Framasoft vous propose d’essayer le prototype de Lokas, une nouvelle application de transcription « speech to text » qui respecte votre vie privée. Cette démo fonctionnelle est aussi une expérimentation de Framasoft dans le domaine de l’IA, accompagnée du site Framamia, que l’on présente ici.
Facilitez vos prises de notes avec Lokas
Lokas est une application (sur smartphone Android ou iOS) qui permet de transcrire le son de voix en fichier texte.
En gros, pour une réunion : vous mettez le téléphone au centre de la table, vous appuyez sur le bouton « Enregistrer » en début de réunion, sur « Arrêter » en fin de réunion, et l’application vous renvoie quelques minutes après un fichier texte reprenant les phrases prononcées par chacun et chacune.
Lokas permet et surtout permettra pas mal d’autres choses, mais nous y reviendrons en fin d’annonce.

Lokas, c’est pour qui ?
Lokas s’adresse à toute personne qui participe à des réunions. Autant dire un paquet de personnes sur la planète :)
Nous pouvons cependant partager quelques cas d’usages.
Premier exemple : une AG associative
Imaginons une Assemblée Générale associative. Il y a 15 personnes dans la pièce, 2 animateur⋅ices, 1 personne à la prise de notes. Et une réunion de 2H.
Les soucis :
- La prise de notes est épuisante
- La personne qui prend les notes voit sa participation limitée
- Les notes peuvent être incomplètes (un « trou » dû à une pause pipi)
Ce qu’apporte Lokas ?
Lokas permet d’assister la personne qui prend les notes, et lui permettra de participer plus facilement (tout en autorisant la pause pipi !).
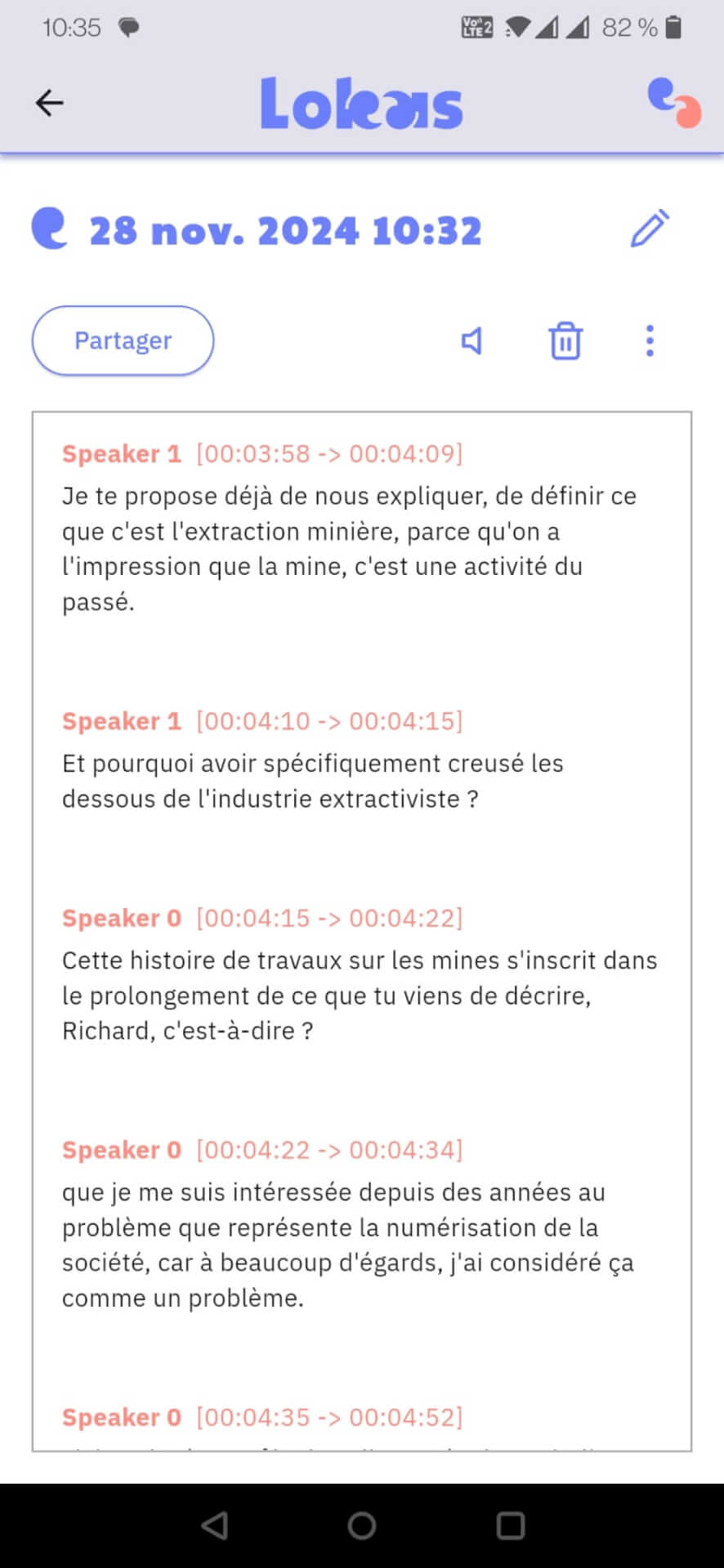
Exemple de transcription d’un échange vocal avec l’application Lokas
Second exemple : un atelier avec des ados
Un atelier de l’association « Les petits débrouillards ». 3 groupes de 5 adolescent⋅es. Une majorité de filles dans les groupes.
