plusieurs années que nous soutenons un projet libre nommé « Pytition« . Fonctionnel, mais nécessitant encore pas mal de travail sur les aspects visuels. Nous soutenir financièrement, c’est nous permettre d’allouer du temps de travail pour améliorer Pytition, en lien avec le développeur originel et permettre, à moyen terme, d’ouvrir une plateforme de pétitions réellement libre, ouverte, et avec une garantie de non-exploitation commerciale de vos données.
Tester Framapétitions (sans garantie ni support !)
Framalab, pour expérimenter des logiciels avant qu’ils ne deviennent (potentiellement) des services
Mettre en place un logiciel utilisable en ligne est assez simple, surtout quand, comme nous, vous disposez d’un administrateur système très compétent. Cependant, entre installer un service en ligne et être capable d’y accueillir plusieurs centaines de milliers de personnes par mois, il y a tout un monde. Il faut tester les fonctionnalités du logiciel, évaluer sa maintenance, savoir jauger le temps et l’énergie qu’il nous prendra en support et en modération, créer une page d’accueil, parfois corriger quelques bugs gênants, constituer une Foire Aux Questions, communiquer dessus, etc.
Afin de faciliter ce processus, nous avons décidé de rendre public le site Framalab. Sur ce site vous trouverez quelques unes de nos applications en test.
Notez bien que les applications qui suivent sont en test. Elles peuvent disparaître à tout moment, ce qui signifie que vous pouvez perdre vos données du jour au lendemain. Par ailleurs, elles ne feront l’objet d’aucun support de notre équipe salariée : si vous avez des questions ou rencontrez des difficultés, vous pouvez les remonter sur notre forum, où l’entraide sera communautaire (comprendre : peut-être que quelqu’un vous répondra, peut-être pas).
Visiter Framalab (sans garantie ni support !)
Des alternatives à Tricount
Tricount est une application (non libre) de gestion des dépenses de groupes (familles, ami⋅es, colocataires, etc).
Elle compte plus de 5 millions d’utilisateur⋅ices dans le monde.
L’application fonctionnait auparavant très bien sur le web, qui s’affichait dans une version mobile tout à fait correcte. Mais depuis peu la version web n’est plus disponible, et vous êtes obligé⋅es de télécharger et installer une application web sur votre smartphone. Nos ami⋅es d’ Exodus Privacy détectent, sur cette application, pas moins de 12 pisteurs et 16 permissions. D’où l’idée de vous proposer des alternatives libres, garanties sans pisteurs.
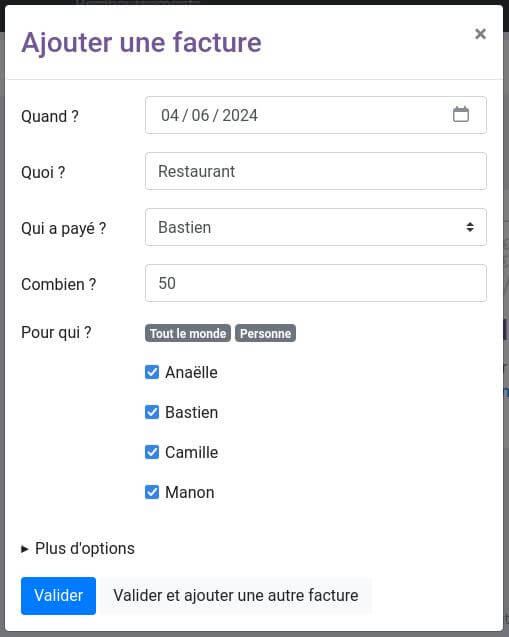
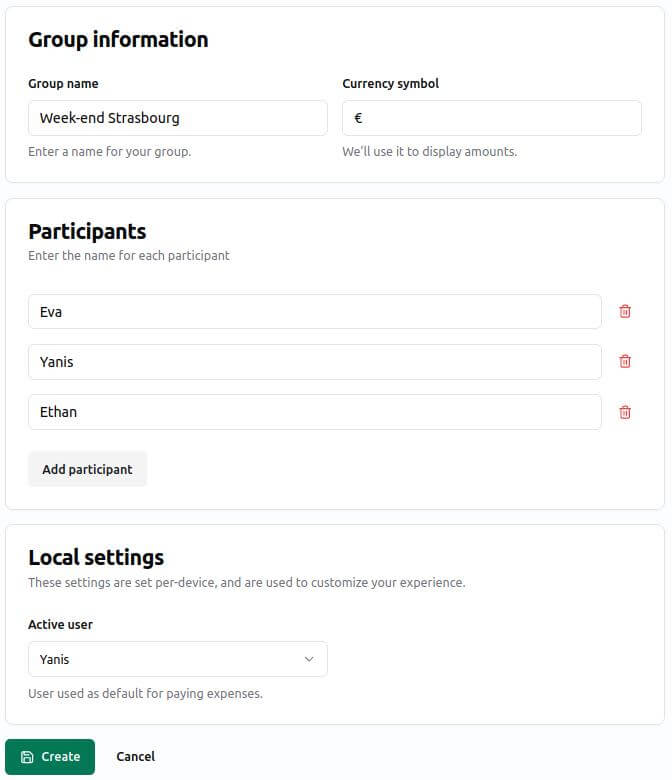
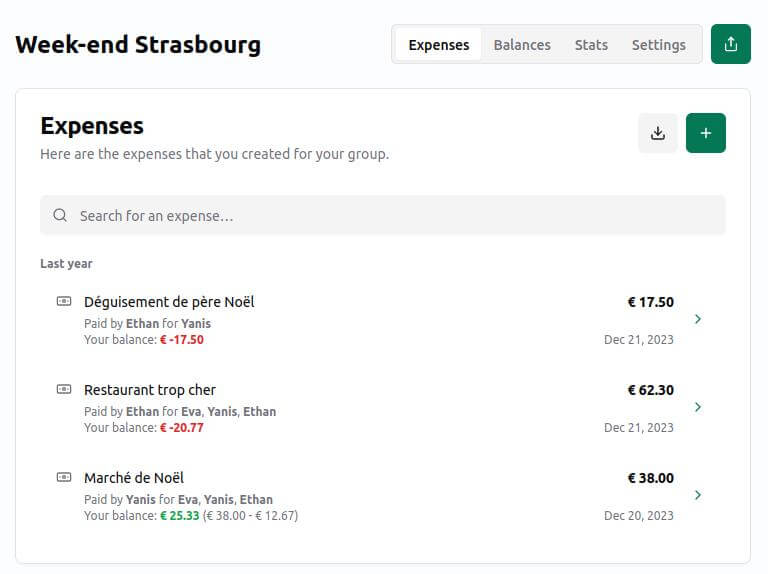
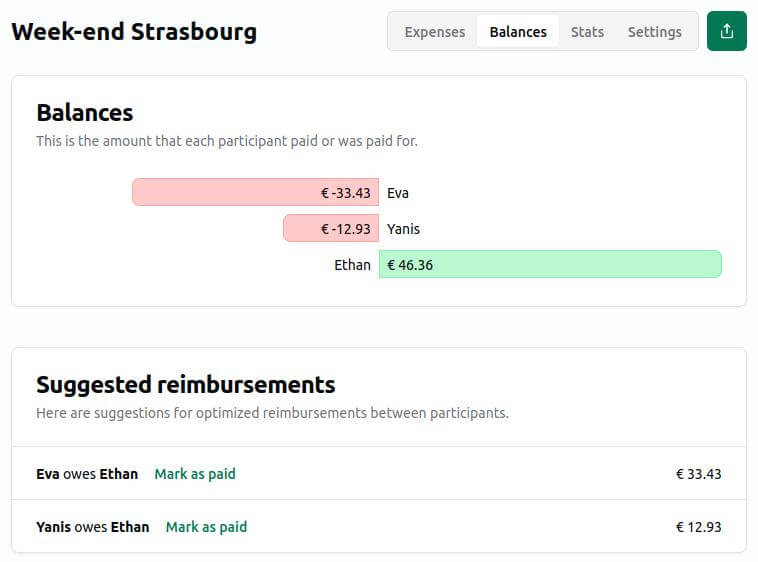
I Hate Money
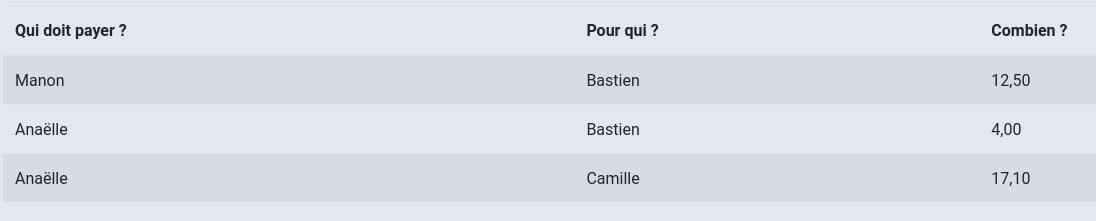
Un « petit » projet libre comme on les aime : il fait une chose, mais la fait bien, et sans fioriture. Par exemple pour un voyage entre ami⋅es, une première personne créée un projet (pas besoin de créer un compte : il suffit de choisir un nom, de définir un code d’accès, et de laisser un email). Les autres personnes pourront alors s’y connecter, et ajouter chacune leurs dépenses. Au final, un clic sur « remboursement » permettra de savoir très facilement « Qui doit combien à qui ? ». Simple, rapide, efficace, on vous dit !
