Le saviez-vous ? 98 % du budget de Framasoft repose sur des dons (dont 86 % sont des dons de particuliers). C’est donc bien grâce à vous et à votre soutien (merci !) que toutes nos actions sont réalisables. Nous avons ainsi voulu vous faire un résumé de la tambouille concoctée sur cette année 2022. Retour sur 12 mois d’éducation populaire aux enjeux du numérique et des communs culturels, que l’on a voulu riches en saveurs pour le bonheur de vos (et nos !) papilles.
Mais qui est derrière les fourneaux ?
Derrière ce petit festin, il y a qui ? Un petit groupe de 38 personnes : 28 bénévoles et 10 salarié⋅es, convaincu⋅es qu’un monde où le numérique nous permet de gagner en liberté est possible ! On vous raconte ici ce qu’on a fait, réfléchi et avancé dans les cuisines. Et les fours sont encore tout chauds !
Partager nos valeurs, nos intentions et nos actions haut et fort
Après 3 ans de travail, d’ateliers guidés par Marie-Cécile Godwin et de peaufinage par l’association, nous avons publié notre manifeste en novembre. Ce travail de longue haleine nous a fait longuement réfléchir et nous a permis de mettre en évidence très simplement la dimension politique de notre projet associatif : nous voulons changer le monde actuel pour un monde meilleur, où les Communs sont favorisés, où la justice sociale est une valeur fondamentale et où nos libertés sont préservées.
La deuxième partie de cet important travail a été de faire en sorte que nos intentions du manifeste se comprennent dès l’arrivée sur framasoft.org. Nous avons ainsi refondu entièrement notre site internet principal pour rendre notre projet associatif clair, fluide et facilement compréhensible.
Collectivisons Internet / Convivialisons Internet : notre nouvelle feuille de route 2023-2025
Après 5 ans de cap sur Contributopia, nous avions besoin de réaffiner notre compas et revoir notre direction : vers où voulons-nous poursuivre notre exploration pour les prochaines années ? C’est ainsi qu’a été créée la nouvelle feuille de route Collectivisons Internet / Convivialisons Internet (nom de code : COIN / COIN) : nous souhaitons nous adresser plus directement aux collectifs et associations engagées pour un monde meilleur (sans pour autant mettre de côté les milliers de personnes qui utilisent nos outils !).
4 projets ont ainsi été dévoilés et seront progressivement améliorés aux fils des mois grâce aux retours des bénéficiaires, dans l’idée de créer plus de liens entre les outils et les humain⋅es :
- Frama.space : proposer du cloud libéré aux petits collectifs militants
- Peer.tube : mettre en valeur le PeerTube pour lequel nous œuvrons
- Emancip’Asso : favoriser l’émancipation numérique du monde associatif
- ECHO Network : comprendre les besoins de l’éducation populaire dans différents pays d’Europe.
Nous avons détaillé les actions de cette feuille de route et pourquoi nous les entreprenons sur le Framablog.
Se revoir et vous revoir : ça requinque !
Cette année 2022 aura aussi été marquée par la reprise plus intense des moments partagés, en chair et en os (avec de bonnes aérations !) : AG, Framacamp, événements, salons, conférences, festivals, projections de cinéma, tables rondes… Parce que bien que l’on aime faire tout ça, vous voir et nous voir, ça nous motive, ça nous booste et ça nous encourage à continuer à tester de nouveaux projets ambitieux, farfelus et drôles (Vous vous souvenez de Proutify ? L’extension vient d’être mise à jour par un de nos bénévoles)… c’est si important de prendre plaisir à faire tout cela !
Sans vous, tout ce que nous faisons ne serait pas réalisable : 98 % des ressources de l’association sont des dons. Vous trouvez que nos réflexions vont dans la bonne direction ? Si vous en avez les moyens, si vous en avez l’envie, nous vous remercions grandement d’avance de votre soutien.
Je soutiens les actions de Framasoft
En entrée : buffet d’éduc pop’
Pour nous, l’éducation populaire, c’est la base d’un monde meilleur : chacun et chacune peut partager ses connaissances et y accéder, en toute simplicité. On vous présente ici les différentes actions d’éduc pop’ menées cette année.
Partage de connaissances et de points de vue
Pour commencer, Framasoft est intervenue, en présentiel ou à distance, dans divers espaces, pour parler d’émancipation numérique, de numérique alternatif, ou encore de comment se libérer en ligne. C’est plus de 70 interventions que nos membres ont réalisées, pour différentes structures, associations, ou collectifs, dans différentes régions de France. Vous trouverez quelques unes de ces interventions à visionner sur notre chaîne Framatube.
Ensuite, Framasoft garde la plume active sur le Framablog. Plus de 100 articles ont été publiés cette année, entre présentations de nos différentes actions, traductions de Framalang, revue de presse hebdomadaire, claviers invités, interviews de divers projets émancipateurs, articles audio… Le Framablog est un espace où nous nous exprimons sans limite.
Nous sommes aussi intervenues une vingtaine de fois dans les médias lorsque nous avons été sollicité⋅es pour partager nos points de vues sur le numérique : interview vidéos, podcasts, articles… Vous trouverez les différents liens accessibles sur cette page.
Des Livres en Communs : la maison d’édition qui chamboule les codes
Notre maison d’édition Des Livres en Communs (anciennement Framabook), chamboule les codes de l’édition en proposant une bourse aux autrices et auteurs en amont de l’écriture, ainsi qu’une publication de l’ouvrage sous licence libre, uniquement en version numérique.
Suite au premier appel à publication lancé en janvier : « Vers un monde plus contributif, plus solidaire, plus éthique et plus libre : comment s’outiller et s’organiser ensemble ? », le projet « L’amour en Commun », de Margaux Lallemant et Timothé Allanche a été sélectionné. L’objectif de cette publication est de questionner comment le commun de l’amour, en tant que moyen d’organisation et moteur d’engagement, permet de construire une alternative à la société capitaliste.
L’ouvrage est actuellement en création, entre travail de terrain et immersions, tout en étant accompagné par notre comité d’édition.
Des Livres en Communs a également participé à la coédition et aux relectures du « Guide du connard professionnel », travail mené avec PtiloukEditions.
UPLOAD : une université libre qui se garnit
L’Université Populaire Libre, Ouverte, Autonome, et Décentralisée (UPLOAD) est un grand projet d’éducation populaire initié et coordonné par Framasoft (pour le moment), dans une logique décentralisée et en réseau. L’objectif est de contribuer (à notre échelle) à rendre la société plus juste et notre monde plus vivable, en misant sur la formation des citoyen⋅nes par les citoyen⋅nes.
Ce projet est en grande partie formé par les LibreCours, cours en ligne permettant d’accéder à différents savoirs et connaissances. Stéph nous a proposé une conférence pour présenter le sujet lors des Journées du Logiciel Libre.
Les Librecours de cette année auront été rythmés par la thématique « Low-technicisation et numérique » : une première session entre avril et juin et une seconde entre novembre et janvier 2023. Vous trouvez aussi que la croissance exponentielle du numérique est problématique ? Chercher à réduire l’empreinte technique d’un outil vous intéresse ? Vous pouvez retrouver les vidéos des cours par ici.