Les soucis :
- La prise de notes peut être très compliquée
- Les garçons monopolisent la parole
Ce qu’apporte Lokas ?
Lokas permet de garder trace (sonore et écrite) de ce qu’il s’est dit. Et permet d’établir des statistiques de temps de paroles, notamment par genre, afin d’objectiver le fait que les garçons ne laissent que peu de temps de paroles aux filles.
Troisième exemple : une réunion de travail en visio, en langue étrangère
Votre collectif militant est proche d’une association espagnole. C’est Camille, une bénévole de votre collectif, qui parle à peu près l’espagnol, qui fera la visio avec son interlocutrice madrilène. La visio a donc lieu dans une langue étrangère.
Les soucis :
- Vous avez besoin de pouvoir réécouter à tête reposée
- Vous avez besoin d’une transcription en français et de la partager aux membres du C.A.
Ce qu’apporte Lokas ?
Avec Lokas, Camille pourra réécouter la visio, la transcrire automatiquement en français, et la partager depuis votre smartphone (par mail, via Signal, Matrix, WhatsApp, Telegram, etc).
Soutenir Lokas (et Framasoft)
L’IA n’est pas magique ✨. Lokas non plus 🤷.
Lokas n’est qu’un outil. Il peut vous assister dans la prise de notes. Cependant, comme tout outil, il ne doit pas vous dispenser d’utiliser votre cerveau !
L’invention de l’écriture (une autre technologie, très perfectionnée) date d’au moins 3 000 ans. Cela fait donc au moins aussi longtemps que l’humanité est capable de se réunir et de garder des traces écrites. Sans IA. Sans smartphone. Ne jetez pas plusieurs millénaires de techniques avec l’eau de l’IA. Un outil comme Lokas pourra être utile dans certains cas, et complètement gadget, voire improductif, dans d’autres cas. Cela n’est pas sans rappeler le concept de Pharmakon, cher au philosophe Bernard Stiegler : Lokas, comme tout objet technique, est à la fois poison, remède, et bouc-émissaire.
Par exemple le web est « à la fois un dispositif technologique associé permettant la participation et un système industriel dépossédant les internautes de leurs données pour les soumettre à un marketing omniprésent et individuellement tracé et ciblé par les technologies du user profiling. ». Remède et poison.
De la même façon, Lokas pourra être émancipateur (en facilitant la participation plutôt que la prise de notes), ou au contraire contraignant (les réunions un peu foutraques dans un bar bruyant ont aussi leur intérêt, il ne faudrait pas s’en passer parce que l’outil fonctionne mieux dans un environnement calme), ou frustrant (« l’application a planté, je n’ai aucune note de secours ! La technologie, c’est de la mârde ! »).
Lokas, comme une voiture, un marteau, un stylo, n’est pas un outil « neutre ». À vous de voir, collectivement, si vous souhaitez l’utiliser, et comment.
Forcément, ça va moins bien marcher – CC-By SA Gee
« C’est l’histoire d’une app… »
Il nous semble intéressant de pouvoir vous raconter comment est née l’application Lokas. C’est lever un coin de rideau sur les coulisses de Framasoft, comprendre comment nous pouvons prendre la décision de faire (ou de ne pas faire) tel ou tel projet. C’est aussi montrer que parfois, avec un peu de chance et d’huile de coude clavier, on peut faire des choses qui pourraient paraître impossibles. Cependant, comme cette partie n’est pas indispensable, on vous laisse le choix d’en prendre connaissance ou pas.