Dans les coulisses
Cette application, née en 2011, n’a peut-être pas le « look and feel » le plus moderne. Cependant, nous l’avons testé en conditions réelles, et… elle fonctionne très très bien et nous l’avons trouvée simple et efficace sur mobile. Elle a principalement été développée par Alexis Métaireau (oui, le même qui a développé pour nous Argos Panoptes, que nous évoquions plus haut dans la partie « Framaspace »).
Tester I Hate Money (sans garantie ni support !)
Spliit
Encore une fois, un petit projet très simple, mais avec un look résolument moderne : pas besoin de s’authentifier, quelqu’un créé un groupe, puis ensuite ajoute des participant·es, et enfin leur partage l’URL. Tout le monde peut rentrer des dépenses simplement, et l’application calcule ensuite automatiquement qui doit quoi à qui. Il est possible d’utiliser des modes de partage plus avancés : par nombre de portions ou encore par pourcentage. Seul hic, le projet est à l’heure actuelle uniquement anglophone, donc il vous faudra comprendre a minima la langue de Shakespeare pour pouvoir l’utiliser. Sans pour autant le garantir, si cela devait devenir un service Framasoft, peut-être que notre communauté pourrait aider à le rendre traductible puis à le traduire pour un public francophone !
Dans les coulisses
Et pourquoi pas Cospend ?
Vous connaissez peut-être Cospend, l’application Nextcloud qui propose des fonctionnalités similaires. Nous avons choisi de ne pas expérimenter avec cette dernière, pour plusieurs raisons. La première, c’est qu’elle nécessite une instance de Nextcloud (bravo Sherlock !), et que cela signifierait de mettre en place une instance de Nextcloud uniquement dédiée à ce service. La deuxième, c’est qu’il faudrait également rajouter des modifications au logiciel, pour que les utilisateur·ices de l’instance ne puissent pas ajouter n’importe qui d’autre utilisant le service à un groupe de dépense. La troisième, c’est que la version Web mobile nous a semblé peu utilisable (avec des écrans qui se recouvrent les uns les autres), et bien qu’une application mobile Android MoneyBuster propose en théorie de se lier à un Cospend, en pratique il n’est plus possible de rejoindre un groupe de dépense Cospend avec cette dernière, et ce depuis quelques mois, sans visiblement de résolution apparente de ce bug critique). Alors on sait ce que c’est qu’être bénévole sur un logiciel libre, donc on ne jettera la pierre à personne, et au contraire on encouragera le développement, depuis les gradins. Mais en l’état actuel, cela nous semble plutôt une alternative dont l’évolution est à surveiller, ou viable à utiliser sur des instances Nextcloud (coucou les Framaspaces !), plutôt qu’un service que nous voudrions proposer à grande échelle. Affaire à suivre…
Tester Spliit (sans garantie ni support !)