Peer.tube : une vitrine pour PeerTube qui nous ressemble
Avec Peer.tube, nous souhaitons créer une vitrine de PeerTube, avec du contenu de qualité préalablement sélectionné. C’est notre réponse à une question que l’on peut souvent nous poser : « Mais où est-ce que je trouve du contenu intéressant sur PeerTube ? ». Le site Peer.tube est déjà accessible avec une première sélection de chaînes et vidéos, mais le projet ne va réellement avancer que l’année prochaine.
Notre buffet d’éducation populaire a titillé votre curiosité ? Vous trouvez que nos contributions vont dans le bon sens ? Alors nous vous re-glissons par ici que tout ça nous a été possible grâce à vous et à vos dons – merci !
Je soutiens les actions d’éduc pop’ de Framasoft
En plat : poêlée d’émancipation numérique
Permettre aux citoyens et citoyennes de s’émanciper par le numérique et de libérer leurs pratiques, c’est le cœur de nos actions. Mais, de quoi est composée cette bonne poêlée ? D’ingrédients libérés, de qualité, et d’une bonne pincée d’amour. On vous détaille tout ça.
Des services en ligne pour se passer des géants du numérique
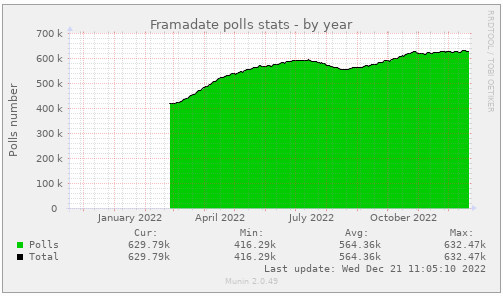
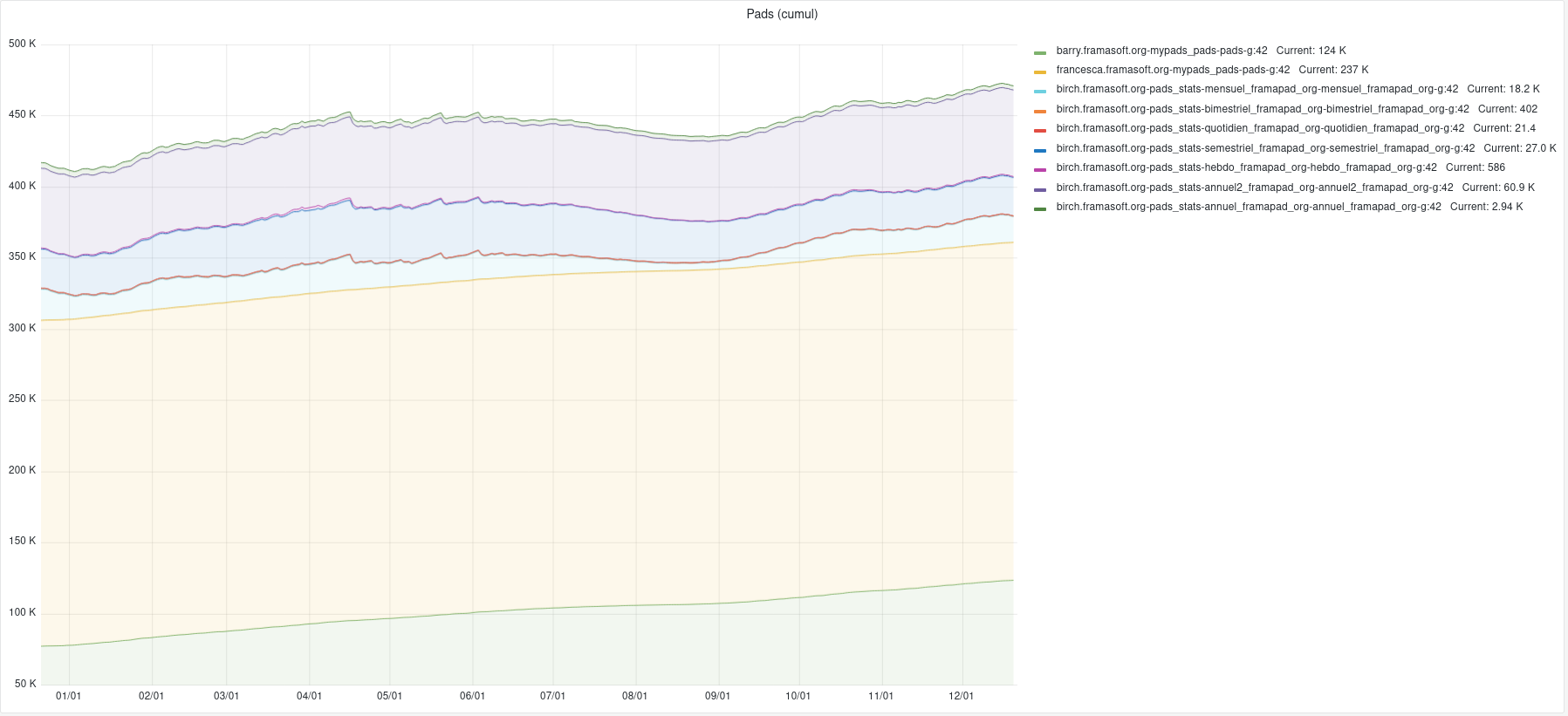
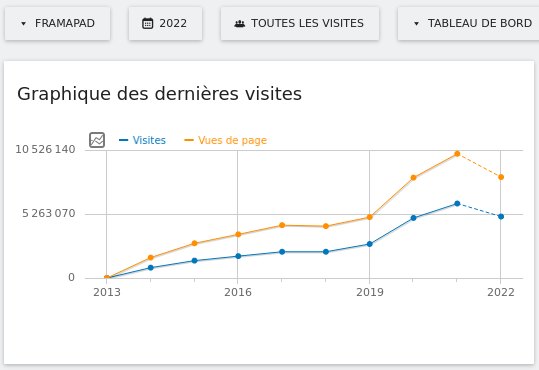
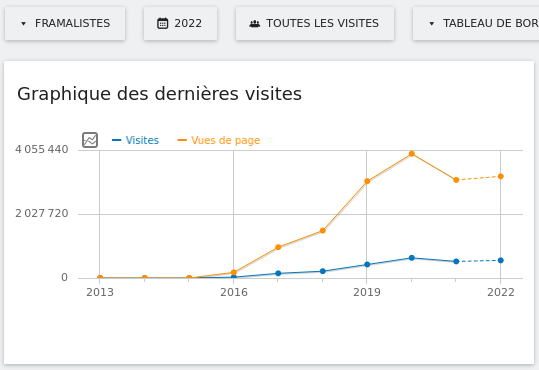
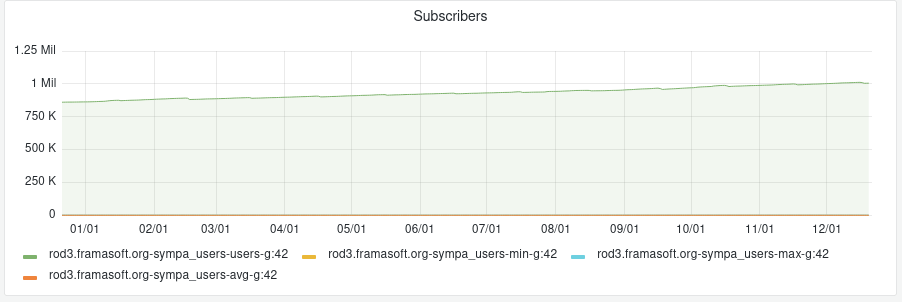
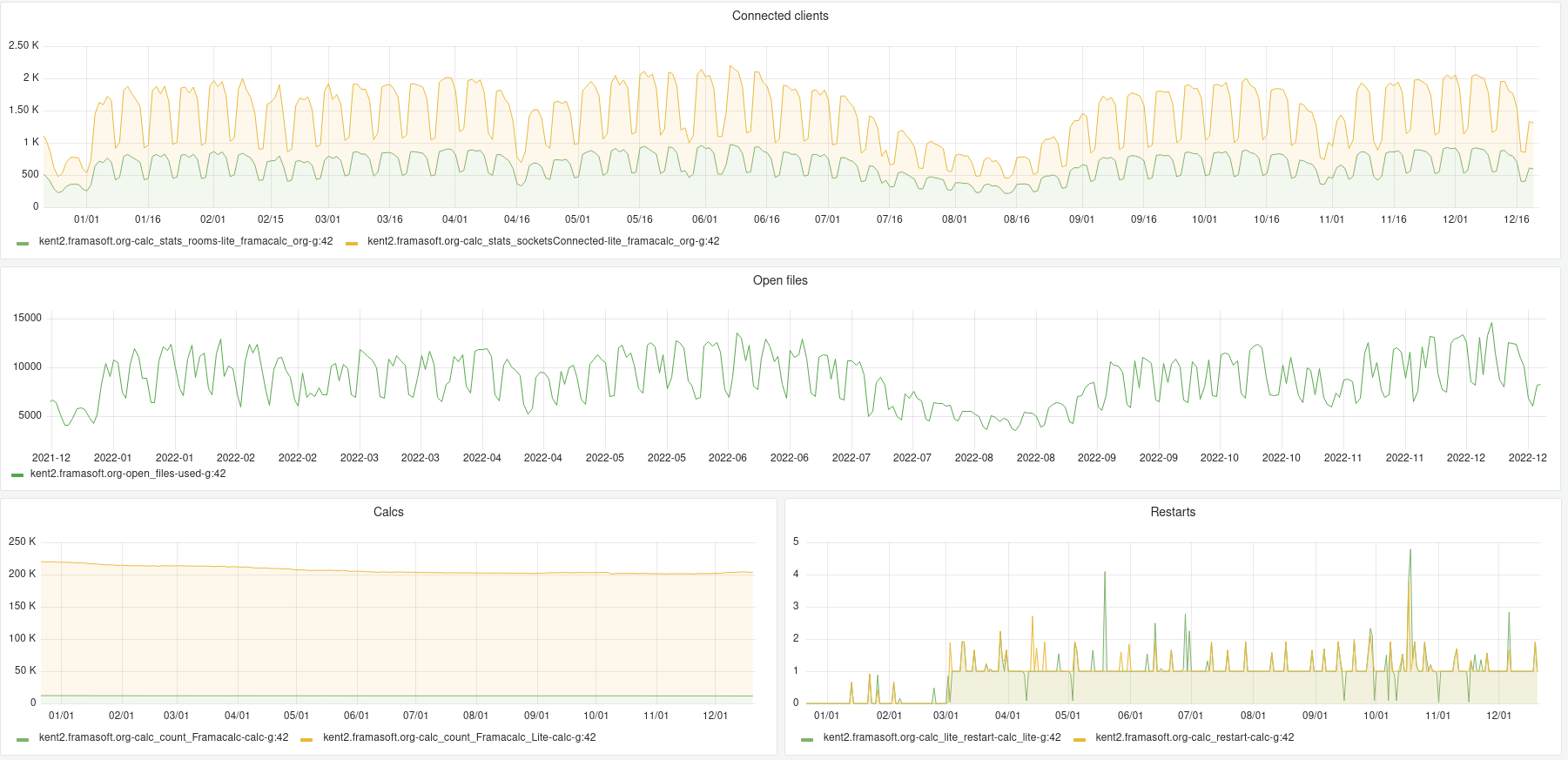
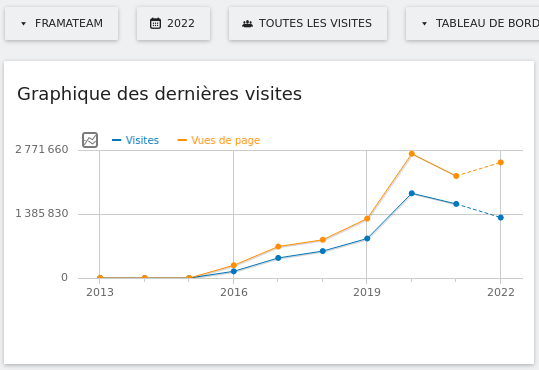
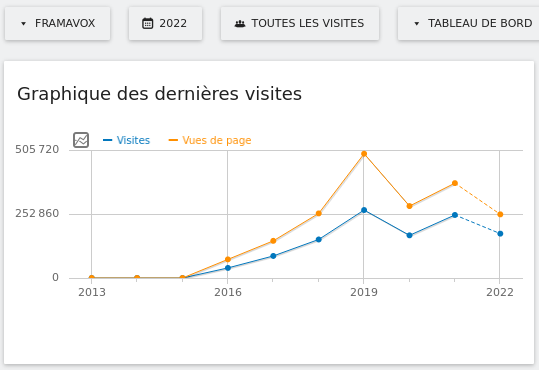
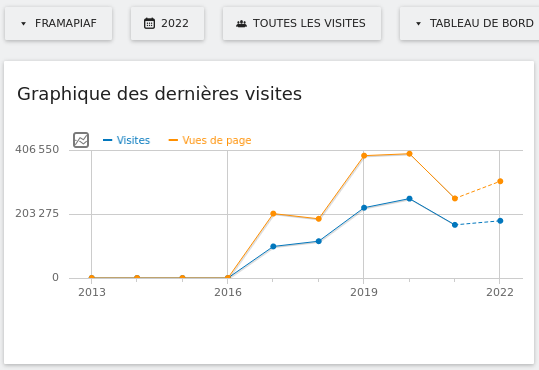
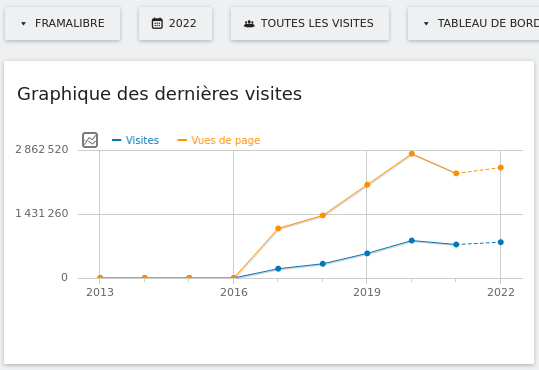
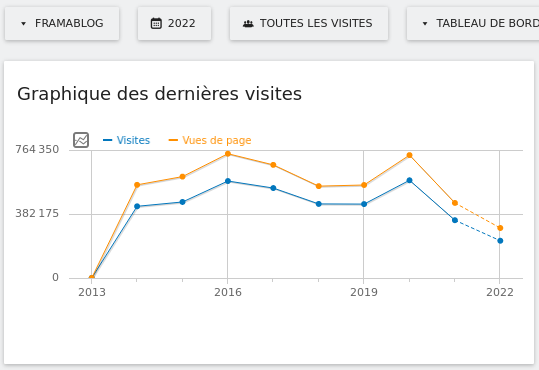
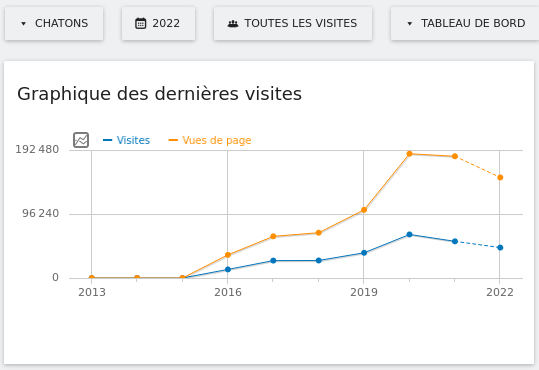
Nos services en ligne sont souvent la raison pour laquelle on nous connaît : vous êtes plus de 9 personnes sur 10 à nous l’avoir confié lors de notre enquête « Ce que vous pensez de Framasoft » lancée fin mai. Et à vrai dire, nous n’avons pas été très étonné⋅es. Pour vous donner quelques chiffres, nous comptons plus de 50 millions de visites sur l’ensemble de nos sites depuis le début d’année, plus de 350 sondages sont créés chaque jour sur Framadate, près de 15 000 formulaires sont créés chaque mois sur Framaforms, près de 110 000 pads d’écriture collaborative sont actifs sur Framapad. Nous, on trouve toujours ça incroyable !