Cliquez ici pour lire (l’improbable et fabuleuse) histoire de Lokas
Cela fait bien trois ou quatre ans que l’idée de Lokas traîne dans la tête de pyg, membre de Framasoft.
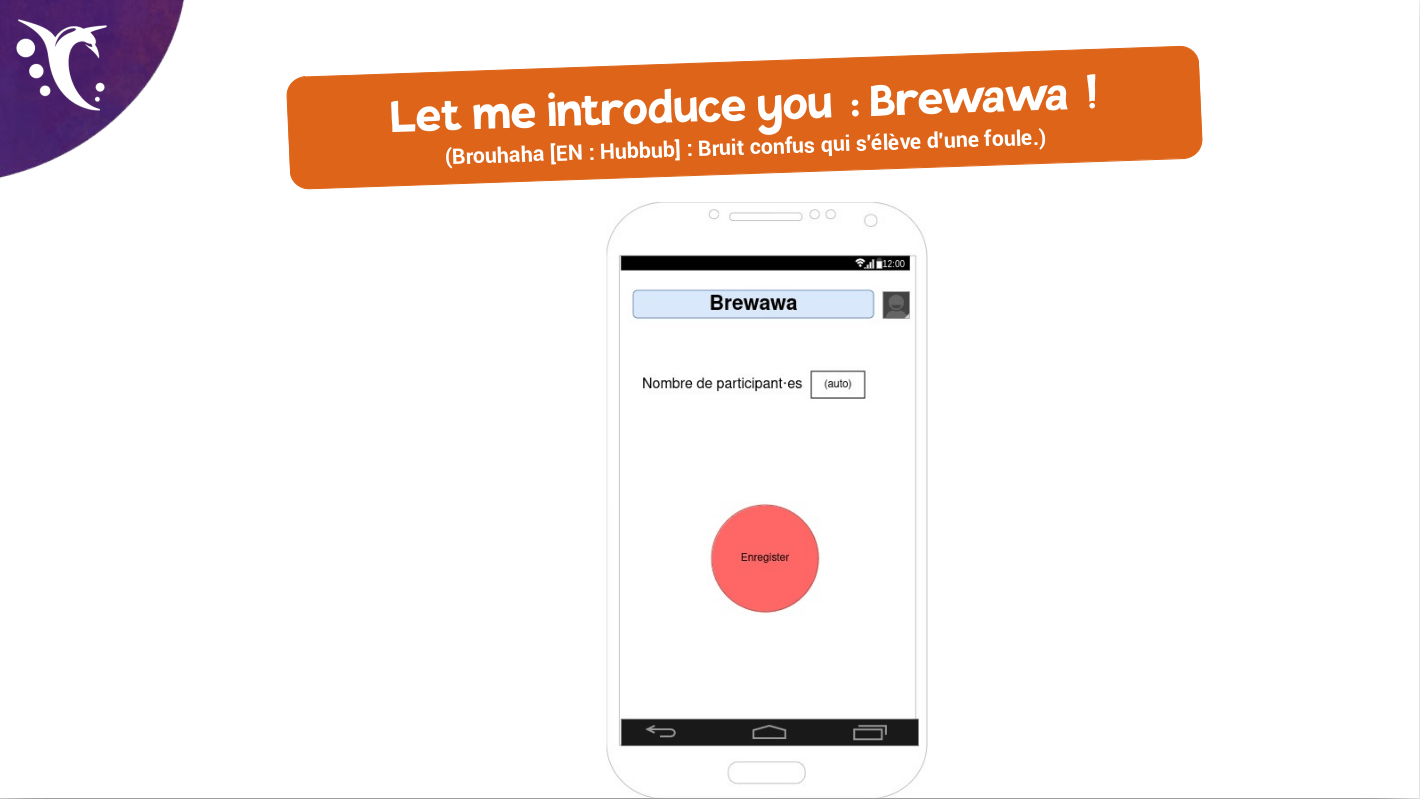
L’idée de départ (nom de code : « Brewawa »), c’était surtout d’imaginer une application qui serait capable de calculer le temps de parole de locuteur⋅ices dans une réunion. Le but (pas du tout caché) était de démontrer facilement que lors d’une discussion avec des personnes de genres différents, ce sont de façon très très majoritairement les hommes qui monopolisent la conversation.