Tableaux blancs et diagrammes en ligne
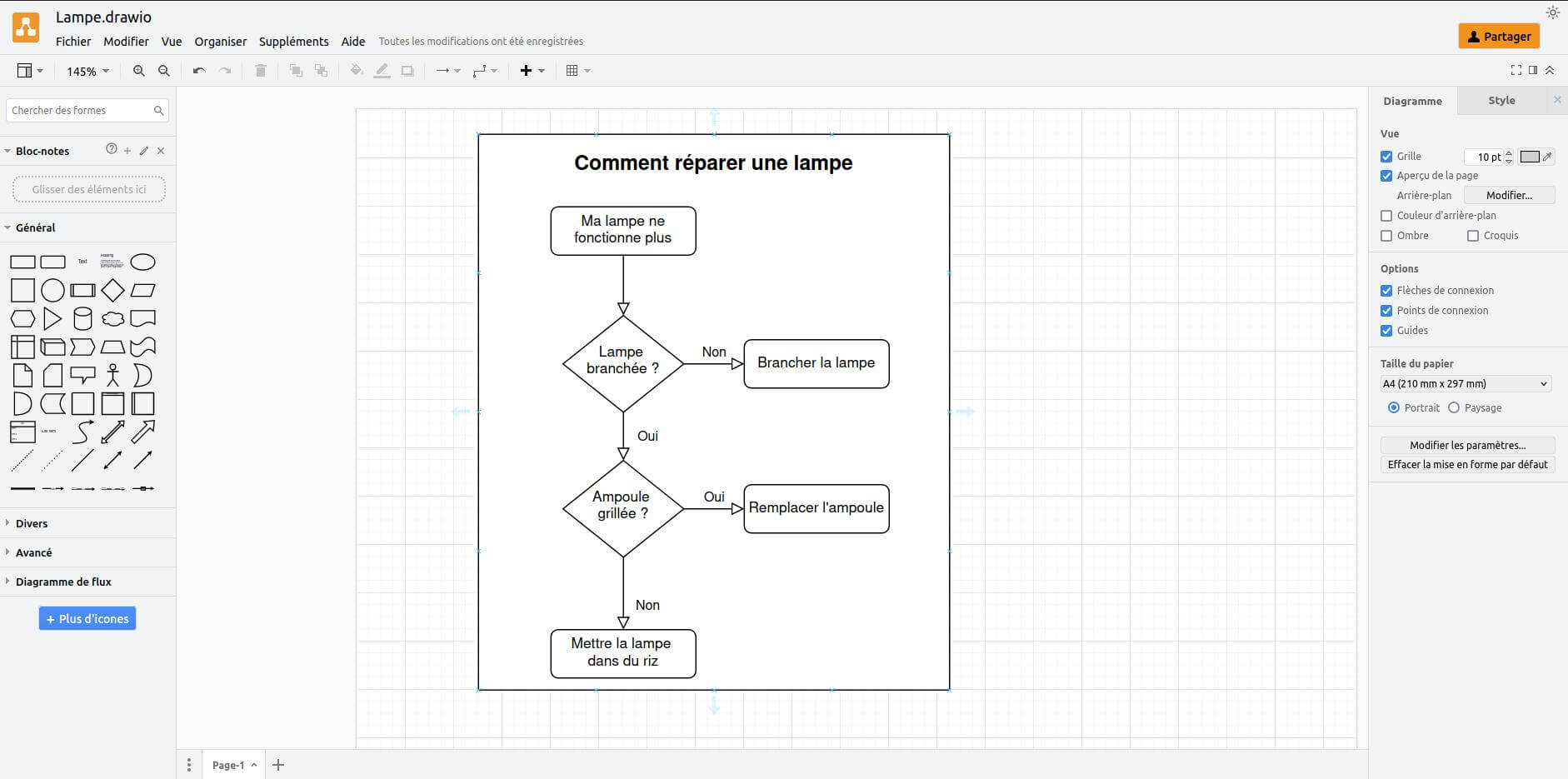
Draw.io
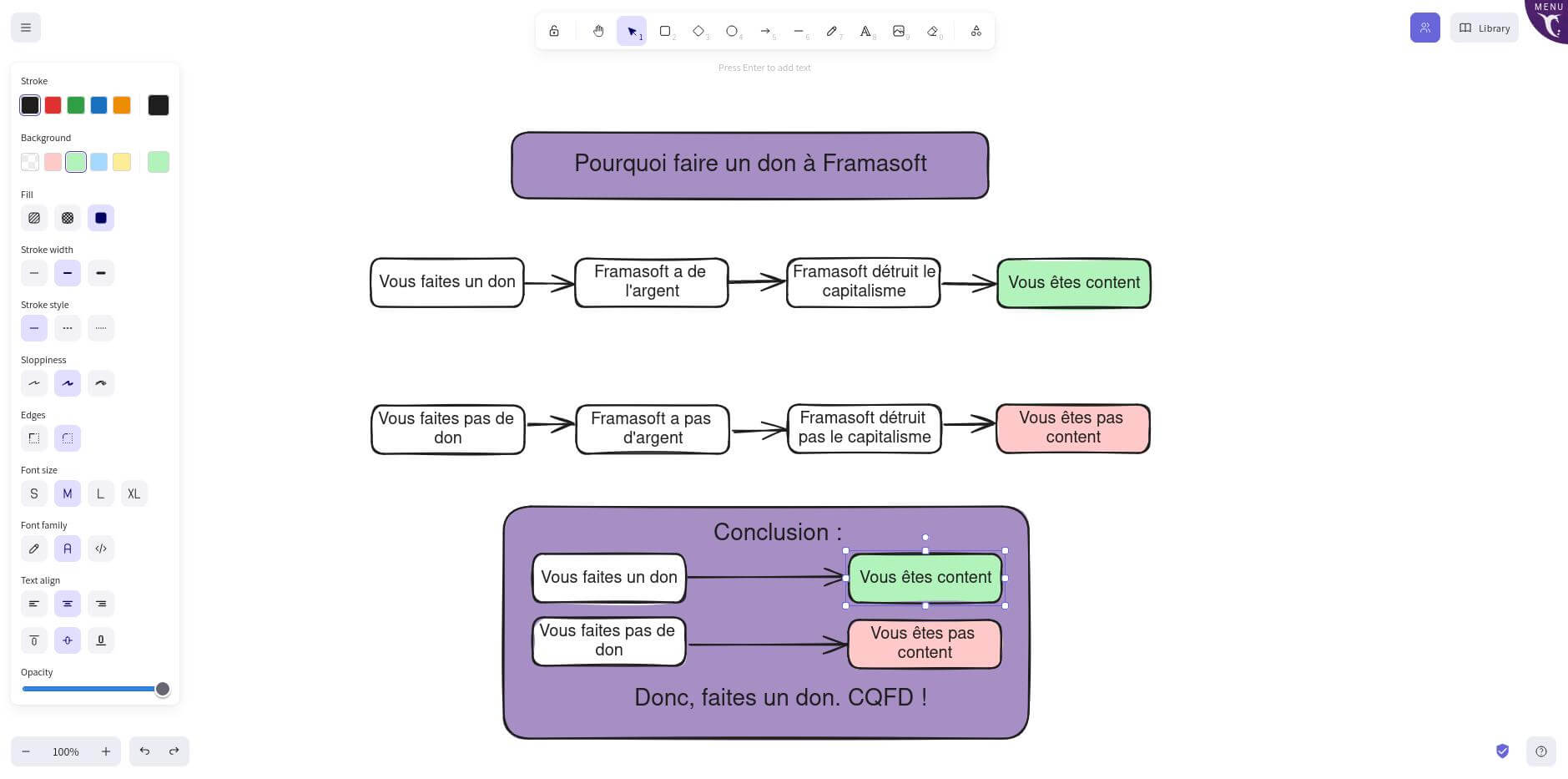
Draw.io permet de créer des diagrammes professionnels. Ce service est plutôt adapté si vous souhaitez réaliser un organigramme ou un diagramme UML.