Entre 2014 et 2019, notre petite association a mis à disposition des internautes une quarantaine de services en ligne libres et de confiance (oui, 40 !). Pour de nombreuses raisons, c’était trop, et nous avons fermé progressivement, entre 2019 et 2022, une partie de ces services, tout en proposant des alternatives. Cette période de fermetures est maintenant terminée : nos 16 services en ligne sont disponibles pour toute personne souhaitant utiliser des outils qui respectent nos libertés. Nous avons ainsi décidé de mettre à jour et refondre le site degooglisons-internet.org pour en faire une porte d’entrée facilement accessible, la mettre à notre image et surtout pour rassurer nos utilisateurs et utilisatrices.
Maintenir ces services à jour, gérer les machines qui les font tourner ou encore répondre à vos questions sur le support, c’est un travail du quotidien, et on essaye d’y mettre nos meilleures énergies !
PeerTube : libérer ses vidéos et ses chaînes est de plus en plus facile
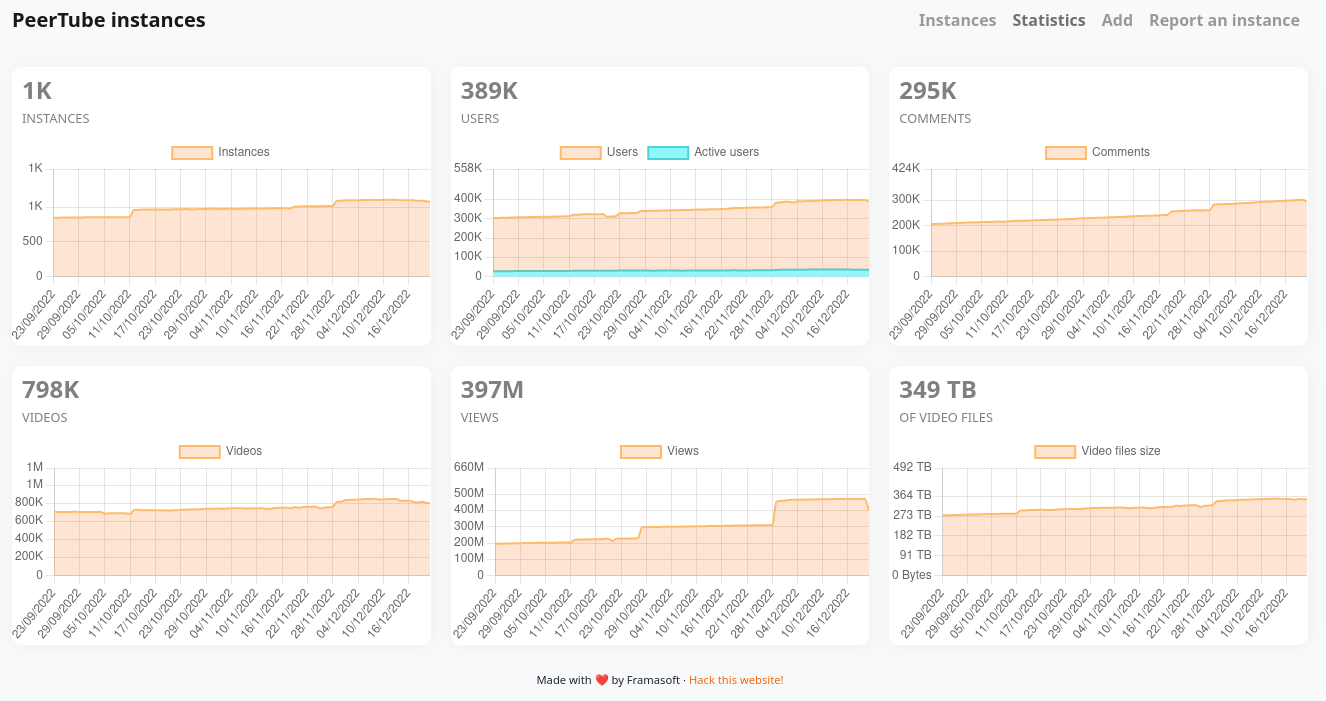
PeerTube, c’est le logiciel que nous développons (enfin, un de nos salarié⋅es, oui, un seul !) pour proposer une alternative aux plateformes vidéos. Et 2022 aura été une année bien riche en évolutions, où on compte maintenant plus de 1000 plateformes PeerTube actives.
Cap sur la V5 !
Pour commencer, la version 4.1 est sortie en février, apportant des améliorations de l’interface, de nouvelles fonctionnalités sur mobile, le système de plugins amélioré, de nouveaux filtres pour faire des recherches ou encore de nouvelles possibilités de personnalisation des instances pour les admins.
En juin, nous sortions la version 4.2, qui a amené une grande nouveauté : le Studio, ou la possibilité de modifier des vidéos directement depuis l’interface web. Cette version aura aussi apporté des statistiques de visionnage plus détaillées, la possibilité de régler la latence lors d’une diffusion ou encore l’édition directe de sous-titres (merci Lutangar !)
En septembre, c’est la version 4.3 qui a été publiée, permettant l’import automatique des vidéos d’une chaîne distante (Un grand merci à Florent, l’un des administrateurs de l’instance PeerTube Skeptikón) et de nouvelles améliorations de l’interface et de l’intégration des vidéos en direct (un travail en collaboration avec une designeuse de la Coopérative des Internets).