Différents essais ont été réalisés ces dernières années (coucou Gee, coucou bjnbvr !) pour étudier la faisabilité d’une telle application. Mais le fait est qu’en 2020, même si les possibilités techniques étaient présentes, elles n’étaient pas vraiment accessibles pour notre toute petite association, surtout sur un projet parallèle à tous ceux que Framasoft menait déjà.
« C’est l’histoire d’améliorations techniques… »
Cependant, avec le développement de logiciels tels que Vosk ou Whisper, les capacités de transcription audio (c’est-à-dire la capacité à transformer le son de phrases en texte) se sont largement améliorées.
À tel point qu’aujourd’hui, ces technologies sont utilisées par énormément de logiciels (de YouTube à PeerTube, en passant par BigBlueButton ou WhatsApp), et souvent même directement intégrée dans des appareils (Samsung en fait clairement un argument de vente).
Par ailleurs cette dernière décennie a aussi vu s’améliorer les processus de « diarisation ». Ce terme un peu barbare est en fait la technique qui permet d’identifier différent⋅es locuteur⋅ices dans une discussion. Par exemple, si Alex, Camille et Fred font une réunion, la diarisation saura attribuer à chacun⋅e les phrases qu’il ou elle aura prononcées (non, le logiciel ne va pas deviner le prénom de la personne, mais il saura – à peu près – identifier qu’il y avait trois participant⋅es, et dire « Cette phrase a été prononcée par la personne #1. Cette phrase a été prononcée par la personne #2. », etc.
C’est évidemment une phase essentielle pour pouvoir comprendre « qui a dit quoi » dans une réunion.
Ce processus est encore imparfait, mais s’améliore de mois en mois. Il faut donc se projeter en 2026 ou 2027 pour imaginer une diarisation vraiment fiable, mais elle est aujourd’hui « suffisante » dans 60 à 80 % des usages en « bonnes conditions ».
« C’est l’histoire d’un alignement de planètes… »
Il se trouve qu’au sein de Framasoft, les compétences nécessaires pour le développement d’une telle application étaient réunies.
Chocobozzz, le développeur de PeerTube, avait déjà beaucoup travaillé sur le processus d’intégration de Whisper à PeerTube, afin de pouvoir générer automatiquement les sous-titres d’une vidéo. Il connait donc bien Whisper, ses options de configuration, ses performances, etc.
Wicklow, le développeur de l’application PeerTube, travaille depuis plusieurs mois avec le langage Dart et le SDK Flutter qui permet de développer en une seule base de code une application pour différents terminaux (Android, iPhone, ordinateur/tablette, web, etc).
Luc, notre administrateur système préféré (c’est pas compliqué, remarquez, nous n’en avons qu’un 😅) gère l’intégralité de l’infrastructure technique de Framasoft (une soixantaine de serveurs informatiques physiques). Donc, mettre en place la machine qui gère les transcriptions, l’installer, la sécuriser, etc, était pour lui un jeu d’enfant.
pyg, anciennement directeur de Framasoft, aujourd’hui coordinateur des services numériques de l’association, a géré d’innombrables projets pour Framasoft ces 20 dernières années. Alors, un de plus, même en pleine campagne, ça n’allait pas l’arrêter.
Entre cet ensemble de compétences, et les capacités techniques des logiciels de transcriptions et diarisation, les planètes étaient donc alignées pour lancer un tel projet.
« C’est une histoire de chance… »
Cependant, comme souvent, il faut un peu compter aussi sur le hasard ou la chance.
En effet, pyg avait un peu laissé tomber l’idée de cette application, tout simplement par ignorance des avancées techniques en termes de diarisation.
C’est en évoquant l’idée de cette application lors du dernier Framacamp, en juillet 2024, que Wicklow a lâché une info au détour de la conversation : « Ah, mais tu sais, Whisper fait maintenant une diarisation correcte. »
BIM 💣
« Ah, super intéressant ! Mais j’imagine qu’il faudrait longtemps pour développer une telle application de transcription libre ? » lui demanda pyg.
« Oh, je dirais qu’en 3 jours, je peux avoir un prototype fonctionnel si Chocobozzz se charge de la partie serveur. »
BOUM 💥
Autant vous dire qu’au lieu de profiter de sa soirée à jouer au poker, pyg a filé dans sa chambre, préparé une présentation d’une douzaine de diapositives sur un potentiel projet d’application, qu’il a présenté à l’association le lendemain matin.
Une des diapos produites pendant la nuit…
Certain⋅es membres étaient enthousiastes, d’autres moins. Et on les comprend : d’une part, c’était encore ajouter du travail à une association déjà particulièrement chargée et épuisée ; d’autre part, c’était un projet utilisant un logiciel issu de l’intelligence artificielle, une technologie sur laquelle nous sommes (unanimement) très critiques.