Interface de Draw.io
Dans les coulisses
La version de Draw.io que nous proposons actuellement est une version offline dans le sens où elle ne permet que l’enregistrement local, et ne permet pas la modification collaborative.
Il faut donc considérer notre version de draw.io comme un logiciel « à l’ancienne » où vous allez créer votre diagramme (dans votre navigateur), puis l’enregistrer. Il est cependant possible de partager votre diagramme publiquement (en lecture seule) en utilisant la commande « Fichier → Publier → Lien ».
Nous avons tout de même ajouté la possibilité d’enregistrer vos données sur Framagit (il faudra vous y créer un compte).
Les fonctions collaboratives en temps réel imposent, elles, de passer par les serveurs de la société Jgraph qui édite le logiciel, elles ne sont donc pour le moment pas supportées.
Nous choisissons cependant de tester draw.io car nous le trouvons très intéressant de par ses fonctionnalités avancées. Peut-être le proposerons nous, à terme, comme plugin au sein de Framaspace.
Tester Draw.io (sans garantie ni support !)
Excalidraw
Là où Draw.io permet d’organiser des diagrammes, voyez plutôt Excalidraw comme un outil de « tableau blanc » (qui permet, aussi, de réaliser des diagrammes simples).
Cette simplicité rend Excalidraw, selon nous, plus accessible au grand public.
Dans les coulisses
Contrairement à Draw.io, notre version d’Excalidraw permet de travailler de façon collaborative. Nous expérimentons cette fonctionnalité, mais nous pourrions la retirer si nous ne la trouvons pas suffisamment stable et sécurisée. Cependant, Excalidraw utilisant à ce jour la plateforme Firebase de Google pour enregistrer les images en ligne, nous avons pour l’instant désactivé la possibilité d’ajouter des images dans notre version d’Excalidraw.
Notez que nous avons aussi évalué le logiciel tldraw, qui nous a paru une initiative intéressante, mais sa licence n’est pas libre car interdisant les usages commerciaux (ce qui n’aurait pas été le cas de Framasoft, mais ne répond pas pour autant aux exigences d’une licence libre).
Excalidraw, un tableau blanc pour mettre en forme vos idées collaborativement
Tester Excalidraw (sans garantie ni support !)
Des outils pour manipuler vos PDF en ligne
Ahhhh, les PDF ! Un format ouvert certes, pratique pour l’impression, mais clairement pas adapté à la modification. Si vous devez réorganiser des pages, en supprimer, en ajouter, les faire pivoter, ou les signer, c’est assez rapidement la croix et la bannière. Par ailleurs, il faut parfois pouvoir réduire leur poids avant de l’envoyer par email. Ça tombe bien, les deux outils que nous proposons sont là pour ça !
Signature PDF
Créé par la société coopérative « La 24eme », ce logiciel permet, au travers de quelques entrées simples, de manipuler vos PDF :
- « Signer » : permet de signer, parapher, tamponner un pdf, mais aussi de partager le PDF signé, pour qu’il puisse être signé par d’autres personnes ;
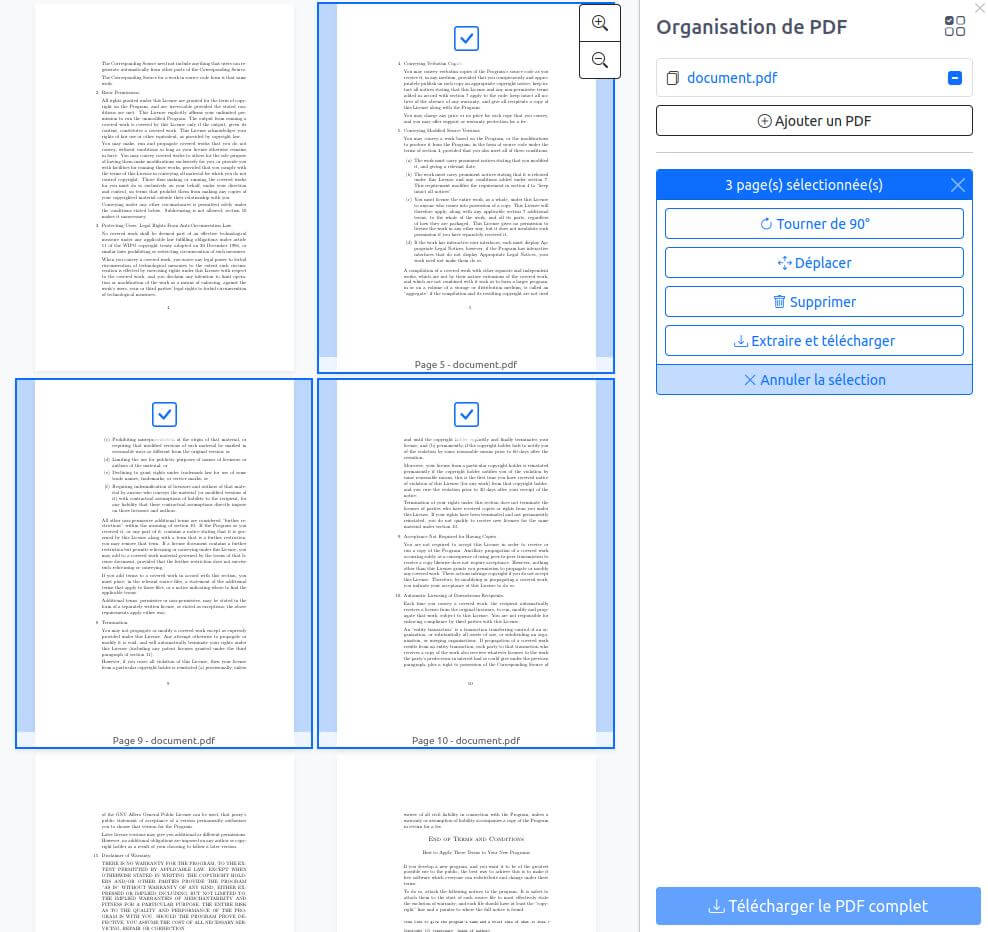
- « Organiser » : permet de tourner les pages d’un PDF (rotation), de déplacer des pages, d’en supprimer, d’en ajouter (depuis un autre PDF, par exemple pour faire un seul PDF à partir de plusieurs fichiers), etc.
- « Métadonnées » : permet d’afficher les métadonnées d’un fichier PDF (par exemple la date de création ou le logiciel utilisé pour sa création), mais aussi d’éditer ces métadonnées ou d’en supprimer ;
- « Compresser » : pour réduire la taille d’un PDF. Si le PDF original a déjà été compressé, cela n’aura aucun effet évidemment. Mais nos tests ont démontré qu’un PDF constitué de pages scannées de 38Mo au départ n’en faisait plus que 6 au final, ce qui est un gain conséquent.