Et on peut déjà vous dire que la nouvelle version majeure, la v5, sera publiée dans quelques jours avec (attention : exclu !) de l’authentification à double facteur ou encore la possibilité d’envoyer les fichiers lives dans le cloud pour les admins…
Edit du 13 décembre : la V5 est sortie ! Retrouvez toutes les infos sur cet article.
Récolte de vos idées pour enrichir le logiciel
Vous créez du contenu sur PeerTube ? Vous aimez regarder des vidéos sur PeerTube ? En juillet, nous avons lancé l’outil ideas.joinpeertube.org (en anglais) pour récolter vos besoins sur le logiciel et ainsi nous permettre d’identifier les nouvelles fonctionnalités à développer pour rendre PeerTube plus agréable à utiliser.
N’hésitez pas à y faire un tour, pour voter pour une des fonctionnalités déjà proposées ou en proposer une nouvelle. Un grand merci à toutes celles et ceux qui ont pris le temps de partager leur avis !
joinpeertube.org : un accès facilité à PeerTube
joinpeertube.org, c’est LE site qui présente PeerTube, LA porte d’entrée pour s’informer sur cette alternative aux plateformes vidéo centralisatrices et nous, on souhaite la laisser grande ouverte !
La version précédente de joinpeertube.org était surtout axée sur les caractéristiques techniques de PeerTube, et donc adressée à des profils techniques. Hors, maintenant qu’il existe plus de 1 000 plateformes PeerTube, valoriser le logiciel auprès d’un public plus vaste et potentiellement moins à l’aise avec le numérique nous a paru une nouvelle orientation nécessaire.
Après un audit du site via des tests utilisateurs réalisés par La Coopérative des Internets, l’agence web nous a proposé des pistes d’amélioration pour permettre une meilleure compréhension de PeerTube. Vous trouverez tout le détail de cette version sur cet article du Framablog : et on espère que cette refonte vous sera utile et facilitera l’utilisation de PeerTube !