Cependant, cette application, qui allait devenir Lokas, nous semblait un bon moyen « d’incarner » l’objet social de Framasoft : faire de l’éducation populaire aux enjeux du numérique et des communs culturels.
Cela nous permettait en effet de sortir de l’aspect discours pédagogique, à la fois indispensable, mais insuffisant en termes d’appropriation et d’autodétermination. En créant un « objet numérique manipulable », nous pouvions faire de Lokas une occasion complémentaire de faire comprendre ce qu’est l’IA, ses possibilités, mais aussi ses faiblesses. Et revenir, donc, à notre « Pharmakon » évoqué plus haut.
Par ailleurs, en plus de pouvoir assister tout collectif faisant des réunions, cela nous permettait de mettre en œuvre, concrètement, une application portant nos valeurs : un outil convivial, n’exploitant pas les données des utilisateur⋅ices, sous licence libre, s’adressant avant tout aux personnes qui changent le monde pour plus de progrès social et de justice sociale.
Au final, la majorité des membres présent⋅es s’est exprimée : « Banco la caravane ! On se lance ! ».
« C’est (aussi) une histoire de contraintes »
Comme évoqué plus haut, les contraintes étaient fortes.
Un projet, ça coûte forcément en temps et en argent. Du temps et de l’argent qui ne pourront pas être utilisés ailleurs.
Or, il ne vous a pas échappé que Framasoft vit des dons. Il faut donc faire des campagnes de dons. Et la fin de l’année était déjà particulièrement chargée par la finalisation de différents projets et leurs annonces
En discutant avec Thomas et Pouhiou, codirecteurs de l’association, il a donc été décidé que Lokas devrait rester un projet sous contraintes fortes : coûter moins de 10 000€ tout compris ; ne pas impacter fortement les missions de Chocobozzz, pyg, ou Wicklow ; être réalisé (à « temps perdu », donc) entre mi-septembre et mi-novembre (notamment à cause des délais de validation des stores Android et iOS, que nous ne maîtrisons pas).
Avec de telles contraintes, impossible pour nous de réaliser un produit bien finalisé. Nous avons donc décidé de viser plutôt la mise à disposition d’un prototype. Voyez ce prototype comme un appartement témoin. Nous avons produit cette version non pas en nous focalisant sur un projet de long terme, avec des fondations solides, mais plutôt comme une « preuve de concept », développée rapidement, pour voir si le concept est suffisamment attirant et intéressant pour qu’en 2025 nous priorisions le développement de cette application (si les dons sont suffisants, donc !).
Afin de vous donner suffisamment « envie » de voir un jour une version 1.0 de Lokas arriver, nous avons fait appel aux compétences de l’Atelier Domino pour la création d’un logotype et d’une charte graphique. Ce qui nous a guidés pour réalisé en interne le site web du projet : lokas.app
En parallèle, Wicklow et Chocobozzz se sont attaqués au développement du prototype, ainsi qu’à la partie serveur de transcription.
« C’est une histoire qui ne demande qu’à être écrite… »
Une quinzaine de jours de travail plus tard (et un coût estimé à 7 500€ tout compris, avec en gros moitié de temps de travail Framasoft, et moitié prestations : Atelier Domino, location du serveur, des noms de domaines, validation des stores), nous pouvons présenter, avec fierté et un peu d’anxiété, notre prototype !
Soutenir Lokas (et Framasoft)
Lokas, comment ça marche ?
1. Se mettre dans les bonnes conditions
Lokas, comme tous les outils de transcription, d’ailleurs, est imparfait. Des bruits extérieurs, une mauvaise articulation, une voix fluette en fond de salle, des personnes qui se coupent la parole… Autant de raisons qui peuvent nuire à la transcription.
En conséquence, prévoyez de vous mettre au calme, de placer le téléphone au centre de la table (meilleure est la qualité sonore, meilleure est la transcription), n’ayez pas plusieurs discussions en même temps, et… prenez des notes « à l’ancienne » à côté (papier+crayon, ordinateur+pad, etc) en cas de souci.
Une fois cela fait, le fonctionnement est très simple.
L’IA c’est pas magique : Lokas nécessite de bonnes conditions – CC-By SA Gee
2. Lancer l’enregistrement
Cliquez simplement sur le bouton « Enregistrement ». Placez le téléphone de façon à ce qu’il puisse capter au mieux les échanges. Et commencez votre réunion.