Tester Signature PDF (sans garantie ni support !)
Stirling PDF
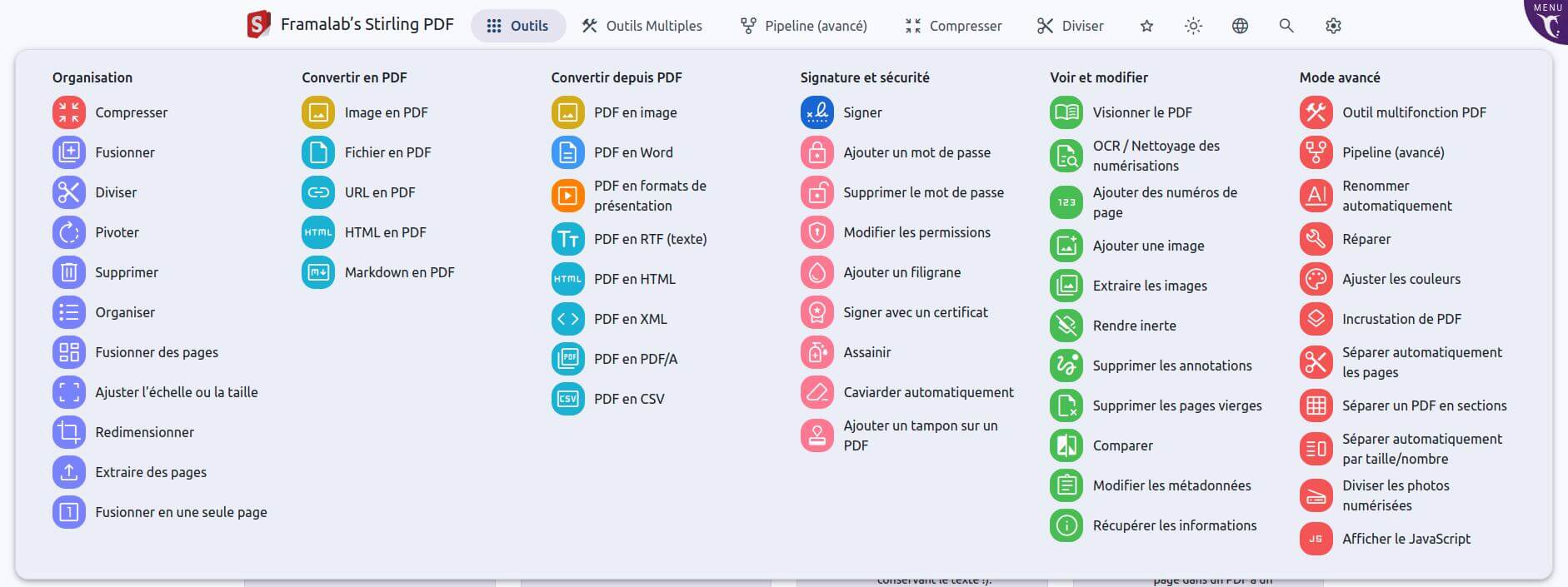
Là, on sort la grosse artillerie. Stirling PDF propose pas moins de 71 outils différents !
Depuis des outils « simples » (fusion, rotation, etc) à ceux bien plus complexes (extraire les tableaux d’un PDF pour un faire un fichier .csv exploitable par un tableur, ajuster les couleurs, transformer une URL de page web en PDF, etc), en passant par des fonctions bien utiles (protéger par mot de passe, numéroter automatiquement les pages, etc.). Il existe même un outil « pipeline » qui permet d’enchaîner différentes actions (par exemple : rotation 90°, puis suppression des pages 1 et 14, puis ajout de numéros de pages, puis compression).
Écran d’accueil Stirling PDF
Tester Stirling PDF (sans garantie ni support !)
Liberaforms, un successeur pour Framaforms ?
Framaforms est basé sur le logiciel Yakforms, logiciel qui arrive en fin de vie. Pour différentes raisons (cf. « coulisses »), nous avons dû faire le choix de lui trouver un successeur, qui permettra de continuer à fournir un service proche de celui que vous utilisez actuellement.
Après moult essais-recherches (et quelques déceptions), notre choix s’est arrêté sur Liberaforms, un logiciel libre de formulaires créé et développé par une petite équipe espagnole.
Le « périmètre fonctionnel », c’est à dire l’ensemble de ce que vous pouvez faire avec ce logiciel, est sensiblement le même que celui que propose Yakforms, en dehors de certaines fonctions avancées (gestion de conditions, ou emails de validation, par exemple). Nous vous proposons de le tester sur notre plateforme https://beta.framaforms.org pendant plusieurs mois. Au terme de cette phase de tests, pendant laquelle nous pensons (si vous nous en donnez les moyens) améliorer quelque peu l’interface, nous pourrons alors commencer une bascule entre Yakforms et Liberaforms qui, rassurez-vous, s’étalera elle aussi sur plusieurs mois (vous ne perdrez donc pas vos formulaires en cours).
Dans les coulisses
L’histoire de Framaforms/Yakforms s’étale sur près de 10 ans et est racontée sur le Framablog. Yakforms est donc basé sur Drupal 7, publié en 2011, qui aura donc eu une durée de vie de 14 ans, ce qui en fait une longévité relativement exceptionnelle pour une application web. La « fin de vie » de Drupal 7, plusieurs fois repoussée, s’achève finalement le 5 janvier 2025. À compter de cette date, il n’y aura donc plus de mise à jour de sécurité : si une faille était découverte, elle ne serait plus couverte (annoncée, réparée, suivie, etc) par la communauté, et donc Yakforms serait touché par ricochet.
Notre première idée a donc été, évidemment, de migrer Yakforms vers Drupal 8, 9, ou même maintenant Drupal 10. Cependant, c’était plus facile à dire qu’à faire, car Yakforms est composé de nombreux modules compatibles avec Drupal 7 mais pas avec les versions suivantes. C’est notamment le cas du module « form_builder » qui n’a jamais été porté dans les versions suivantes.
Il y a eu différentes tentatives de migration de Yakforms, la dernière en date par le Centre d’Expressions Musicales, au Havre, qui utilise massivement Framaforms (et bien d’autres logiciels libres, d’ailleurs). Mais le sujet étant complexe, le projet n’a pas abouti.