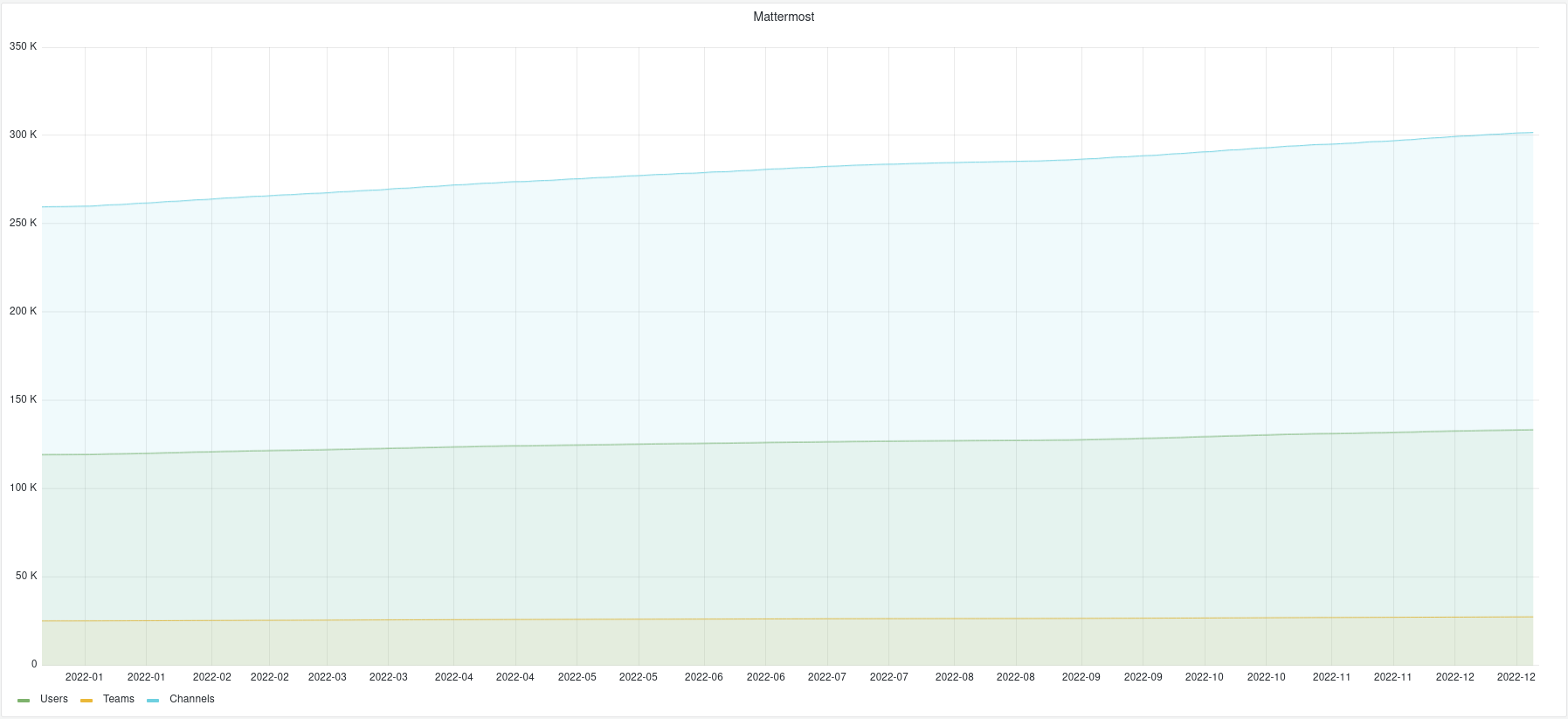
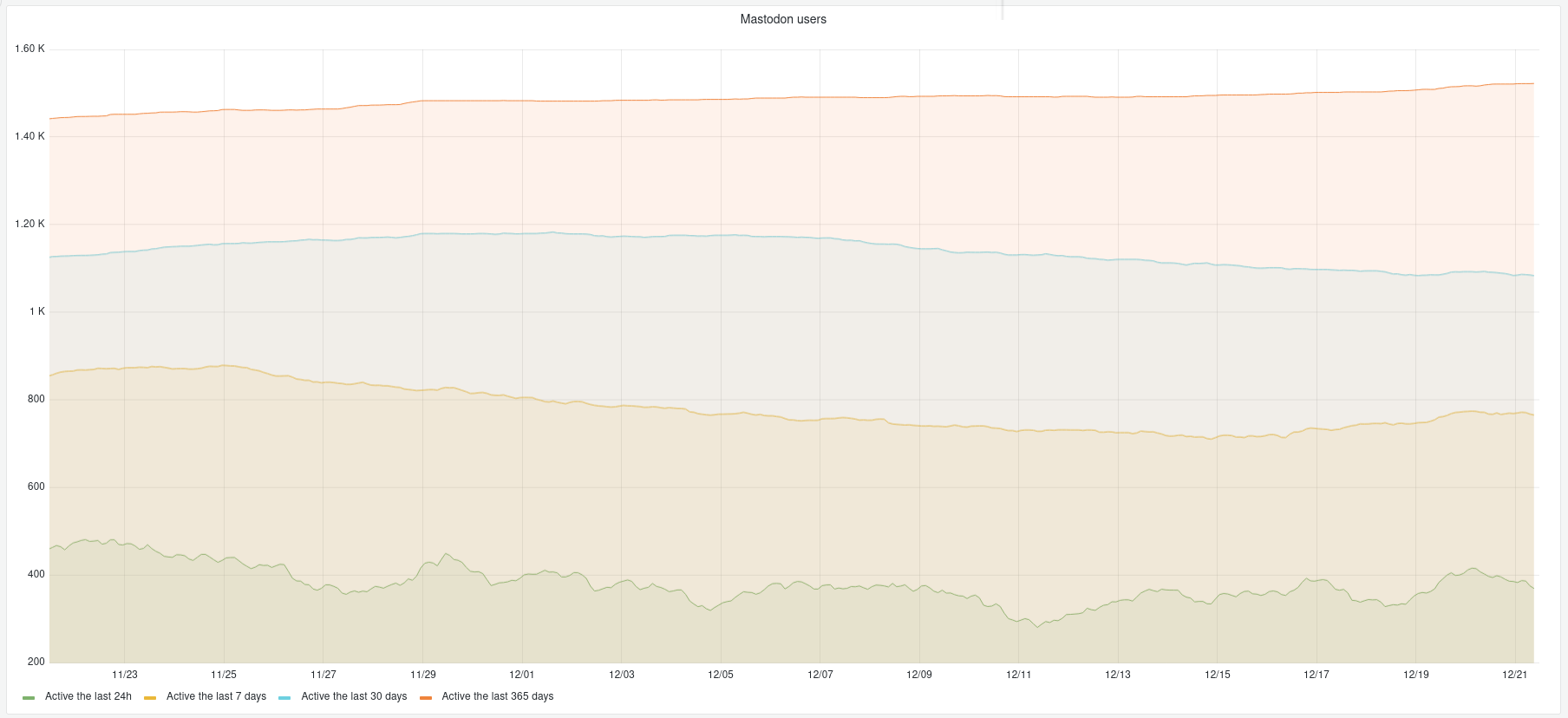
Mobilizon : on vous facilite les recherches
Mobilizon, c’est le logiciel que Framasoft développe (enfin, un de nos salarié⋅es et même pas à temps plein !) pour proposer une alternative aux événements et groupes Facebook.
Mobilizon Search Index, un moteur de recherche dans le fédiverse
Comme nous l’avons fait auparavant avec Sepia Search (notre moteur de recherche pour découvrir les contenus publiés sur PeerTube), nous souhaitons proposer une porte d’entrée vers Mobilizon pour montrer son potentiel émancipateur.
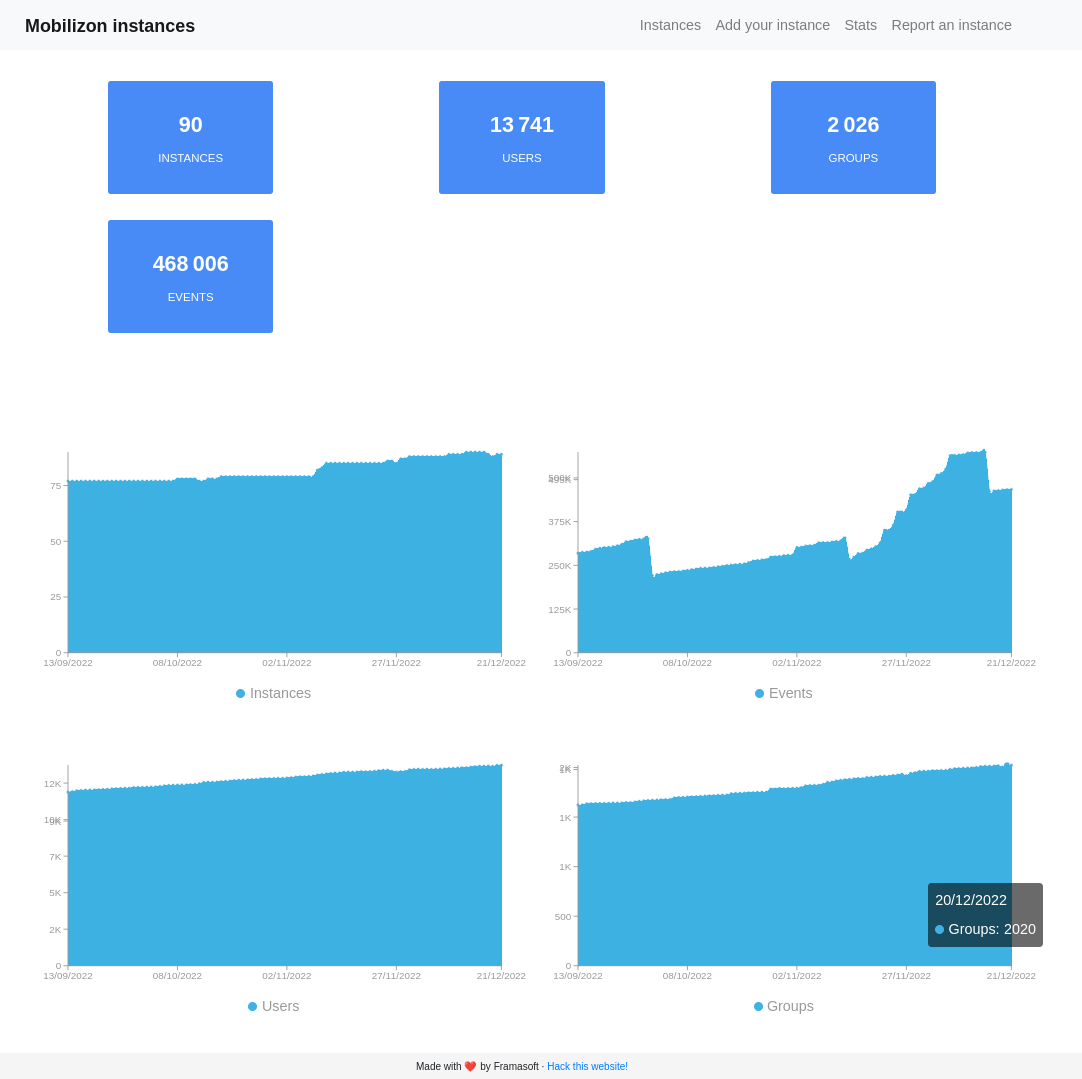
Mobilizon Search Index référence les événements et groupes de serveurs que nous avons approuvés sur instances.joinmobilizon.org (aujourd’hui un peu plus de 80 instances, et on espère que la liste s’allongera !). Le moteur de recherche permet ensuite d’explorer les événements et groupes de tous ces serveurs, et de différentes manières : barre de recherche (bon là c’est plutôt classique), par catégories (intéressant, non ?) ou même en se géolocalisant pour trouver des événements à proximité (c’est fou ça !).
Le code source est libre : toute personne (avec un certain bagage informatique tout de même… !) peut installer un Mobilizon Search Index, et l’adapter selon ses besoins.
Alors, ça vous donne envie de tester ?
Une v3 axée sur la recherche
Nous avons publié la 3ème version majeure de Mobilizon en novembre. Le logiciel a atteint la maturité que nous souhaitions lui donner, et ça, c’est très motivant !