Enregistrement d’une réunion
Afin de limiter les abus, les enregistrements sont limités à 5 par jour et par appareil.
Notez que le modèle de langue géré par Lokas permet de l’utiliser d’ores et déjà dans une cinquantaine de langues, notamment : Néerlandais, espagnol, coréen, italien, allemand, thaïlandais, russe, portugais, polonais, indonésien, mandarin, suédois, tchèque, anglais, japonais et bien entendu français ! D’autres langues sont supportées, mais la reconnaissance sera moins performante.
À la fin de la réunion, cliquez sur « Finaliser ».
3. Envoyez votre fichier pour transcription (et patientez)
Vous pourrez éventuellement réécouter votre fichier avant de cliquer sur « Envoyer ».
Votre fichier est alors envoyé sur notre serveur où il sera placé dans la file d’attente pour sa transcription.
Cette étape pourra prendre de quelques minutes à quelques heures, suivant le nombre de fichiers en attente.
Vous pourrez vérifier manuellement si votre fichier a bien été transcrit, ou attendre tranquillement la notification (dont la tâche de vérification est exécutée toutes les 15mn)
L’écran signifiant l’envoi du fichier audio aux serveurs de Framasoft
Une fois la transcription reçue
Une fois la transcription reçue, vous pourrez l’afficher dans Lokas.
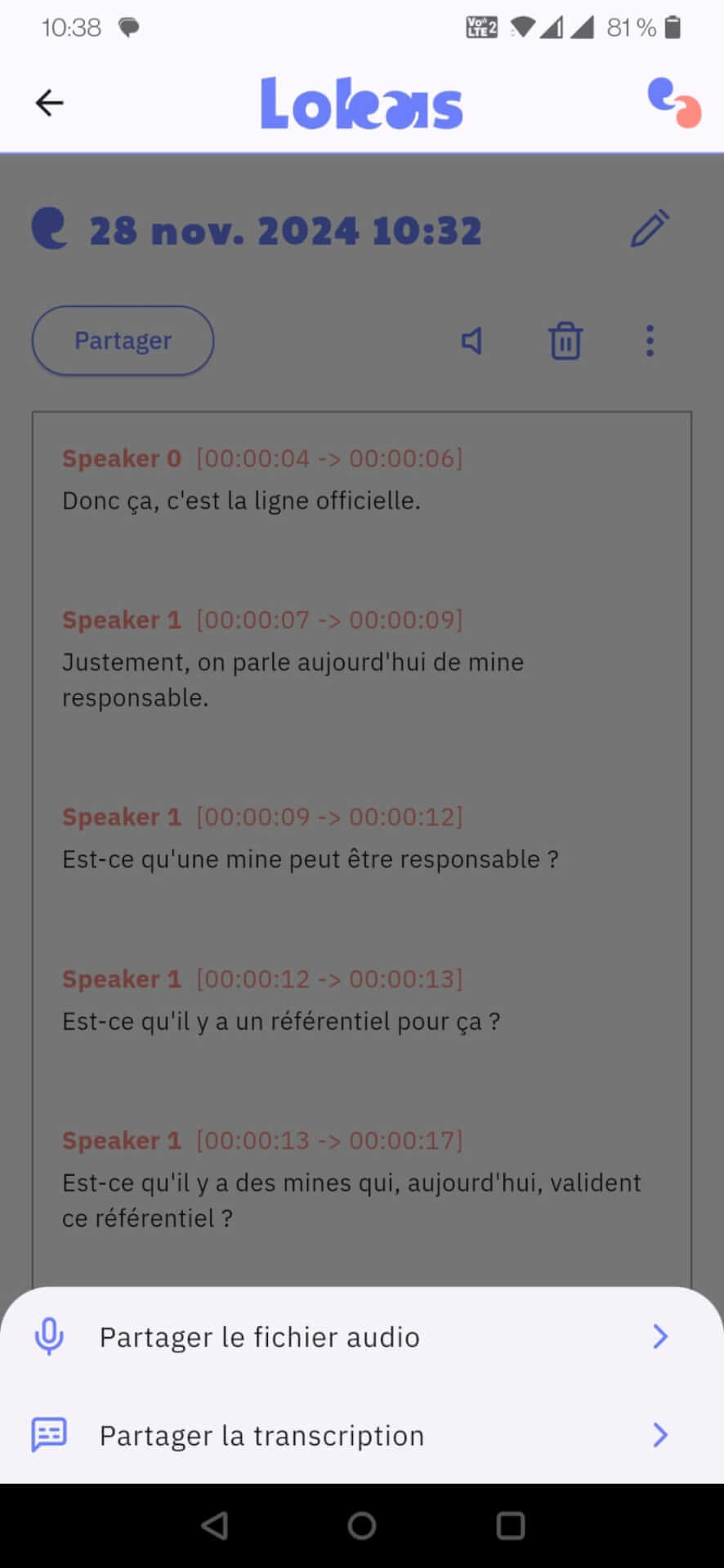
Vous pourrez évidemment la partager (avec l’application de votre choix : mail, Signal, WhatsApp, etc) pour la corriger.