Début 2024, nous nous sommes donc lancés à la recherche de logiciels libres de formulaires alternatifs. Bonne nouvelle : le paysage avait bien évolué depuis la sortie de Framaforms en 2016, et de nombreuses alternatives existent aujourd’hui. Voici quelques unes des solutions testées :
- https://www.limesurvey.org/fr : la référence en matière de logiciel libre d’enquête. Cependant, « enquête » ≠ « formulaire » ! LimeSurvey est un logiciel idéal si vous voulez réaliser une enquête de plusieurs dizaines ou centaines de questions, avec des embranchements, etc. Mais notre objectif avec Framaforms est de proposer une alternative à Google Forms, à savoir un logiciel simple à prendre en main, qui permet de publier son premier formulaire en 5mn chrono. Ce qui est très, très loin d’être le cas de LimeSurvey ;
- https://apps.nextcloud.com/apps/forms : une app pour Nextcloud (logiciel que l’on connaît bien à Framasoft) pour créer des formulaires. Ce choix est arrivé en second dans notre évaluation. D’autant que nos ami⋅es du chaton La Contre-Voie ont apporté un développement spécifique permettant un accès simplifié. Mais nous avons estimé que le code de Nextcloud Forms n’était pas encore suffisamment stable pour nos besoins, ni capable d’accueillir des dizaines de milliers de visiteurs quotidien ;
- https://cryptpad.fr/form/ : issu de l’excellente suite bureautique chiffrée Cryptpad. L’interface n’est pas très jolie, mais plutôt fonctionnelle. Cependant, le côté 100 % chiffré du logiciel était, paradoxalement, rédhibitoire pour nous : nous gérons plusieurs centaines de milliers de formulaires par an, et un chiffrement de bout en bout aurait largement limité notre capacité de support, et donc multiplié les personnes qui se seraient plaintes auprès de nous ;
- https://surveyjs.io/ dispose d’un excellent concepteur de formulaire, mais la partie enregistrement et analyse n’est pas libre, ce qui ne présage habituellement rien de bon quant à l’ouverture du logiciel dans les années à venir ;
- https://formbricks.com/ : ce logiciel nous a semblé tout à fait correct. Par contre, il est pensé pour faire de « l’enquête pas à pas » et non des formulaires. Par ailleurs, il nous aurait fallu adapter de nombreuses fonctionnalités (souvent marquées comme « pro » ;
- https://getinput.co : comme SurveyJS, il s’agit plus d’une alternative à Typeform qu’à GoogleForms, avec « une question = un écran ». Le travail de traduction aurait été conséquent, mais nous l’avons éliminé aussi parce que bien que le code soit libre, l’entreprise qui édite ce logiciel semble avoir une politique commerciale relativement agressive et n’aurait probablement pas bien accepté de voir Framasoft proposer son logiciel gratuitement, devenant un concurrent de poids qui aurait « récupéré » leur travail ;
- https://ec.europa.eu/eusurvey/ : Développé par l’Union Européenne depuis 2016. Le rythme de développement est relativement lent. Ça aurait pu être un candidat intéressant, mais le code nous a semblé une véritable usine à gaz, puisque conçu pour gérer des formulaires au sein d’institutions publiques de grandes tailles, avec l’obligation de gérer plusieurs langues, etc ;
- https://ohmyform.com/ : là encore, plutôt une alternative à Typeform qu’à Google Forms. Notez qu’en l’absence de plateforme pour tester ce logiciel, il vous faudra donc l’installer. Par ailleurs, le développement, bien que toujours en cours, semble relativement ralenti ;
- https://tripetto.app/ a clairement le concepteur de formulaire le plus avancé. Malheureusement le logiciel est uniquement en anglais (et non facilement traduisible). Mais surtout, si le « builder » (l’interface de création de formulaire) est libre, d’autres parties essentielles du logiciel ne le sont pas, ce qui était évidemment rédhibitoire pour nous ;
- Nous avons aussi évalué plusieurs outils « no-code » (comme NocoDB ou Baserow) qui sont aussi très pertinents pour créer des formulaires. Cependant, nous avons estimé que nous n’étions pas sur des outils simples à prendre en main alors que c’était un critère essentiel pour nous. Nous n’excluons pas de proposer ces outils à termes, mais cela nous paraissait prématuré pour le moment.
- https://gitlab.com/liberaforms/liberaforms – ce n’est ni la plus belle, ni la plus moderne des alternatives testées. Cependant, elle fait correctement le travail, et semble bien pouvoir passer à l’échelle en gérant plusieurs dizaines ou centaines de milliers de formulaires. Par conséquent, nous avons contacté les développeurs de Liberaforms, qui semblaient enchantés que Framasoft propose leur logiciel à l’évaluation (merci à eux !).
Le logiciel n’était pas traduit en français, alors… nous l’avons fait ! Un grand merci à Framalang, spf et Booteille pour leur aide !
Dans les mois qui viennent, grâce à vos dons, nous nous appliquerons donc à finaliser la traduction, à améliorer l’interface (notre code sera bien évidemment reversé auprès de la communauté Liberaforms), et évaluerons vos retours pour déterminer si, oui ou non, Liberaforms remplacera à terme Yakforms comme moteur de Framaforms.
Tester Liberaforms (sans garantie ni support !)
Framaspace, de l’accompagnement pour une plus grande autonomisation
Framaspace accueille plus de 1 100 associations et collectifs. Nous envisageons de doubler ce chiffre, au moins, d’ici la fin de l’année. Ce qui positionne Framasoft comme un des plus gros hébergeurs Nextcloud (le logiciel qui motorise Framaspace) de France, hors opérateurs type OVH.
Mais il nous reste un problème majeur auquel il faut répondre : comment accompagner les personnes qui découvrent Nextcloud ? En effet, comme nos enquêtes le démontraient, et comme nous l’indiquions dans notre conférence de lancement, Nextcloud reste relativement peu connu, et pas aussi simple à prendre en main qu’un Google Drive, par exemple. Il nous faut donc trouver des façons qui permettent à une personne qui n’a jamais utilisé le logiciel de s’y retrouver : qu’elle puisse importer ses fichiers ou calendriers, qu’elle sache comment partager publiquement un fichier, qu’elle comprenne comment utiliser le tableur ou le traitement de texte intégré, etc.
Nos actions en cours sont nombreuses sur le sujets : nous soutenons par exemple l’initiative d’ateliers Nextcloud (en juin 2024) organisé par L‘Établi Numérique et La Dérivation. Nous avons aussi un stagiaire, Val, qui travaille sur deux sujets : faciliter la migration depuis un espace cloud externe (Google Drive, Dropbox, ou même un autre Nextcloud) vers Framaspace ; proposer un tutoriel aux nouvelles et nouveaux arrivants sur Framaspace, en utilisant la bibliothèque IntroJS.
Vidéo de démonstration de l’application IntroJs, développée par Val, pour faciliter la prise en main de Framaspace.
Là encore, vos dons nous permettent de faire, et surtout de faire sans trop attendre.
Proposer la candidature de votre asso/collectif
Passez à l’action ! Pour pouvoir répondre à vos besoins et vos envies en termes de services libres émancipateurs, nous nous sommes fixés un objectif de collecte de 60 000€ qui nous permettront de mettre l’énergie nécessaire à la mise en place de ces services. Si vous le pouvez : soutenez-nous !