Dans les nouveautés : de nombreux éléments du logiciel ont été modifiés pour ne pas accumuler de dette technique, le design de la page d’accueil a évolué dans le design, et la page de résultats de recherche a aussi été revue (coucou Mobilizon Search Index !). Augmenter les possibilités de découvrir des événements et des groupes pour rendre davantage visible la diversité des contenus publiés sur Mobilizon, c’était aussi l’objectif de cette v3.
Cette v3 a pu évoluer grâce aux différentes contributions (merci à la communauté !), a été financée en partie par une bourse de NLNet (merci à eux !), et bien sûr par vous, et vos dons (encore un grand merci).
Frama.space : émanciper les petites assos et collectifs militants
Frama.space, c’est un nouveau service que nous proposons aux petites associations et collectifs militants, pour leur permettre d’accorder leurs valeurs internes fortes (de justice sociale et d’émancipation) avec des outils numériques allant dans le même sens (outils libres et non monopolistiques). Nous souhaitons ainsi autonomiser les associations et collectifs militants en ouvrant des espaces numériques de partage, de travail et d’organisation (jusqu’à 50 comptes par collectif, basés sur le logiciel libre Nextcloud avec : suite bureautique, 40 Go de stockage, synchronisation d’agendas et de contacts, outils de visio, etc.).
Annoncées le 15 octobre lors de la sortie de notre feuille de route Collectivisons / Convivialisons Internet, les pré-inscriptions sont ouvertes depuis le 18 novembre. Actuellement, les candidatures sont révisées (par des vrai⋅es humain⋅es !) pour ouvrir 250 premiers espaces d’ici la fin d’année. Notre objectif final (un poil ambitieux, oui !) étant de mettre à disposition 10 000 espaces Frama.space d’ici fin 2025.
Vous voulez en lire plus sur la visée politique du projet ? Nous vous invitons à lire cet article ou à visionner cette conférence, apportant tous les détails importants.
Nos actions pour permettre aux citoyens et citoyennes de s’émanciper par le numérique vous semblent intéressantes ? Vous pensez que nous allons dans la bonne direction ? Tout cela a été possible aussi grâce à vous et grâce à vos dons. Merci !
Je soutiens les actions d’émancipation numérique de Framasoft
En dessert : farandole d’un monde meilleur (à partager !)
Parce qu’un bon repas est toujours meilleurs quand on le partage. Et parce que c’est en partageant nos savoirs-faire et savoirs-être que l’on avance plus loin. Nous agissons avec d’autres structures, qui, telles des îles indépendantes, baignent dans des eaux communes d’un même archipel (vous aussi vous imaginez des îles flottantes avec une bonne crème anglaise ?) : nous gardons notre indépendance tout en partageant des valeurs de justice sociale. Agir ensemble est évident !
Du côté des chatons
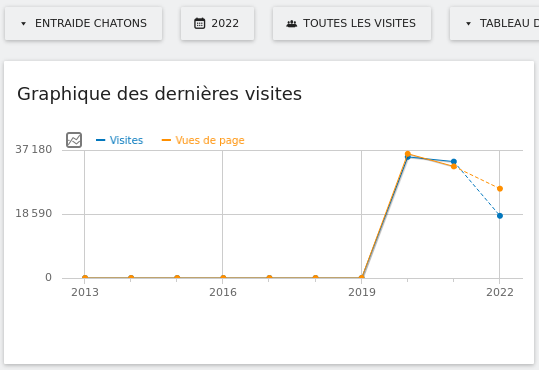
Le collectif CHATONS, c’est un peu comme un réseau d’AMAP du service en ligne. Là où Google, Facebook ou Microsoft représenteraient l’industrie agro-alimentaire, les membres de CHATONS seraient des paysans informatiques proposant des services en ligne bio sans OGM, sans pesticide, sans marketing agressif, bref : sans une « course au pouvoir d’achat ».
Cette fin d’année, après déjà 14 portées de chatons, nous comptons 97 membres au collectif, soit 97 hébergeurs alternatifs travaillant dans la même direction : résister à la gafamisation d’Internet et proposer des alternatives respectueuses de nos vies privées.
Le collectif a été présent sur différents événements durant l’année (Journées du Logiciel Libre, contrib’atelier sur l’accessibilité numérique, Geek Faeries, Freedom Not Fear, Fête de l’Huma, Capitole du Libre), pour présenter ses actions. Le deuxième camp CHATONS a eu lieu cet été, un temps fort pour se retrouver et relancer de belles dynamiques collectives. Différents groupes de travail ont vu le jour, notamment le groupe « Une asso pour le collectif CHATONS » visant une autonomisation du collectif dans le but que nous (Framasoft) laissions peu à peu la coordination du collectif au collectif lui-même.
Emancip’Asso : favoriser l’émancipation numérique du monde associatif
Le but d’Emancip’Asso, c’est d’aider les associations à trouver de l’accompagnement pour faire évoluer leurs pratiques numériques vers des pratiques plus éthiques. Conçu en partenariat avec Animafac, 2022 aura été une année de… paperasse (eh oui, c’est souvent ça le début de projets ambitieux !).
Nous avons passé un moment à constituer un comité de pilotage (20 membres) varié, hétérogène et , représentatif de la diversité du monde associatif. Ensuite, le projet se voulant indépendant financièrement, les 6 premiers mois de l’année ont été consacrés à de la recherche de financements, qui a porté ses fruits (hourra !). Nous comptons actuellement quatre financeurs (et on espère que la liste continuera à grandir !) : la Fondation Charles Léopold Mayer pour le progrès de l’Homme, la Fondation Crédit Coopératif, la Fondation Un monde par Tous et l’Association Libérons nos ordis.
Les premiers financements nous ont permis de travailler sur la première étape du projet : une formation à destination des hébergeurs éthiques pour les aider à accompagner des associations dans leur transition numérique. Recherche d’intervenant⋅es, préparation du programme et de la logistique : la formation (c’est complet !) aura lieu à Paris, du 16 au 20 janvier 2023 (le programme en détails est par ici).
Enfin, en cette fin d’année, nous avons postulé à différents programmes étudiants pour constituer deux groupes de travail : un premier sur l’identité graphique d’Émancip’Asso (c’est en cours !), et un second sur la réalisation du site internet emancipasso.org (à venir).
Vous pouvez retrouver Angie et Anne-Laure présentant le projet en vidéo par ici.
ECHO Network : comprendre les besoins numériques de l’éduc pop, ici et ailleurs
2022 aura aussi été l’année de l’élaboration du projet européen « Ethical, Commons, Humans, Open-Source Network » (Réseau autour de l’Éthique, les Communs, les Humaines et l’Open-source) (ECHO Network, c’est un peu plus facile à mémoriser…). Mené par le mouvement d’éducation populaire des CEMÉA France, le projet rassemble 7 structures de 5 pays d’Europe (France, Belgique, Croatie, Allemagne, Italie). Leur point commun ? L’accompagnement, chacune à son niveau, des publics dans leur autonomie et leur émancipation.
L’objectif du projet est d’échanger sur les difficultés, les opportunités et les façons d’accompagner vers une transition numérique des publics que nos associations servent. Et la toile de fond : comment accompagner cette émancipation dans (voire par) un monde numérique centralisé chez les géants du web ?