Affichage du menu de partage (audio ou texte) dans Lokas. En fond d’écran, la transcription.
Vous pourrez aussi voir les statistiques de temps de parole (NB : cette fonctionnalité est relativement expérimentale). Si vous le souhaitez, pour une meilleure lecture des notes, vous pouvez attribuer un prénom (ou pseudo) aux participant⋅es. Pour obtenir des temps de parole par genre, vous pouvez aussi les attribuer manuellement, en vous assurant évidemment du consentement des personnes concernées à communiquer cette information. Notez que ces informations sont volontairement manuelles, et ne quittent pas votre téléphone, et ne sont donc pas transmises à Framasoft ou qui que ce soit.
Aperçu des temps de parole, ainsi que des noms et genres des participant⋅es (aucune de ces informations n’est transmise à Framasoft)
Point confidentialité : l’une des particularités de Lokas est que nous respectons votre vie privée : le fichier audio est enregistré sur votre téléphone. Il est envoyé, à votre demande, sur nos serveurs, qui se chargeront alors de sa transcription. Une fois la transcription terminée, une notification est envoyée sur votre téléphone ; lorsque vous ouvrez (dans « Mes fichiers ») la réunion en question, la transcription est alors téléchargée sur votre téléphone. Une fois cette étape réalisée, et après un léger délai pour s’assurer que tout s’est bien passé techniquement, tout est supprimé de notre serveur : le fichier audio ainsi que la transcription. Par ailleurs, si vous attribuez des noms, pseudos ou genres, pour les statistiques, sachez que ces informations ne font l’objet d’aucun traitement de notre côté.
Soutenir Lokas (et Framasoft)
Et l’IA dans tout ça ?
À Framasoft, nous ne sommes pas fans du tout de l’IA. Nous pensons que cette technologie (ou plutôt cet ensemble de technologies), pose plus de problèmes qu’elle n’apporte de solutions. Nous avons d’ailleurs essayé de présenter une synthèse de notre position sur l’I.A. au sein du site Framamia, que nous présentons ici sur le Framablog.
Alors, n’est-ce pas contradictoire d’utiliser l’IA au sein d’applications Framasoft, comme Lokas ou PeerTube ?
À notre sens, non. Et ce pour plusieurs raisons.
D’abord, comme nous l’écrivions dans le site Framamia, tous les modèles d’intelligence artificielle ne se valent pas. Whisper, le logiciel qui sert à la transcription, est une IA « spécialisée », et non une IA « généraliste » comme ChatGPT par exemple.
« Les modèles spécialisés, quant à eux sont optimisés pour résoudre efficacement une tâche précise. Leur impact est souvent maîtrisé, et peut correspondre à celui d’un autre logiciel. ».
Framasoft, sur le site Framamia.org
Whisper est certes une IA, mais qui tourne « en vase clos » sur nos serveurs.
Les algorithmes utilisés sont plus complexes qu’un filtre « Enlève les yeux rouges de cette photo » avec GIMP ou Photoshop, mais cela reste un modèle relativement simple (avec un processus d’entrées/sorties) infiniment moins énergivore qu’un modèle d’entraînement. En effet, l’inférence (le processus d’utiliser le modèle pour effectuer une tâche) consomme bien moins d’énergie que l’entraînement. Par exemple, exécuter Whisper pour transcrire un fichier audio de quelques minutes nécessite une puissance de calcul relativement modeste.
Ensuite, un projet comme Lokas ne nécessite pas d’acheter 350 000 puces GPU pour 9 milliards de dollars, comme l’a fait récemment Meta/Facebook, ce qui représente en gros le PIB du Togo en 2023. Nous ne pensons pas participer à la croissance de la bulle financière autour de l’IA, ou à faire faire s’emballer le capitalisme algorithmique.