Soutenir Framasoft
Et ensuite ?
Mais Framasoft ne s’arrête pas là !
D’autres projets sont en cours, mais sont, eux, plus incertains.
Leur mise en place dépendra évidemment du succès de cette collecte (oui, on manque peut-être un peu de subtilité 😉), mais aussi des résultats des études de faisabilité technique qui sont en cours.
Nous pouvons cependant les évoquer ici, en insistant sur le fait qu’en parler maintenant n’est pas pour autant un engagement de mise en place de notre part.
Aktivisda : décliner des visuels rapidement
Un des besoins récurrents repérés parmi les associations que Framasoft côtoie est celui de pouvoir rapidement créer ou décliner des visuels. Par exemple, pour une chorale qui ferait 5 représentations en fin d’année, il s’agit surtout, sur la base d’un affiche commune, de changer les dates, les heures, et les lieux. C’est un besoin simple, qui doit prendre quelques minutes maximum, afin de consacrer l’essentiel du temps et de l’énergie à imprimer et diffuser les affiches.
C’est aussi le même besoin qui revient avec les réseaux sociaux, où le besoin est d’avoir un visuel commun identifiable (par exemple avec le logo de l’association), puis de pouvoir ajouter un texte dessus pour inviter à une action ou un événement.
Par ailleurs, mettre à disposition ce type d’outil permettant en quelques clics de partager un visuel (une affiche, par exemple), de l’imprimer, ou de créer un code QR personnalisé, nous semble utile dans le contexte social et politique actuel.
Ce sont justement à ces besoins que répond le logiciel Aktivisda.
Pour l’instant, aucune version « diffusée par Framasoft » n’est disponible, mais nous travaillons avec le développeur originel, ainsi que la société qui l’emploie (Telescoop) afin de faciliter son déploiement pour de multiples organisations, ainsi que l’ajout de nouveaux visuels (il faut actuellement passer par Framagit, ce qui peut être fastidieux).
Nous espérons donc, d’ici la fin de l’année, revenir avec de bonnes nouvelles du côté de Aktivisda :)
Dans les coulisses
S’il y a un logiciel dont l’usage s’est massifié dans le paysage associatif ces dernières années, c’est bien Canva. Ce logiciel (non libre, et qui ne se prive pas de nourrir des entreprises tierces d’intelligence artificielle avec vos données) permet de créer rapidement des designs ou des présentations.
Le logiciel libre le plus proche est probablement l’excellent Polotno Studio. Malheureusement, il n’est que très partiellement libre.
C’est un peu par hasard, lors des JDLL 2023 que nous avons découvert Aktivisda. En décembre 2023, nous rencontrions alors son développeur, Marc-Antoine, avec qui nous avons discuté de ses projets pour Aktivida, mais aussi de nos envies et de nos besoins d’un logiciel plus simple à déployer. Les échanges se sont poursuivis ponctuellement, mais régulièrement, avec l’objectif de rendre le logiciel multi-tenant, c’est à dire facilement utilisable par de multiples individus ou organisations. Marc-Antoine et ses collègues sont actuellement en train d’explorer le sujet (de façon bénévole, précisons-le), et nous y verrons donc plus clair d’ici quelques semaines.
Framaspace : gestion des adhérent⋅es, de la comptabilité, nouvelles applications
Comme évoqué plus haut, l’année 2024 sera largement dédiée à améliorer la prise en main et l’accompagnement des utilisateur⋅ices qui découvrent Framaspace.
Cependant, cela ne signifie pas que nous n’allons pas avoir de missions plus techniques. Ainsi, nous comptons passer tous les espaces en version 29 (vous pouvez en lire une description en français chez nos ami⋅es d’Arawa. En parallèle, nous allons évaluer l’ajout de quelques applications, comme par exemple Tables qui permet de construire et partager une petite base de données, ou Impersonate pour permettre à l’admin d’un espace de dépanner un utilisateur. Suivant vos retours sur Excalidraw (évoqué plus haut), nous pourrons aussi le proposer comme application complémentaire.
Cependant, le plus gros du travail, qui commencera au second semestre 2024, sera de voir jusqu’où nous pouvons aller dans l’intégration de Paheko dans Framaspace. Paheko est un logiciel libre de gestion d’associations complet et qui bénéficie aujourd’hui d’une belle réputation. De plus son développeur est français, et impliqué dans différentes communautés libristes depuis longtemps. Lors du dernier camp CHATONS, nous avons commencé à discuter de la possibilité d’intégrer des parties de Paheko à Framaspace. Notamment, nous savons que pouvoir gérer les adhérent⋅es (dates d’entrée et sortie de l’association, gestion des cotisations, etc.), mais aussi la comptabilité (suivant le Plan Comptable Associatif) seraient de gros avantages pour Framaspace. Pour l’instant, nous sommes toujours dans une démarche exploratoire, mais l’idée nous paraît suffisamment importante pour que nous y consacrions du temps et de l’énergie.
Empreinte carbone associative
Nous ne sommes pas climato-sceptiques. Nous considérons que le réchauffement climatique est la mère de toutes les batailles. Nous pensons que la réponse au dérèglement climatique est avant tout politique, et nous sommes irrité⋅es de voir à quel point les politiques publiques sont avant tout orientées, parfois de façon très culpabilisantes, sur les gestes individuels. Cependant, pour pouvoir correctement faire face à un problème et y répondre de façon pertinente, il peut être utile de bien comprendre les enjeux, mais aussi les leviers sur lesquels agir. C’est dans cette optique que Framasoft, en partenariat avec le groupement de recherche Labos 1point5 souhaite proposer, à moyen terme, une application en ligne permettant d’évaluer l’empreinte carbone de son association (ainsi qu’un simulateur permettant de voir l’impact de chaque levier activable).
Dans les coulisses
Il n’y a pas, et il n’y aura jamais de numérique « vert ». Le numérique est intrinsèquement écocidaire. Cependant, nous vivons dans un monde où le numérique existe, et a aussi des apports (pour calculer, pour communiquer, pour être en lien, pour faire ensemble, etc.). Et ni vous, ni nous, ni personne, ne peut faire disparaître le numérique d’un claquement de doigts. C’est ce qu’on appelle une problématique complexe, face à laquelle aucune solution n’est triviale. Les solutions aux problèmes complexes reposent souvent sur des décisions politiques à grande échelle. Et le plus souvent, ces décisions font face à une grande réactance au début, ce qui est assez naturel.
Concernant le réchauffement climatique, nous ne croyons pas aux « petits pas », et nous condamnons les politiques publiques qui pointent beaucoup plus facilement les gestes individuels (le fameux « pipi sous la douche ») plutôt que les actions à grande échelle.