La première rencontre de l’échange aura lieu à Paris du 14 au 17 janvier 2023. Ce séminaire d’ouverture va nous permettre de déblayer la thématique générale : accompagner la transition numérique des associations formant des citoyens et citoyennes. En savoir plus par ici.
Et ce n’est pas tout !
Transmission de connaissances
Avec Hubikoop (hub territorial de la région Nouvelle Aquitaine pour un numérique inclusif) nous avons débuté en septembre l’animation du parcours « Accompagnement à la découverte de services numériques éthiques » : 8 ateliers pour les acteurs et actrices de la médiation numérique en Nouvelle Aquitaine. Ce partenariat commence à faire émerger de nouvelles idées, que l’on vous racontera l’année prochaine !
Dans le cadre du projet PENSA avec l’Aix-Marseille Université, nous sommes intervenu⋅es en juin pour une formation de formateurs et formatrices sur la thématique « Logiciels et services libres pour l’émancipation numérique des citoyennes ». L’objectif final est de permettre aux enseignant⋅es de développer leurs compétences pour une utilisation critique du numérique en éducation.
Nous avons aussi mené diverses actions en lien avec l’AFPA et plus spécifiquement les personnes en charge de la formation des Responsables d’Espace de Médiation Numérique, pour transmettre davantage de connaissances sur le numérique éthique.
Framasoft est aussi entrée au sociétariat de la MedNum. Nos ambitions derrière ça ? Sensibiliser les acteurs de la médiation numérique aux outils libres, former les médiateurs numériques aux alternatives éthiques et outiller la coopérative elle-même d’outils libres.
Vous nous retrouverez enfin dans le livret « Le temps des conquêtes, les nouveaux horizons de l’ESS » publié par ESS France.
Des prises de positions importantes
L.A. Coalition (dont Framasoft est membre) s’est positionnée en avril sur le contrat d’engagement républicain : le collectif dénonce une source potentielle de litiges et de sanctions abusives de la part de l’administration ou des collectivités publiques au détriment des associations et fondations.
Les premières dérives du contrat d’engagement républicain ont rapidement vu le jour. Nous avons signé la tribune « La désobéissance civile relève de la liberté d’expression et du répertoire d’actions légitimes des associations », publiée dans l’Humanité en septembre : les libertés associatives sont essentielles et actuellement en danger.
Nous avons aussi signé la tribune « Pour que les communs numériques deviennent un pilier de la souveraineté numérique européenne » de Wikimédia France en juin. Les communs culturels font partie intégrante de l’objet social de Framasoft, les défendre est primordial !
Soutiens par convictions
Suite à l’annonce de sa situation financière très difficile cet été, nous avons soutenu le média NextINpact (veille numérique très qualitative) en achetant des abonnements « suspendus » que nous avons tirés au sort.
Nous avons aussi soutenu affordance.info (contenus qualitatifs sur le numérique et réflexions pertinentes de société) en migrant son blog d’un outil non libre (Typepad) à un outil libre (WordPress), le tout hébergé par nos soins.
Nous avons proposé un proxy Signal (messagerie libre) suite à un appel de la structure informant du blocage de son application par le régime iranien face aux révoltes actuelles.
Notre dessert partagé vous a plu ? Vous pensez que ces actions réalisées avec d’autres îles de notre archipel sont à encourager ? Sachez qu’elles aussi sont uniquement réalisables grâce à vous et à vos dons. Encore un grand merci !
Je soutiens les actions d’archipélisation de Framasoft

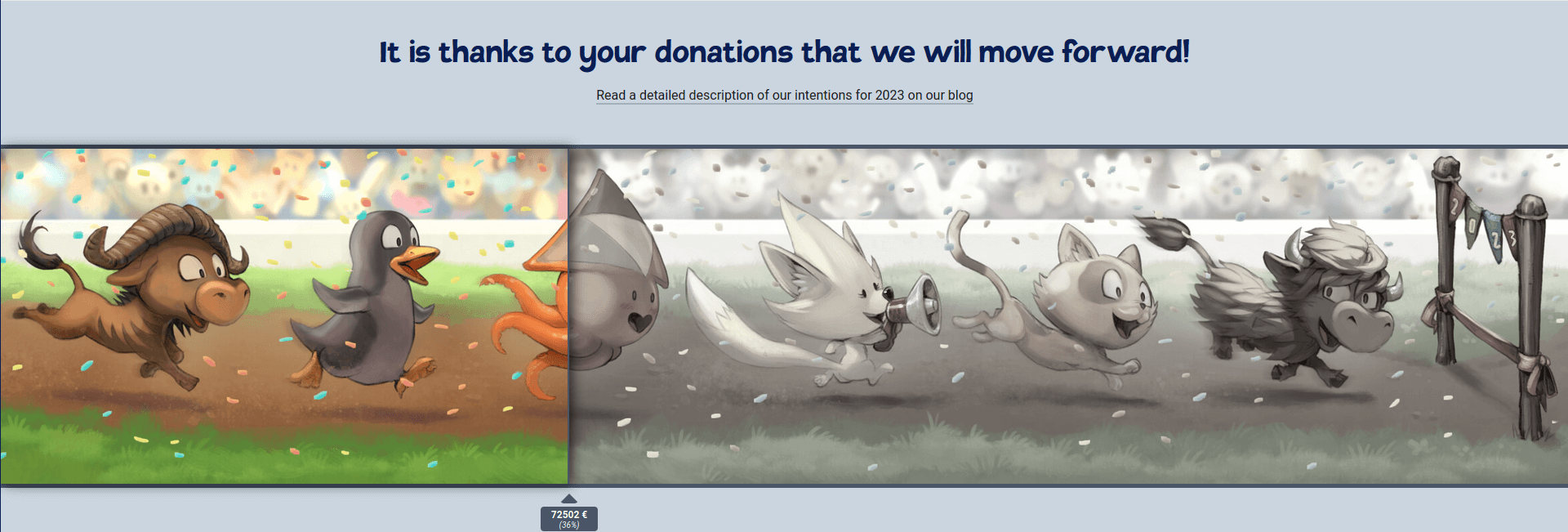
Framasoft, aujourd’hui, c’est plus de 50 000 € de dépenses par mois. Nous avons clos l’exercice comptable 2021 avec un déficit de 60 000 € (que des dons – plus généreux lors des confiprouts de 2020 – nous ont, heureusement, permis d’absorber).
À l’heure où nous publions ces lignes, nous estimons qu’il nous manque 133 000 € pour boucler notre budget annuel et nous lancer sereinement dans nos actions en 2023.
Si vous le pouvez (eh oui, en ce moment c’est particulièrement compliqué), et si vous le voulez, merci de soutenir les actions de notre association.
Je soutiens les actions de Framasoft
 Je m’appelle Leah et je suis autrice de bandes dessinées et artiste. J’ai une formation en art et en communication, et je n’ai jamais travaillé dans l’industrie technologique.
Je m’appelle Leah et je suis autrice de bandes dessinées et artiste. J’ai une formation en art et en communication, et je n’ai jamais travaillé dans l’industrie technologique.






























{kind=link}
{kind=link}