Enfin (et surtout), avec Lokas ou PeerTube, nous demeurons cohérent⋅es avec une des valeurs au cœur de Framasoft, à savoir le respect de la confidentialité de vos données. En effet, nous ne faisons aucune exploitation de vos fichiers, en dehors de la tâche explicitement demandée, par exemple la transcription. Elles ne servent pas à enrichir un modèle d’IA à partir de vos discussions, de votre identité, etc. Nous ne conservons pas les fichiers audio ou texte, nous n’avons pas accès aux noms/prénoms/genres que vous attribuez manuellement aux participant⋅es d’une discussion (ça reste sur votre téléphone), etc. Et, évidemment, vos données ne sont JAMAIS monétisées.
Bref, Framasoft se fiche du contenu de vos données, elles vous appartiennent et ne regardent que vous.
Malgré cela, nous respectons le point de vue des personnes qui souhaitent boycotter l’IA, et nous entendons la contradiction qu’iels pourraient trouver à ce qu’une asso technocritique comme Framasoft propose des projets utilisant l’I.A.
Notre objectif est justement de proposer un outil qui permette d’avoir une réflexion concrète, afin de se forger un avis autonome, permettant à chacun et chacune de se construire sa propre position.
Un perroquet mécanique prend des notes : tout un symbole.Illustration de David Revoy – Licence : CC-By 4.0
Lokas c’est pour quand ?
Vous pouvez d’ores et déjà télécharger l’application Lokas sur le Play Store, iOS (toujours en testflight chez Apple, parce qu’ils sont 🤬… disons tatillons. EDIT : c’est maintenant disponible !), f-droid (en cours), ou avoir l’apk Android en téléchargement direct ici. Notez cependant que Lokas est un prototype (si ce n’est pas déjà fait, prenez deux minutes pour lire « L’histoire de Lokas » et comprendre pourquoi), et il est donc normal que plein plein plein de choses ne fonctionnent pas !
Nous avons déjà pris du temps, de l’énergie, et un peu d’argent sur des ressources pourtant limitées (on vous a déjà dit qu’on ne vivait que de vos dons ? ;-) ). De plus, comme toujours, le code est libre, nous l’avons publié ici sur notre forge logicielle.
Avant d’aller plus loin, nous avons donc besoin de confirmer que ce projet vous intéresse. Si les dons ne sont pas assez importants, ou si les contradictions sont trop fortes : nous nous arrêterons là. (le code est libre, donc ça ne sera pas « perdu »).
Si, par contre, vous trouvez ça pertinent, les possibilités de développements futurs sont innombrables. Citons par exemple :
- Reprendre complètement le design et l’accessibilité (en mode prototypage, nous sommes allé⋅es très vite, et Lokas est donc très perfectible) ;
- Possibilité de (re)transcrire le fichier de son choix (par exemple issu d’une vidéo ou d’une autre application) ;
- Ajouter un mode « web » à l’application. C’est à dire la possibilité d’utiliser Lokas depuis son ordinateur (sur le modèle de ce que fait le serveur Scribe de nos ami⋅es des Céméa) ;
- Ajouter la possibilité de synthèses automatiques des transcriptions, pour retrouver rapidement les points clés ;
- Traduire l’application (et le site web) dans d’autres langues que le français et l’anglais ;
- Possibilité d’éditer et corriger la transcription directement depuis votre téléphone ;
- Donner la possibilité d’obtenir la transcription dans la langue de son choix (par exemple une réunion en anglais, transcrite en français, ou l’inverse) ;
- etc
Mais pour cela, il va nous falloir du temps salarié, et donc de l’argent. Donc, au risque de paraître insistant, nous vous invitons, si vous le pouvez, à nous faire un don.
Faire une don pour soutenir Lokas
Le défi : 20 000 fois 20 € de dons pour les 20 ans de Framasoft !
Framasoft est financée par vos dons ! Chaque tranche de 20 euros de dons sera un nouveau ballon pour célébrer 20 d’aventures et nous aider à continuer et décoller une 21e année.
Framasoft, c’est un modèle solidaire :
- 8000 donatrices en 2023 ;
- plus de 2 millions de bénéficiaires chaque mois ;
- votre don (défiscalisable à 66 %) peut bénéficier à 249 autres personnes.
À ce jour, nous avons collecté 58 625 € sur notre objectif de campagne. Il nous reste 29 jours pour convaincre les copaines et récolter de quoi faire décoller Framasoft.
Alors : défi relevé ?
Obtenir Lokas Soutenir Framasoft












{kind=link}