Cependant, pour bien comprendre un problème complexe, il faut pouvoir prendre conscience des « sous-problèmes » qui le composent. Et là, ça tombe bien, Framasoft peut avoir un (petit) rôle à jouer.
Ainsi, nous avons été contacté·es il y a quelques mois par le Groupement de Recherche Labos 1point5 qui propose, pour les labos de recherche (Universités, CNRS, etc.) des outils pour évaluer et comprendre l’empreinte carbone liée au laboratoire. Ils et elles nous ont annoncé travailler sur un outil équivalent, mais destiné aux associations et nous ont demandé si nous serions d’accord pour « porter » ces outils auprès du monde associatif.
Pour être franc⋅hes, nous avons d’abord hésité, car ce genre d’outils fait souvent l’objet de gros biais de calcul, et « oublie » le scope 3 (et même parfois le scope 1). Mais nous avons testé l’outil, et l’avons trouvé très complet. Par ailleurs, le fait que ces outils soient produits par des chercheuses et chercheurs pointu⋅es sur ce sujet permet de sortir des nombreuses démarches marketing de « greenwashing » que l’on peut observer ces derniers temps.
Nous avons donc entamé un dialogue qui nous semble fort constructif. Pour l’instant, nous laissons l’équipe de recherche avancer sur le sujet, et nous vous tiendrons informé⋅es des avancées d’ici quelques mois.
D’ici là, si votre association est intéressée à tester lesdites avancées ou à participer aux échanges avec les chercheuses et chercheurs, vous pouvez vous inscrire au panel d’associations testeuses.
Proposer votre association comme beta-testeuse
D’autres ajouts sur Framalab ?
Ah… Framadate sur mobile… Si on avait touché 1€ à chaque fois que l’on avait reçu une plainte concernant l’usage de Framadate sur smartphone, nous n’aurions probablement pas besoin de faire de collecte 😅.
Cependant, le code de Framadate est tellement daté (certaines parties du code datent de 2008) qu’il paraît aujourd’hui bien plus simple de repartir de zéro.
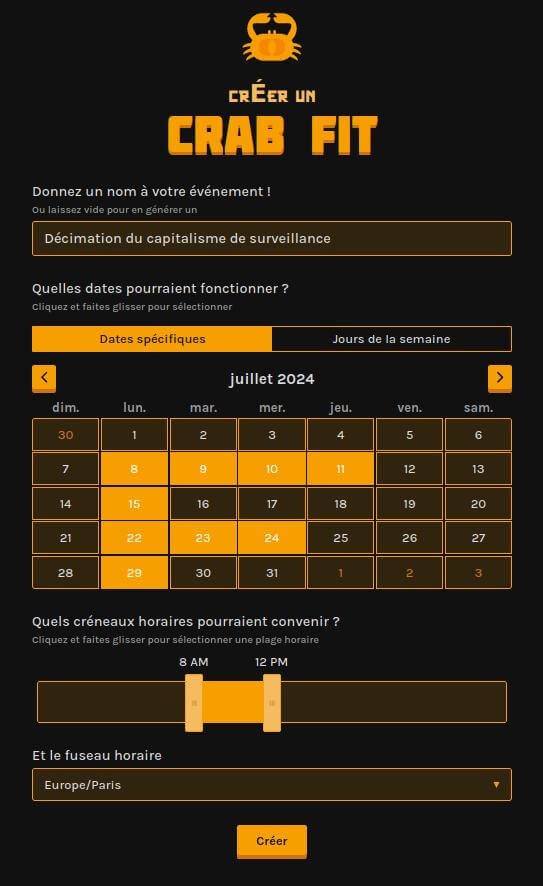
Ça tombe bien, des logiciels alternatifs comme https://rallly.co/fr ou https://crab.fit/ s’y sont lancés. Mais aussi, plus localement, la DINUM en 2021 ou, encore plus proche, la communauté CHATONS.
Bref, ça ne sera pas pour tout de suite, et surtout, on ne sait pas encore quelle sera la voie (longue, mais libre) suivie par Framasoft, mais les choses avancent :)
D’autres logiciels sont évidemment envisagés, comme Hedgedoc, par exemple. N’hésitez pas à signaler vos envies et besoins sur notre forum.
Nous étudions aussi de près la possibilité de mettre à votre disposition des outils « No Code » comme Baserow ou NoCoDB, car ils nous semblent répondre à des besoins courants. Cependant d’un point de vue technique, ce n’est pas simple (ces logiciels sont gourmands et coûtent donc cher à héberger), et il s’agit de logiciels un peu complexes à prendre en main, donc il faudrait aussi travailler à leur accompagnement.
Pour tout cela, nous avons (encore) besoin de votre aide
Félicitations si vous nous avez lu jusqu’ici, car nous avions beaucoup à dire !
Vous l’aurez compris, de nombreux chantiers sont en cours, et il nous faudra des semaines, voire des mois, pour les faire avancer.
Cependant, comme toujours, nous ne pourrons nous atteler à ces projets que si vous nous donnez les moyens de le faire.
Pour cette campagne, le montant de 60 000 € demandé est le minimum vital pour nous permettre de maintenir l’existant comme nous l’avons fait ces 12 derniers mois, et de mettre en place les projets déjà engagés en 2024, si nous atteignons cette somme, nous pourrons alors plus facilement mettre en place les projets exploratoires évoqués plus haut.
Nous pensons sincèrement que nous avons la possibilité de faire bouger les lignes, comme nous l’avons fait avec Framadate, Framalistes, Framapad, ou maintenant Framaspace. Le contexte politique et social actuel nous presse à « outiller la société de contribution », c’est à dire à équiper numériquement celles et ceux qui souhaitent changer le monde vers plus de collectif, plus de diversité, plus de communs. Notre boussole reste notre volonté de vous proposer des outils libres et éthiques, un peu comme si nous fournissions des planches, des marteaux et des clous numériques pour que vous puissiez concrétiser les projets qui vous ressemblent, et non ceux qui sont téléguidés par les géants du numérique.
Nous pensons avoir prouvé lors de ces dix dernières années de « dégooglisation » que votre confiance n’était pas mal placée, et que chaque euro perçu avait été bien dépensé.
Aujourd’hui, au regard de nos ambitions à vous proposer de nouveaux services (mais aussi à maintenir ceux qui sont en place !), nous faisons donc de nouveau appel à votre générosité, en vous rappelant que l’association Framasoft ne vit que de vos dons, et en vous invitant donc, si vous en avez l’envie et les moyens, à nous soutenir pour cette nouvelle campagne. Merci 🙏
Soutenir la campagne « Dorlotons Dégooglisons #2 »





























{kind=link}
{kind=link}